
大數據簡介 大數據的概念 Volume(數據容量)、Variety(數據類型)、Viscosity(價值密度)、Velocity(速度)、Veracity(真實性) 大數據的性質 非結構性、不完備性、時效性、安全性、可靠性 大數據處理的全過程 數據採集與記錄 --> 數據抽取、清洗、標記 --> 數 ...
大數據簡介
大數據的概念
Volume(數據容量)、Variety(數據類型)、Viscosity(價值密度)、Velocity(速度)、Veracity(真實性)
大數據的性質
非結構性、不完備性、時效性、安全性、可靠性
大數據處理的全過程
數據採集與記錄 --> 數據抽取、清洗、標記 --> 數據集成、轉換、簡約 --> 數據分析與建模 --> 數據解釋
大數據技術的特征
1.分析全面的數據而非隨機抽樣
2.重視數據的複雜性,弱化精確性
3.關註數據的相關性,而非因果關係
大數據的關鍵技術
流處理、並行化、摘要索引、可視化
大數據應用趨勢
細分市場、推動企業發展、大數據分析的新方法出現、大數據與雲計算高度融合、大數據一體化設備陸續出現、大數據安全
科學研究範式
第一範式(科學實驗)、第二範式(科學理論)、第三範式(系統模擬)、第四範式(數據密集型計算)
格雷法則
1.科學計算數據爆炸式增長
2.解決方案為橫向擴展的體繫結構
3.將計算用於數據而不是數據用於計算(把程式向數據遷移。以計算為中心轉變為以數據為中心)
CAP理論
Consistency(一致性)、Availability(可用性)、Partition Tolerance(分區容錯性)
CAP定理
一個分散式系統不可能同時滿足一致性、可用性、分區容錯性三個系統需求,最多只能同時滿足兩個。
CAP選擇
1.放棄分區容錯,導致可擴展性不強:MySQL、Postgres
2.放棄可用性,導致性能不是特別高:Redis、MongoDB、MemcacheDB、HBase、BigTable、Hypertable
3.放棄一致性,對一致性要求低:Cassandra、Dynamo、Voldemort 、CouchDB
HDFS
HDFS目標
1.相容廉價的硬體設備
2.流數據讀寫
3.大數據集
4.簡單的文件模型
5.強大的跨平臺相容性
HDFS主要組件(圖來自哈爾濱理工大學大數據課程李老師的課件)

HDFS讀文件
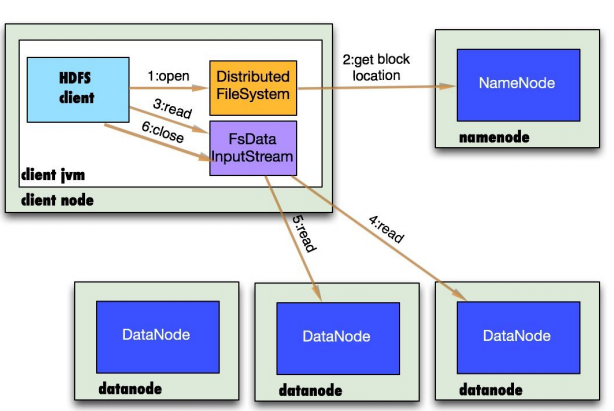
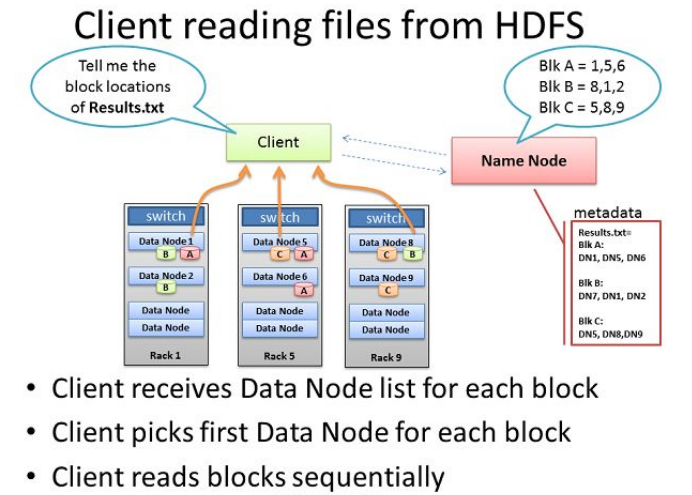
HDFS寫文件
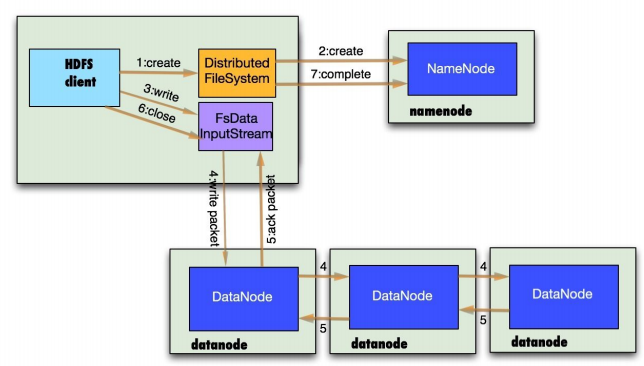
HDFS容錯
