
個人讀書筆記,詳情參考《MySQL技術內幕 Innodb存儲引擎》 1,checkpoint產生的背景資料庫在發生增刪查改操作的時候,都是先在buffer pool中完成的,為了提高事物操作的效率,buffer pool中修改之後的數據,並沒有立即寫入到磁碟,這有可能會導致記憶體中數據與磁碟中的數據產 ...
個人讀書筆記,詳情參考《MySQL技術內幕 Innodb存儲引擎》
1,checkpoint產生的背景
資料庫在發生增刪查改操作的時候,都是先在buffer pool中完成的,為了提高事物操作的效率,buffer pool中修改之後的數據,並沒有立即寫入到磁碟,這有可能會導致記憶體中數據與磁碟中的數據產生不一致的情況。
事物要求之一是持久性(Durability),buffer pool與磁碟數據的不一致性的情況下發生故障,可能會導致數據無法持久化。
為了防止在記憶體中修改但尚未寫入到磁碟的數據,在發生故障重啟數據之後產生事物未持久化的情況,是通過日誌(redo log)先行的方式來保證的。
redo log可以在故障重啟之後實現“重做”,保證了事物的持久化的特性,但是redo log空間不可能無限制擴大,對於記憶體中已修改但尚未提交到磁碟的數據,也即臟頁,也需要寫入磁碟。
對於記憶體中的臟頁,什麼時候,什麼情況下,將多少臟頁寫入磁碟,是由多方面因素決定的。
checkpoint的工作之一,就是對於記憶體中的臟頁,在一定條件下將臟頁刷新到磁碟。
2,checkpoint的分類
按照checkpoint刷新的方式,MySQL中的checkpoint分為兩種,也即sharp checkpoint和fuzzy checkpoint。
sharp checkpoint:在關閉資料庫的時候,將buffer pool中的臟頁全部刷新到磁碟中。
fuzzy checkpoint:資料庫正常運行時,在不同的時機,將部分臟頁寫入磁碟,進刷新部分臟頁到磁碟,也是為了避免一次刷新全部的臟頁造成的性能問題。
3 ,checkpoint發生的時機
checkpoint都是將buffer pool中的臟頁刷新到磁碟,但是在不同的情況下,checkpoint會被以不同的方式觸發,同時寫入到磁碟的臟頁的數量也不同。
3.1, Master Thread checkpoint
在Master Thread中,會以每秒或者每10秒一次的頻率,將部分臟頁從記憶體中刷新到磁碟,這個過程是非同步的。正常的用戶線程對數據的操作不會被阻塞。
3.2 ,FLUSH_LRU_LIST checkpoint
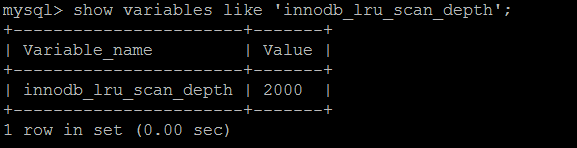
MySQL對緩存的管理是通過buffer pool中的LRU列表實現的,LRU 空閑列表中要保留一定數量的空閑頁面,來保證buffer pool中有足夠的空閑頁面來相應外界對資料庫的請求。
當這個空間頁面數量不足的時候,發生FLUSH_LRU_LIST checkpoint,FLUSH_LRU_LIST checkpoint是在單獨的page cleaner線程中執行的。
空閑頁的數量由innodb_lru_scan_depth參數表來控制的,因此在空閑列表頁面數量少於配置的值的時候,會發生checkpoint,剔除部分LRU列表尾端的頁面。
3.3 ,Async/Sync Flush checkpoint
Async/Sync Flush checkpoint 發生在重做日誌不可用的時候,將buffer pool中的一部分臟頁刷新到磁碟中,在臟頁寫入磁碟之後,事物對應的重做日誌也就可以釋放了。
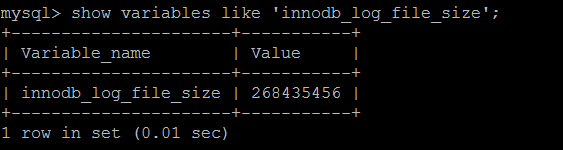
關於redo_log文件的的大小,可以通過innodb_log_file_size來配置。
對於是執行Async Flush checkpoint還是Sync Flush checkpoint,由checkpoint_age以及async_water_mark和sync_water_mark來決定。
定義:
checkpoint_age = redo_lsn-checkpoint_lsn,也即checkpoint_age等於最新的lsn減去已經刷新到磁碟的lsn的值
async_water_mark = 75%*innodb_log_file_size
sync_water_mark = 90%*innodb_log_file_size
1)當checkpoint_age<sync_water_mark的時候,無需執行Flush checkpoint。也就說,redo log剩餘空間超過25%的時候,無需執行Async/Sync Flush checkpoint。
2)當async_water_mark<checkpoint_age<sync_water_mark的時候,執行Async Flush checkpoint,也就說,redo log剩餘空間不足25%,但是大於10%的時候,執行Async Flush checkpoint,刷新到滿足條件1
3)當checkpoint_age>sync_water_mark的時候,執行sync Flush checkpoint。也就說,redo log剩餘空間不足10%的時候,執行Sync Flush checkpoint,刷新到滿足條件1。
在mysql 5.6之後,不管是Async Flush checkpoint還是Sync Flush checkpoint,都不會阻塞用戶的查詢進程。
個人認為:
由於磁碟是一種相對較慢的存儲設備,記憶體與磁碟的交互是一個相對較慢的過程
由於innodb_log_file_size定義的是一個相對較大的值,正常情況下,由前面兩種checkpoint刷新臟頁到磁碟,在前面兩種checkpoint刷新臟頁到磁碟之後,臟頁對應的redo log空間隨即釋放,一般不會發生Async/Sync Flush checkpoint。同時也要意識到,為了避免頻繁低發生Async/Sync Flush checkpoint,也應該將innodb_log_file_size配置的相對較大一些。
3.4, Dirty Page too much Checkpoint
Dirty Page too much 意味著buffer pool中的臟頁過多,執行checkpoint臟頁刷入磁碟,保證buffer pool中有足夠的可用頁面。
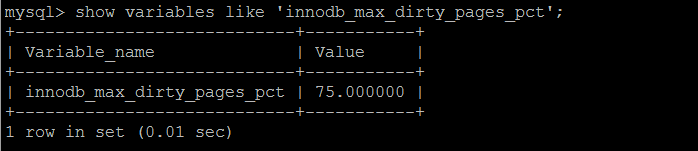
Dirty Page 由innodb_max_dirty_pages_pct配置,innodb_max_dirty_pages_pct的預設值在innodb 1.0之前是90%,之後是75%。
總結:
MySQL資料庫(當然其他關係數據也有類似的機制),為了提高事物操作的效率,在事物提交之後並不會立即將修改後的數據寫入磁碟,而是通過日誌先行(write log ahead)的方式保證事物的持久性。
對於將事物修改的數據頁面,也即臟頁,通過非同步的方式刷新到磁碟中,checkpoint正是實現這種非同步刷新臟頁到磁碟的實施者。
不同的情況下,會發生不同的checkpoint,將不同數量的臟頁刷新到磁碟,從而到達管理記憶體(第1,2,4種checkpoint)和redo log可用空間(第3種checkpoint)的目的。


