
這篇文章我們開始分析LinkedHashMap的源碼,LinkedHashMap繼承了HashMap,也就是說LinkedHashMap是在HashMap的基礎上擴展而來的,因此在看LinkedHashMap源碼之前,讀者有必要先去瞭解HashMap的源碼,可以查看我上一篇文章的介紹《Java集合系 ...
這篇文章我們開始分析LinkedHashMap的源碼,LinkedHashMap繼承了HashMap,也就是說LinkedHashMap是在HashMap的基礎上擴展而來的,因此在看LinkedHashMap源碼之前,讀者有必要先去瞭解HashMap的源碼,可以查看我上一篇文章的介紹《Java集合系列[3]----HashMap源碼分析》。只要深入理解了HashMap的實現原理,回過頭來再去看LinkedHashMap,HashSet和LinkedHashSet的源碼那都是非常簡單的。因此,讀者們好好耐下性子來研究研究HashMap源碼吧,這可是買一送三的好生意啊。在前面分析HashMap源碼時,我採用以問題為導向對源碼進行分析,這樣使自己不會像無頭蒼蠅一樣亂分析一通,讀者也能夠針對問題更加深入的理解。本篇我決定還是採用這樣的方式對LinkedHashMap進行分析。
1. LinkedHashMap內部採用了什麼樣的結構?
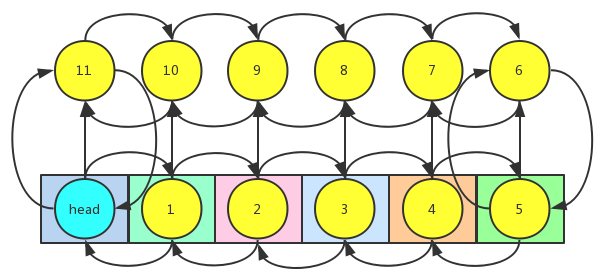
可以看到,由於LinkedHashMap是繼承自HashMap的,所以LinkedHashMap內部也還是一個哈希表,只不過LinkedHashMap重新寫了一個Entry,在原來HashMap的Entry上添加了兩個成員變數,分別是前繼結點引用和後繼結點引用。這樣就將所有的結點鏈接在了一起,構成了一個雙向鏈表,在獲取元素的時候就直接遍歷這個雙向鏈表就行了。我們看看LinkedHashMap實現的Entry是什麼樣子的。
1 private static class Entry<K,V> extends HashMap.Entry<K,V> { 2 //當前結點在雙向鏈表中的前繼結點的引用 3 Entry<K,V> before; 4 //當前結點在雙向鏈表中的後繼結點的引用 5 Entry<K,V> after; 6 7 Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { 8 super(hash, key, value, next); 9 } 10 11 //從雙向鏈表中移除該結點 12 private void remove() { 13 before.after = after; 14 after.before = before; 15 } 16 17 //將當前結點插入到雙向鏈表中一個已存在的結點前面 18 private void addBefore(Entry<K,V> existingEntry) { 19 //當前結點的下一個結點的引用指向給定結點 20 after = existingEntry; 21 //當前結點的上一個結點的引用指向給定結點的上一個結點 22 before = existingEntry.before; 23 //給定結點的上一個結點的下一個結點的引用指向當前結點 24 before.after = this; 25 //給定結點的上一個結點的引用指向當前結點 26 after.before = this; 27 } 28 29 //按訪問順序排序時, 記錄每次獲取的操作 30 void recordAccess(HashMap<K,V> m) { 31 LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; 32 //如果是按訪問順序排序 33 if (lm.accessOrder) { 34 lm.modCount++; 35 //先將自己從雙向鏈表中移除 36 remove(); 37 //將自己放到雙向鏈表尾部 38 addBefore(lm.header); 39 } 40 } 41 42 void recordRemoval(HashMap<K,V> m) { 43 remove(); 44 } 45 }
