
Spark Streaming處於Spark生態技術棧中,可以和Spark Core和Spark SQL無縫整合;而Storm相對來說比較單一; (一)概述 Spark Streaming Spark Streaming是Spark的核心API的一個擴展,可以實現高吞吐量、具有容錯機制的實時流數據的 ...
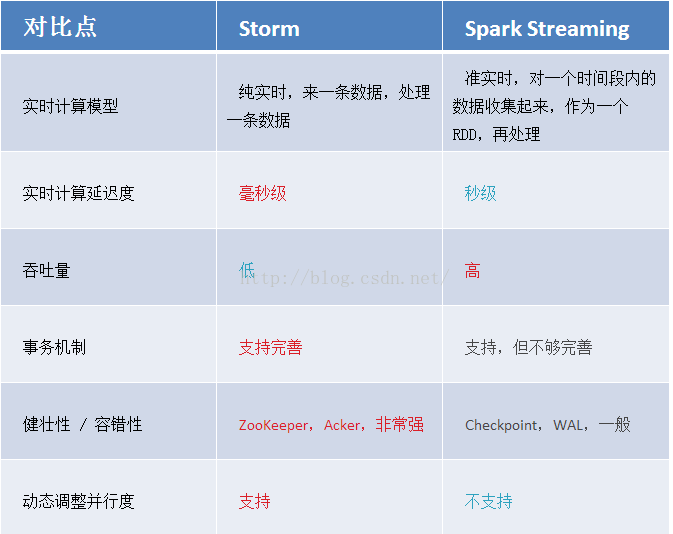
Spark Streaming處於Spark生態技術棧中,可以和Spark Core和Spark SQL無縫整合;而Storm相對來說比較單一;
(一)概述
- Spark Streaming
Spark Streaming是Spark的核心API的一個擴展,可以實現高吞吐量、具有容錯機制的實時流數據的處理。支持從多種數據源獲取數據,包括kafka、Flume、Twitter、ZeroMQ以及TCP等,從數據獲取之後,可以使用諸如map、reduce、join、window等高級函數進行複雜演算法處理。最後還可以將處理結果存儲到文件系統,資料庫;還可以使用Spark的其他子框架,如圖計算等,對流數據進行處理。
Spark Streaming在內部的處理機制是,就收實時流的數據,並根據一定的時間間隔拆分成一批批的數據,然後處理這些批數據,最終得到處理後的一批結果數據。對應的批數據(batch data),在Spark內核對應一個RDD實例,因此,對流數據DStream可以看成是一組RDDs。
