
HBase簡介: HBase Hadoop DataBase,是一個高可靠、高性能、面向列、可存儲、實時讀寫的分散式資料庫 利用HBase HDFS作為其文件存儲系統 HBase數據模型: (1)RowKey: 決定一行數據,按照字典順序排序,RowKey只能存儲64K位元組數據 (2)Column ...
HBase簡介:
HBase---Hadoop DataBase,是一個高可靠、高性能、面向列、可存儲、實時讀寫的分散式資料庫
利用HBase HDFS作為其文件存儲系統
HBase數據模型:
(1)RowKey:
決定一行數據,按照字典順序排序,RowKey只能存儲64K位元組數據
(2)Column Family列族 & qualifier列:
HBase表中某個列都歸屬某個列族,列族必須作為表模式(schema)定義的一部分預先給出。
列名以列族作為首碼,每個列族都可以有多個列成員(cloumn)
HBase把同一列族裡面的數據存儲在統一目錄下,由幾個文件保存
(3)Timestamp時間戳
在HBase每個cell存儲單元對同一份數據有多個版本,根據唯一的時間戳來區分每個版本之間的差異,不同版本的數據按照時間倒序排序,最新的數據版本排在最前面;
時間戳的類型是64位整型
時間戳可以由HBase(在數據寫入時自動賦值)此時時間戳是精確到毫秒的當前系統時間
時間戳也可以由客戶顯示賦值,如果應用程式之間要避免數據版本衝突,就必須自己生成具有唯一性的時間戳
(4)Cell單元格
由行和列的坐標交叉決定;單元格是有版本的;單元格的內容是未解析的位元組數組
(5)HLog(WAL Log)
HLog文件就是一個普通的Hadoop Sequence File,Sequence File的key是HLogKey對象,HLogKey中記錄了寫入數據的歸屬信息,除了Table和Region名字外,同時還包括sequence number和timestamp,“timestamp”是寫入時間;
sequence number的起始值為0,或者是最近一次存入文件系統中sequence number
HLog SequenceFile的Value是HBase的keyValue是HBase的KeyValue對象,即對應HFile中的KeyValue
HBase體系架構
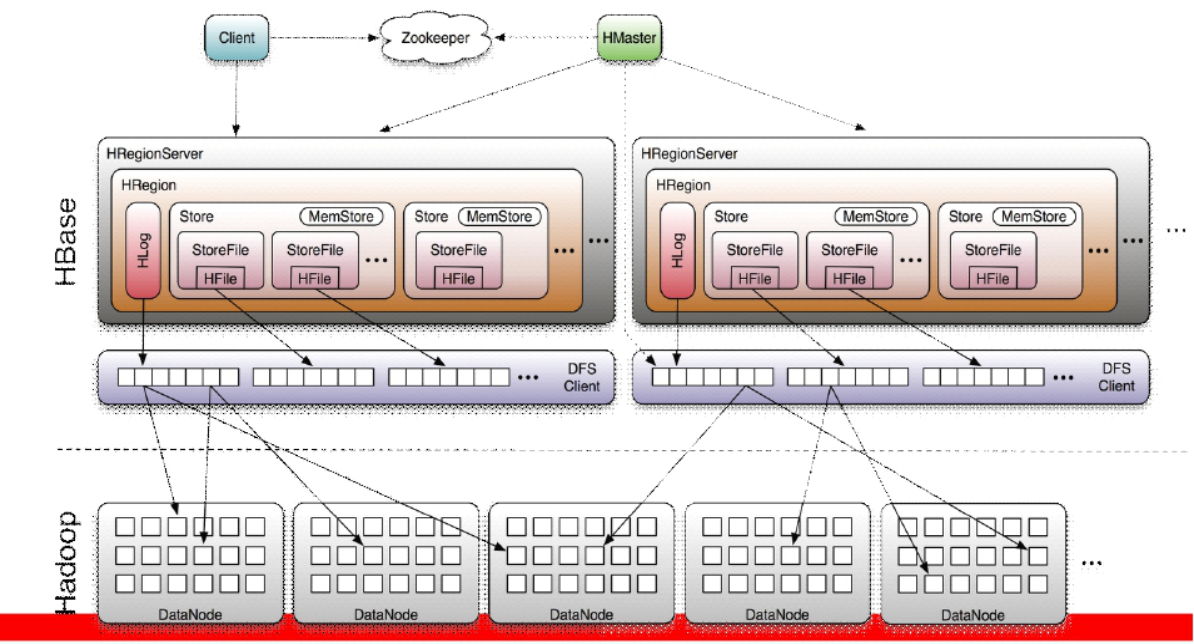
(1)Client
包含訪問HBase的介面並維護cache來加快對HBase的訪問
(2)Zookeeper
保證任何時候,集群中只有一個Master處於active狀態
存儲所有Region的定址入口
實時監控Region Server的上下線信息,並實時通知Master
存儲HBase的schema和table元數據信息
(3)Master
為Region Server分配region
負責Region Server的負載均衡
發現失效的Region Server,並重新分配失效Region Server上的Region
管理用戶對table的增刪改操作
(6)Region Server
Region Server維護region,處理對這些region的IO請求