2. LinkedHashMap是怎樣實現按插入順序排序的?
1 //父類put方法中會調用的該方法 2 void addEntry(int hash, K key, V value, int bucketIndex) { 3 //調用父類的addEntry方法 4 super.addEntry(hash, key, value, bucketIndex); 5 //下麵操作是方便LRU緩存的實現, 如果緩存容量不足, 就移除最老的元素 6 Entry<K,V> eldest = header.after; 7 if (removeEldestEntry(eldest)) { 8 removeEntryForKey(eldest.key); 9 } 10 } 11 12 //父類的addEntry方法中會調用該方法 13 void createEntry(int hash, K key, V value, int bucketIndex) { 14 //先獲取HashMap的Entry 15 HashMap.Entry<K,V> old = table[bucketIndex]; 16 //包裝成LinkedHashMap自身的Entry 17 Entry<K,V> e = new Entry<>(hash, key, value, old); 18 table[bucketIndex] = e; 19 //將當前結點插入到雙向鏈表的尾部 20 e.addBefore(header); 21 size++; 22 }
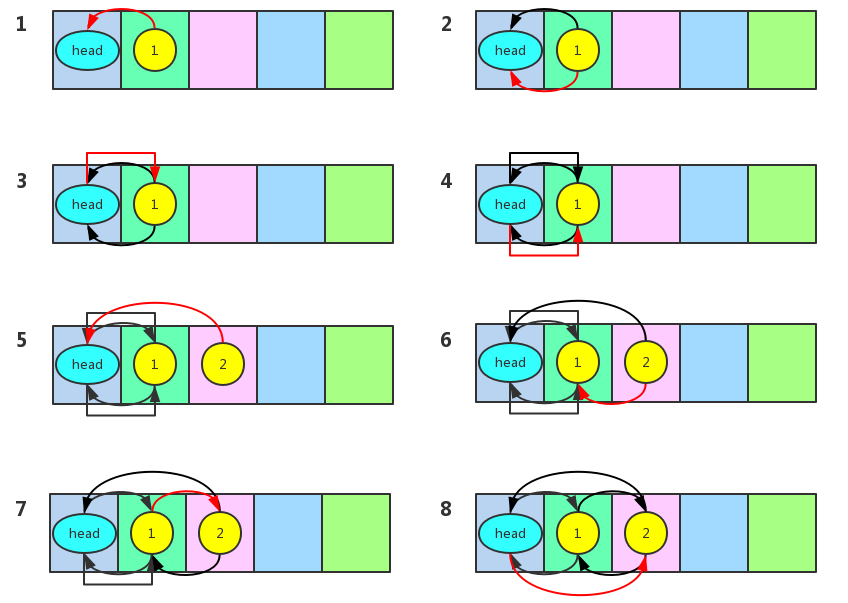
LinkedHashMap重寫了它的父類HashMap的addEntry和createEntry方法。當要插入一個鍵值對的時候,首先會調用它的父類HashMap的put方法。在put方法中會去檢查一下哈希表中是不是存在了對應的key,如果存在了就直接替換它的value就行了,如果不存在就調用addEntry方法去新建一個Entry。註意,這時候就調用到了LinkedHashMap自己的addEntry方法。我們看到上面的代碼,這個addEntry方法除了回調父類的addEntry方法之外還會調用removeEldestEntry去移除最老的元素,這步操作主要是為了實現LRU演算法,下麵會講到。我們看到LinkedHashMap還重寫了createEntry方法,當要新建一個Entry的時候最終會調用這個方法,createEntry方法在每次將Entry放入到哈希表之後,就會調用addBefore方法將當前結點插入到雙向鏈表的尾部。這樣雙向鏈表就記錄了每次插入的結點的順序,獲取元素的時候只要遍歷這個雙向鏈表就行了,下圖演示了每次調用addBefore的操作。由於是雙向鏈表,所以將當前結點插入到頭結點之前其實就是將當前結點插入到雙向鏈表的尾部。
3. 怎樣利用LinkedHashMap實現LRU緩存?