執行流程(Receiver模式):
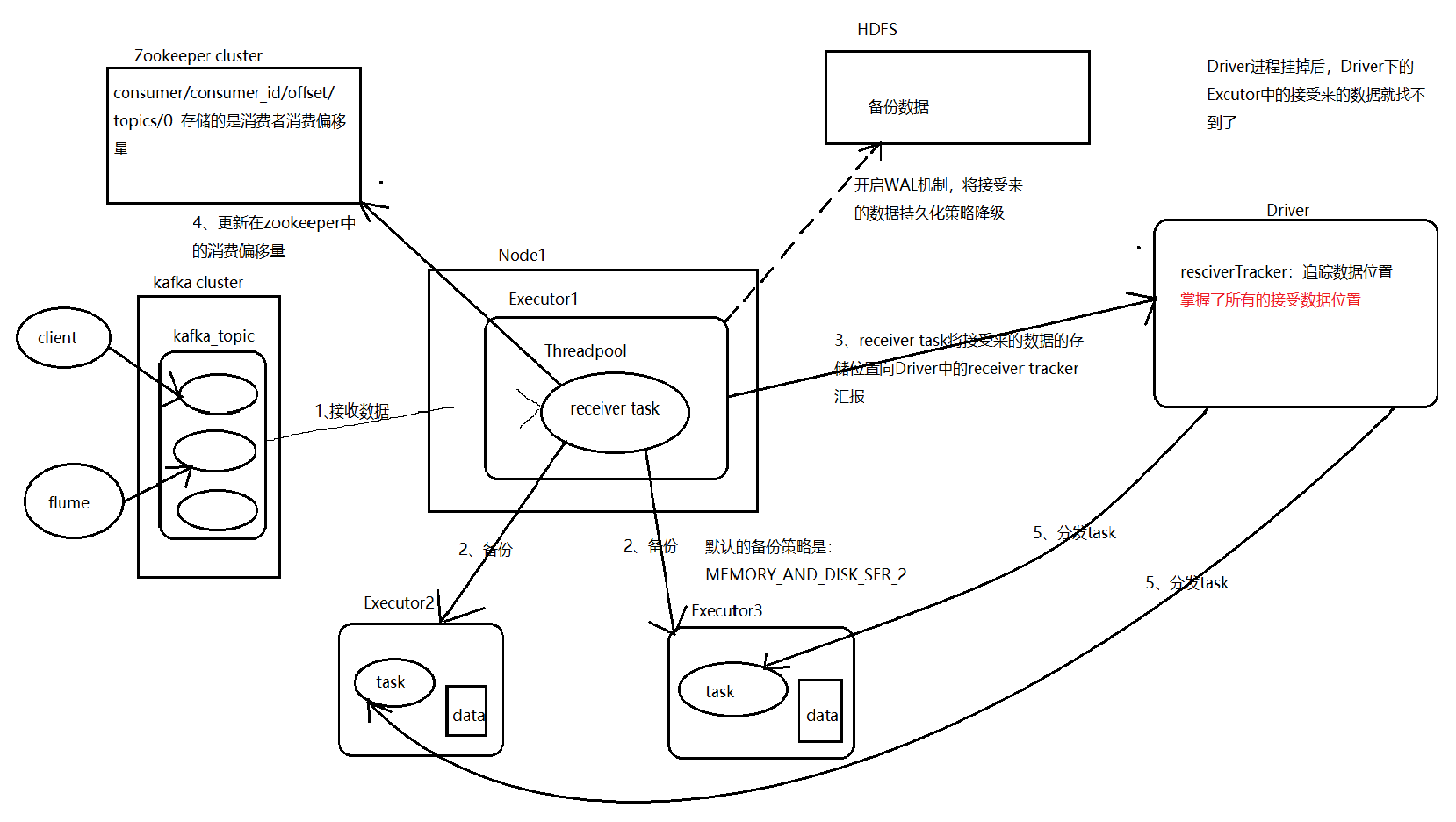
提高並行度:receiver task會每隔200ms block.interval將接受來的數據分裝到block中,調整block.interval的值;
啟用多個receiver進程來並行接受數據;
對於Direct模式提高並行度的方式只需增加kafka partition的數量;Director模式,消費者偏移量由spark自己管理,存在checkpoint目錄中
- Storm
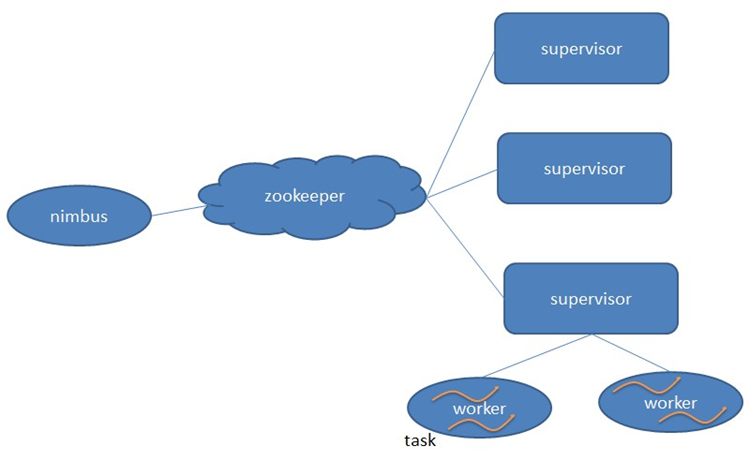
storm採用Master/Slave體繫結構
nimbus:該進程運行在集群的主節點上,負責任務的指派和分發
supervisor:運行在集群的從節點上,負責執行任務的具體部分
zookeeper:幫助主從做到解耦,存儲集群資源元數據,當storm把元數據信息都存到zk中後,那storm自己就做到了無狀態,提交Topology應用的時候才會用到nimbus;
worker:運行處理具體組件邏輯進程,worker之間通過netty傳送數據
task:worker中每個spout/bolt的線程稱為一個task,同一個spout/bolt的task可能會共用一個物理進程,該線程為executor
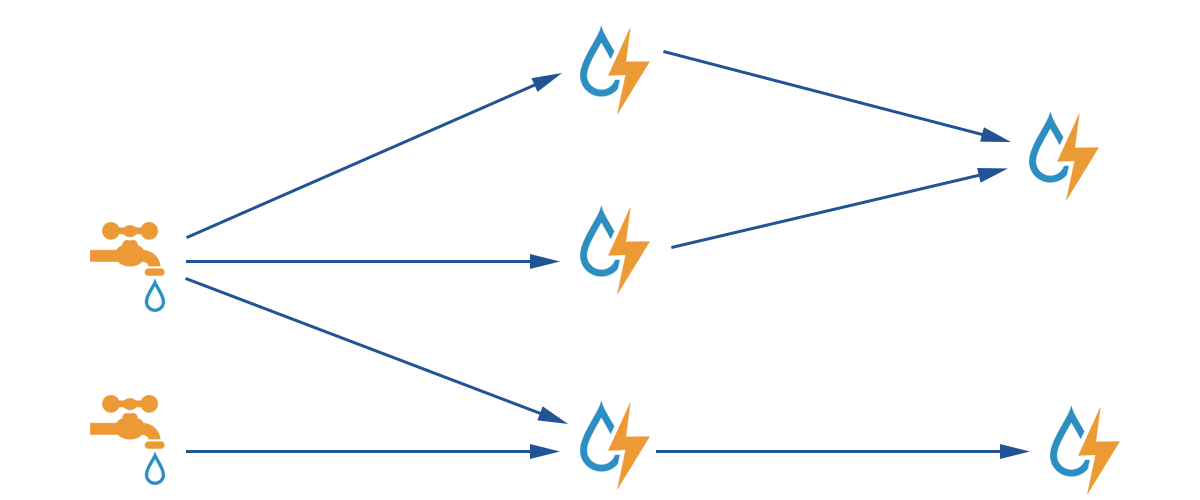