Region Server負責切分在運行過程中變得過大的Region
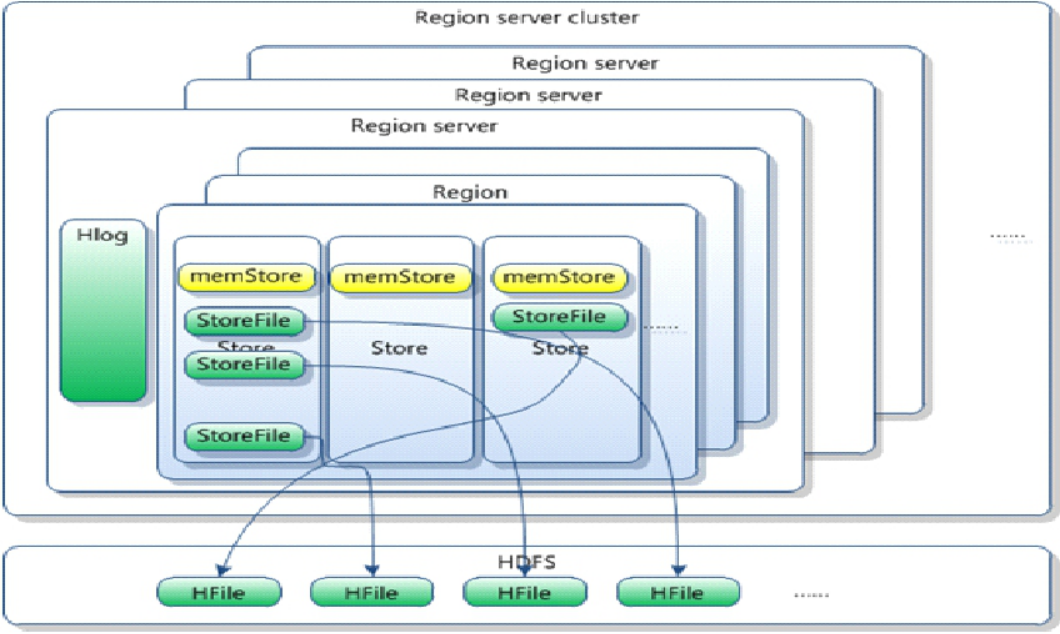
(7)Memstore和storefile
一個region由多個store組成,一個store對應一個CF;
store包括記憶體中的memstore和位於磁碟的storefile,寫操作先寫入memstore,當memstore中的數據達到某個閾值時,hregionserver會啟動flushcache進程寫入storefile,每次寫入形成一個單獨的storefile
當storefile文件數量增長到一定閾值的時候,系統會進行minor、major compaction,在合併過程中會進行版本合併和刪除工作,形成更大的storefile
當一個region中所有storefile的大小和數量超過一定閾值的時候,會把當前的region分割為兩個,並由hmaster分配到相應的regionserver上,實現負載均衡
客戶端檢索數據,先在memstore上找,找不到再去storefile中找
HRegion是HBase中分散式存儲和負載均衡的最小單元。最小單元就表示不同HRegion可以分佈在不同HRegion Server上面
HBase Compaction
主要有Minor Compaction和Major Compaction
Minor Compaction:指選取一些小的、相鄰的storefile將他們合併成更大的StoreFile,在這個過程不會處理Delete或者Expired的Cell
Major Compaction:指將所有的StoreFile合併成一個StoreFile,在這個過程中會有清理三類無意義數據:被刪除的數據,TTL過期的數據,版本號超過設定版本的數據,整個過程會消耗大量的系統資源
Compaction就是使用短時間的IO消耗以及帶寬消耗換取後續查詢的低延遲
Compaction流程:
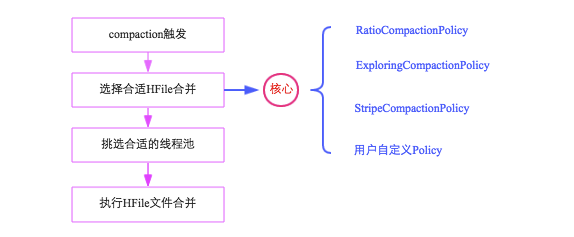
Compaction出發時機始於特定的觸發條件,比如flush、周期性的Compaction檢查操作或手動觸發,一旦觸發,HBase會將該Compaction交由一個單獨的線程去操作
Memstore Flush:memstore flush 會產生一個hfile文件,文件越來越多就需要compact,一旦文件數大於設定值就會進行compact
後臺線程周期性檢查:手動觸發,一般不會做過多的檢查,直接執行合併
sanpshort流程:
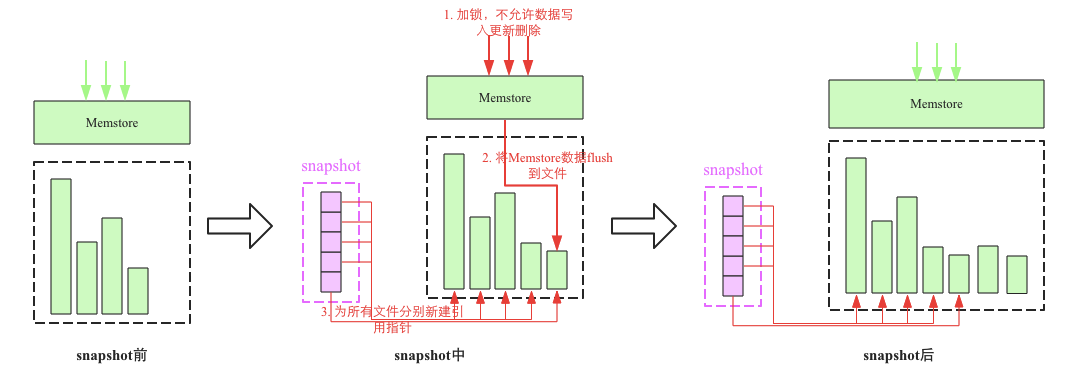
主要分為以下幾個步驟:
(1)加一把全局鎖,此時不允許任何數據寫入更新以及刪除操作
(2)將memstore中緩存的數據flush(可選)
(3)為所有hfile文件分別新建引用指引,這些指針元數據就是snapshort
功能:
(1)全量/增量的備份
(2)對重要數據業務進行快照,如果發生錯誤後可回滾之前的快照點
(3)數據遷移,使用ExportSnapshot功能將快照到另一個集群