我們知道緩存的實現依賴於電腦的記憶體,而記憶體資源是相當有限的,不可能無限制的存放元素,所以我們需要在容量不夠的時候適當的刪除一些元素,那麼到底刪除哪個元素好呢?LRU演算法的思想是,如果一個數據最近被訪問過,那麼將來被訪問的幾率也更高。所以我們可以刪除那些不經常被訪問的數據。接下來我們看看LinkedHashMap內部是怎樣實現LRU機制的。
1 public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> { 2 //雙向鏈表頭結點 3 private transient Entry<K,V> header; 4 //是否按訪問順序排序 5 private final boolean accessOrder; 6 ... 7 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { 8 super(initialCapacity, loadFactor); 9 this.accessOrder = accessOrder; 10 } 11 //根據key獲取value值 12 public V get(Object key) { 13 //調用父類方法獲取key對應的Entry 14 Entry<K,V> e = (Entry<K,V>)getEntry(key); 15 if (e == null) { 16 return null; 17 } 18 //如果是按訪問順序排序的話, 會將每次使用後的結點放到雙向鏈表的尾部 19 e.recordAccess(this); 20 return e.value; 21 } 22 private static class Entry<K,V> extends HashMap.Entry<K,V> { 23 ... 24 //將當前結點插入到雙向鏈表中一個已存在的結點前面 25 private void addBefore(Entry<K,V> existingEntry) { 26 //當前結點的下一個結點的引用指向給定結點 27 after = existingEntry; 28 //當前結點的上一個結點的引用指向給定結點的上一個結點 29 before = existingEntry.before; 30 //給定結點的上一個結點的下一個結點的引用指向當前結點 31 before.after = this; 32 //給定結點的上一個結點的引用指向當前結點 33 after.before = this; 34 } 35 //按訪問順序排序時, 記錄每次獲取的操作 36 void recordAccess(HashMap<K,V> m) { 37 LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; 38 //如果是按訪問順序排序 39 if (lm.accessOrder) { 40 lm.modCount++; 41 //先將自己從雙向鏈表中移除 42 remove(); 43 //將自己放到雙向鏈表尾部 44 addBefore(lm.header); 45 } 46 } 47 ... 48 } 49 //父類put方法中會調用的該方法 50 void addEntry(int hash, K key, V value, int bucketIndex) { 51 //調用父類的addEntry方法 52 super.addEntry(hash, key, value, bucketIndex); 53 //下麵操作是方便LRU緩存的實現, 如果緩存容量不足, 就移除最老的元素 54 Entry<K,V> eldest = header.after; 55 if (removeEldestEntry(eldest)) { 56 removeEntryForKey(eldest.key); 57 } 58 } 59 //是否刪除最老的元素, 該方法設計成要被子類覆蓋 60 protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { 61 return false; 62 } 63 }
為了更加直觀,上面貼出的代碼中我將一些無關的代碼省略了,我們可以看到LinkedHashMap有一個成員變數accessOrder,該成員變數記錄了是否需要按訪問順序排序,它提供了一個構造器可以自己指定accessOrder的值。每次調用get方法獲取元素式都會調用e.recordAccess(this),該方法會將當前結點移到雙向鏈表的尾部。現在我們知道瞭如果accessOrder為true那麼每次get元素後都會把這個元素挪到雙向鏈表的尾部。這一步的目的是區別出最常使用的元素和不常使用的元素,經常使用的元素放到尾部,不常使用的元素放到頭部。我們再回到上面的代碼中看到每次調用addEntry方法時都會判斷是否需要刪除最老的元素。判斷的邏輯是removeEldestEntry實現的,該方法被設計成由子類進行覆蓋並重寫裡面的邏輯。註意,由於最近被訪問的結點都被挪動到雙向鏈表的尾部,所以這裡是從雙向鏈表頭部取出最老的結點進行刪除。下麵例子實現了一個簡單的LRU緩存。
1 public class LRUMap<K, V> extends LinkedHashMap<K, V> { 2 3 private int capacity; 4 5 LRUMap(int capacity) { 6 //調用父類構造器, 設置為按訪問順序排序 7 super(capacity, 1f, true); 8 this.capacity = capacity; 9 } 10 11 @Override 12 public boolean removeEldestEntry(Map.Entry<K, V> eldest) { 13 //當鍵值對大於等於哈希表容量時 14 return this.size() >= capacity; 15 } 16 17 public static void main(String[] args) { 18 LRUMap<Integer, String> map = new LRUMap<Integer, String>(4); 19 map.put(1, "a"); 20 map.put(2, "b"); 21 map.put(3, "c"); 22 System.out.println("原始集合:" + map); 23 String s = map.get(2); 24 System.out.println("獲取元素:" + map); 25 map.put(4, "d"); 26 System.out.println("插入之後:" + map); 27 } 28 29 }
結果如下:

註:以上全部分析基於JDK1.7,不同版本間會有差異,讀者需要註意