以上由spout和bolt組成的圖叫做topologies,上層的spout或者bolt向下層的Bolt來發射數據的時候,預設情況下都是default stream
storm常用的分發策略一共有5種,最常用的是Shuffle grouping和Fields grouping
storm中的ack機制:說白了就是storm通過Acker組件去數數,數Tuple tree裡面的Tuple是否都已經確認過,每個Tuple Tree對應一個msgId
提高並行度:
增加worker數量;增加Executor數量;設置task數量,預設一個線程裡面跑一個task
Storm實現可靠的消息保障機制:
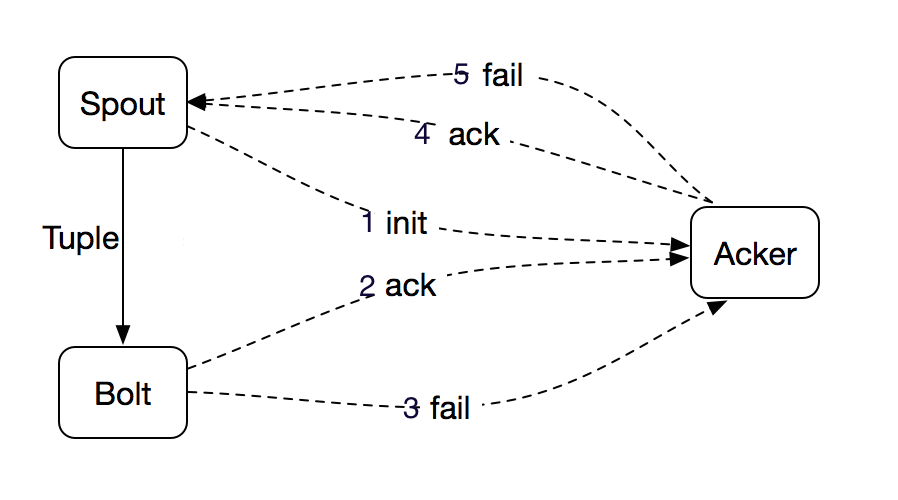
Tuple 的完全處理需要 Spout、Bolt 以及 Acker(Storm 中用來記錄某棵 Tuple 樹是否被完全處理的節點)協同完成,如上圖所示。從 Spout 發送 Tuple 到下游,並把相應信息通知給 Acker,整棵 Tuple 樹中某個 Tuple 被成功處理了都會通知 Acker,待整棵 Tuple 樹都被處理完成之後,Acker 將成功處理信息返回給 Spout;如果某個 Tuple 處理失敗,或者超時,Acker 將會給 Spout 發送一個處理失敗的消息,Spout 根據 Acker 的返回信息以及用戶對消息保證機制的選擇判斷是否需要進行消息重傳。