snapshort使用:
(1)為表'sourceTable'打一個快照'snapshotName',快照並不涉及數據移動,可以線上完成
hbase> snapshot 'sourceTable','snapshotName'
(2)恢復指定快照,恢復過程會替代原有數據,將表還原到快照點,快照點之後的所有更新數據將會丟失,需要註意的是原有表需要先disable,然後才能恢復操作
hbase> restore_snapshot 'snapshotName'
(3)根據快照恢復出一個新表,恢復過程不涉及數據移動,可以在秒級完成
hbase> clone_snapshot 'snapshotName','tableName'
使用ExportSnapshot命令可以將A集群的快照數據遷移到B集群,ExportSnapshot是HDFS層面的操作,會使用MR進行數據的並行遷移,因此需要在開啟MR的機器上進行遷移。HMaster和HRegionServer並不參與這個過程,因此不會帶來額外的記憶體開銷以及GC開銷。唯一的影響是DN在拷貝數據的時候需要額外的帶寬以及IO負載,ExportSnapshot也針對這個問題設置了參數-bandwidth來限制帶寬的使用。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ -snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase \ -copy-to hdfs://srv1:50070/hbase -mappers 16 -bandwidth 1024\
HBase優化:
(1)表的設計:
- 表的預分區 可解決熱點問題
- RowKey設計 最大長度64kB,越小越好(可散列性,取反或hash)
- Column Family 一般設計1~3個,不宜太多
- Compact&Split 一般對於major做優化
- 設置最大版本號 Max Version [ HColumnDescriptor.setMaxVersions(int maxVersions) ]
- 設置表中數據的生命周期 Time To Live [ HColumnDescriptor.setTimeToLive(int timeToLive) ]
- 創建表的時候將表放入到緩存 In Memory [ HColumnDescriptor.setInMemory(true) ]
(2)寫表操作:
- Auto Flush 避免每put一條數據就刷新一次 [ HTable.setAutoFlush(false) ]
- Write Buffer 可以設置HTable客戶端寫Buffer大小 [ HTable.setWriteBufferSize(writeBufferSize) ]
- 批量寫
(3)讀表操作
- Scanner Caching 使用scan時候設置一次從服務端拉取的數據條數,可以減少scan過程中next()的時間開銷
- scan指定column family
- close resultscanner
- Blockcache 讀緩存