1.心跳檢測:NameNode和DataNode之間
2.文件塊完整性:記錄新建文件所有塊的校驗和
3.集群負載均衡:自動從負載重的DataNode上遷移數據
4.文件刪除:存放在/trash下,過一段時間才正式刪除。在hdfs-site.xml中配置
MapReduce
函數式編程優點
1.邏輯可證
2.模塊化
3.組件化
4.易於調試
5.易於測試
6.更高的生產率
函數式編程的特征
1.沒有副作用:沒有修改過函數在其作用域之外的量並被其他函數使用
2.無狀態的編程:將狀態保存在參數中,作為函數的附贈品來傳遞(不是很懂)
3.輸入值和輸出值:在函數式編程中,只有輸入值和輸出值。函數是基本的單位。在面向對象編程中,將對象傳來傳去;在函數式編程中,是將函數傳來傳去。
MapReduce流程圖(圖來自南京大學黃宜華老師的課件)

大數據流式計算
流式數據的特征
實時性、易失性、突發性、無序性、無限性、準確性
大數據流式計算模型
數據流管理系統:固定查詢、ad hoc查詢
大數據流式計算:Twitter Storm、Yahoo S4
Storm總體架構
主節點Nimbus:負責全局資源分配、任務調度、狀態監控、故障檢測
從節點Supervisor:接收任務,啟動或停止工作進程Worker。每個Worker內部有多個Executor。每個Executor對應一個線程。每個Executor對應一個或多個Task。
Zookeeper:協調、存儲元數據、從節點心跳信息、存儲整個集群的所有狀態信息、所有配置信息
Storm特征
1.編程簡單
2.支持多語言
3.作業級容錯
4.水平擴展
5.底層使用Zero消息隊列,快
Storm缺點
1.資源分配沒有考慮任務拓撲的結構特征,無法適應數據負載的動態變化
2.採用集中式的作業級容錯,限制了系統的可擴展性
搜索引擎
搜索引擎的定義
根據一定的策略、運用特定的電腦程式、從互聯網上搜集信息,對信息進行組織和處理之後,將這些信息展示給用戶的系統叫搜索引擎。
搜索引擎的組成
搜索器:搜集信息
索引器:抽取索引
檢索器:在庫中檢索,排序。
用戶介面:展示
搜索引擎的工作過程
爬行 -> 抓取存儲 -> 預處理 -> 排名
搜索引擎的評價指標
查全率、查準率、響應時間、覆蓋範圍、用戶方便性
大數據分析
數據分析的目的
對雜亂無章的數據進行集中、萃取、提煉,進而找出所研究對象的內在規律,發現其價值。
數據分析的意義
在雜亂的數據中分析出有價值的內容,獲得對數據的認知。
數據分析的類型
1.探索性數據分析(為了形成值得假設的檢驗)
2.定性數據分析(非數值型數據)
3.離線數據分析(先存於磁碟,批處理)
4.線上數據分析(實時)


