
一、 Redis常用數據類型 Redis最為常用的數據類型主要有以下: String Hash List Set Sorted set 一張圖說明問題的本質 圖一: 圖二: 代碼: /* Object types */ #define REDIS_STRING 0 #define REDIS_LIS
一、 Redis常用數據類型
Redis最為常用的數據類型主要有以下:
-
String
-
Hash
-
List
-
Set
-
Sorted set
一張圖說明問題的本質
圖一:
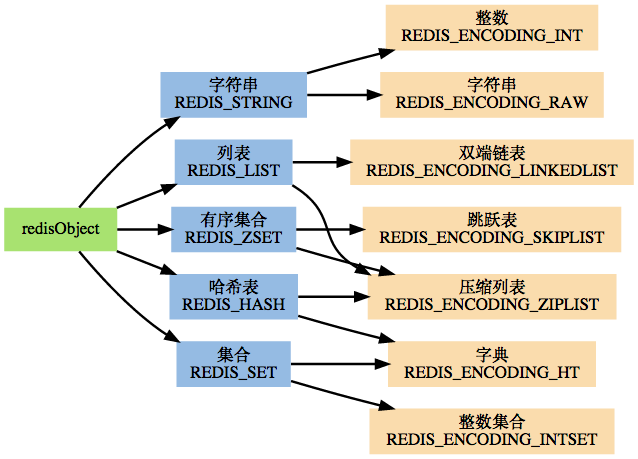
圖二:
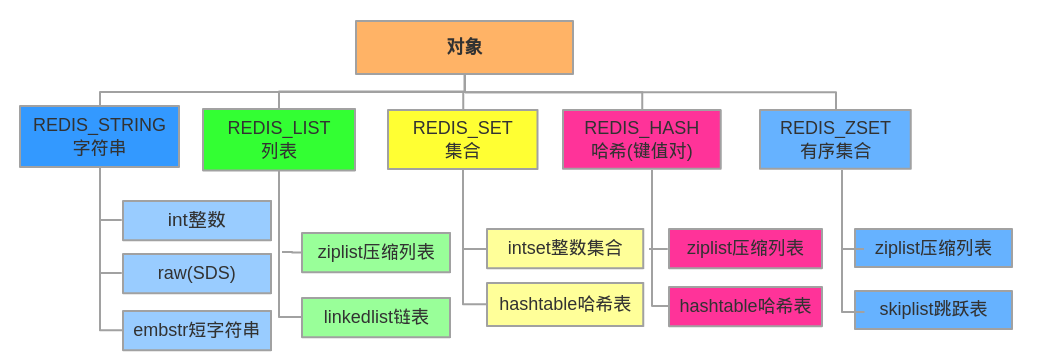
代碼:
/* Object types */ #define REDIS_STRING 0 #define REDIS_LIST 1 #define REDIS_SET 2 #define REDIS_ZSET 3 #define REDIS_HASH 4 /* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define REDIS_ENCODING_RAW 0 /* Raw representation */ #define REDIS_ENCODING_INT 1 /* Encoded as integer */ #define REDIS_ENCODING_HT 2 /* Encoded as hash table */ #define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */ #define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define REDIS_ENCODING_INTSET 6 /* Encoded as intset */ #define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
redisobject
/* The actual Redis Object */
#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
二、各種數據類型應用和實現方式
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}
1、String
-
如果一個字元串保存的是整數值,並且這個整數值可以用long類型表示,那麼字元串對象會把整數值保存到ptr所指的空間里,編碼設為int
-
如果是普通字元串,並且長度大於39位元組,使用redis自己實現的SDS類型
-
如果是普通字元串,並且長度小於等於39位元組,採用embstr存儲
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
embstr 編碼是專門用於保存短字元串的一種優化編碼方式, 這種編碼和 raw 編碼一樣, 都使用 redisObject 結構和 sdshdr 結構來表示字元串對象, 但 raw 編碼會調用兩次記憶體分配函數來分別創建 redisObject 結構和 sdshdr 結構, 而 embstr 編碼則通過調用一次記憶體分配函數來分配一塊連續的空間, 空間中依次包含 redisObject 和 sdshdr 兩個結構
應用場景:String是最常用的一種數據類型,普通的key/ value 存儲都可以歸為此類.即可以完全實現目前 Memcached 的功能,並且效率更高。還可以享受Redis的定時持久化,操作日誌及 Replication等功能。
除了提供與 Memcached 一樣的get、set、incr、decr 等操作外,Redis還提供了下麵一些操作:
-
獲取字元串長度
-
往字元串append內容
-
設置和獲取字元串的某一段內容
-
設置及獲取字元串的某一位(bit)
-
批量設置一系列字元串的內容
127.0.0.1:6379> set name "This is a test" OK 127.0.0.1:6379> get name "This is a test"
2、Hash
預設使用 REDIS_ENCODING_ZIPLIST 編碼, 當以下任何一個條件被滿足時, 程式將編碼從 REDIS_ENCODING_ZIPLIST 切換為 REDIS_ENCODING_HT
-
哈希表中某個鍵或某個值的長度大於
server.hash_max_ziplist_value(預設值為64) -
壓縮列表中的節點數量大於
server.hash_max_ziplist_entries(預設值為512)
應用場景:在Memcached中,我們經常將一些結構化的信息打包成HashMap,在客戶端序列化後存儲為一個字元串的值,比如用戶的昵稱、年齡、性別、積分等,這時候在需要修改其中某一項時,通常需要將所有值取出反序列化後,修改某一項的值,再序列化存儲回去。這樣不僅增大了開銷,也不適用於一些可能併發操作的場合(比如兩個併發的操作都需要修改積分)。而Redis的Hash結構可以使你像在資料庫中Update一個屬性一樣只修改某一項屬性值。
我們簡單舉個實例來描述下Hash的應用場景
比如我們要存儲一個用戶信息對象數據,包含以下信息:用戶ID為查找的key,存儲的value用戶對象包含姓名,年齡,生日等信息,如果用普通的key/value結構來存儲,主要有以下2種存儲方式:
第一種方式將用戶ID作為查找key,把其他信息封裝成一個對象以序列化的方式存儲,這種方式的缺點是,增加了序列化/反序列化的開銷,並且在需要修改其中一項信息時,需要把整個對象取回,並且修改操作需要對併發進行保護,引入CAS等複雜問題。
第二種方法是這個用戶信息對象有多少成員就存成多少個key-value對兒,用用戶ID+對應屬性的名稱作為唯一標識來取得對應屬性的值,雖然省去了序列化開銷和併發問題,但是用戶ID為重覆存儲,如果存在大量這樣的數據,記憶體浪費還是非常可觀的。
那麼Redis提供的Hash很好的解決了這個問題,Redis的Hash實際是內部存儲的Value為一個HashMap,並提供了直接存取這個Map成員的介面
Key仍然是用戶ID, value是一個Map,這個Map的key是成員的屬性名,value是屬性值,這樣對數據的修改和存取都可以直接通過其內部Map的Key(Redis里稱內部Map的key為field), 也就是通過 key(用戶ID) + field(屬性標簽) 就可以操作對應屬性數據了,既不需要重覆存儲數據,也不會帶來序列化和併發修改控制的問題,很好的解決了問題。
這裡同時需要註意,Redis提供了介面(hgetall)可以直接取到全部的屬性數據,但是如果內部Map的成員很多,那麼涉及到遍歷整個內部Map的操作,由於Redis單線程模型的緣故,這個遍歷操作可能會比較耗時,而另其它客戶端的請求完全不響應,這點需要格外註意。
127.0.0.1:6379> HMSET user:1 username root password 123456 score 100 OK 127.0.0.1:6379> hgetall user:1 1) "username" 2) "root" 3) "password" 4) "123456" 5) "score" 6) "100"
3、List
預設使用 REDIS_ENCODING_ZIPLIST 編碼, 當以下任意一個條件被滿足時, 列表會被轉換成 REDIS_ENCODING_LINKEDLIST 編碼
-
往列表新添加一個字元串值且這個字元串的長度超過
server.list_max_ziplist_value(預設值為64) -
ziplist包含的節點超過server.list_max_ziplist_entries(預設值為512)
應用場景:Redis list的應用場景非常多,也是Redis最重要的數據結構之一,比如twitter的關註列表,粉絲列表等都可以用Redis的list結構來實現。Lists 就是鏈表,相信略有數據結構知識的人都應該能理解其結構。使用Lists結構,我們可以輕鬆地實現最新消息排行等功能。Lists的另一個應用就是消息隊列,
可以利用Lists的PUSH操作,將任務存在Lists中,然後工作線程再用POP操作將任務取出進行執行。Redis還提供了操作Lists中某一段的api,你可以直接查詢,刪除Lists中某一段的元素。
127.0.0.1:6379> lpush list mysql (integer) 1 127.0.0.1:6379> lpush list mssql (integer) 2 127.0.0.1:6379> lpush list oracle (integer) 3 127.0.0.1:6379> lrange list 0 3 1) "oracle" 2) "mssql" 3) "mysql"
4、Set
-
如果第一個元素可以表示為
long long類型值(也即是,它是一個整數), 那麼集合的初始編碼為REDIS_ENCODING_INTSET -
否則集合的初始編碼為
REDIS_ENCODING_HT
如果一個集合使用 REDIS_ENCODING_INTSET 編碼, 那麼當以下任何一個條件被滿足時, 這個集合會被轉換成 REDIS_ENCODING_HT 編碼
-
intset保存的整數值個數超過server.set_max_intset_entries(預設值為512) -
試圖往集合里添加一個新元素,並且這個元素不能被表示為
long long類型(也即是,它不是一個整數)
應用場景:Redis set對外提供的功能與list類似是一個列表的功能,特殊之處在於set是可以自動排重的,當你需要存儲一個列表數據,又不希望出現重覆數據時,set是一個很好的選擇,並且set提供了判斷某個成員是否在一個set集合內的重要介面,這個也是list所不能提供的。
Sets 集合的概念就是一堆不重覆值的組合。利用Redis提供的Sets數據結構,可以存儲一些集合性的數據,比如在微博應用中,可以將一個用戶所有的關註人存在一個集合中,將其所有粉絲存在一個集合。Redis還為集合提供了求交集、並集、差集等操作,可以非常方便的實現如共同關註、共同喜好、二度好友等功能,對上面的所有集合操作,你還可以使用不同的命令選擇將結果返回給客戶端還是存集到一個新的集合中。
127.0.0.1:6379> sadd sets redis (integer) 1 127.0.0.1:6379> sadd sets mongodb (integer) 1 127.0.0.1:6379> sadd sets hbase (integer) 1 127.0.0.1:6379> smembers sets 1) "hbase" 2) "redis" 3) "mongodb"
5、Sorted Set
如果第一個元素符合以下條件的話, 就創建一個 REDIS_ENCODING_ZIPLIST 編碼的有序集
-
伺服器屬性
server.zset_max_ziplist_entries的值大於0(預設為128),元素的member長度小於伺服器屬性server.zset_max_ziplist_value的值(預設為64) - 否則,程式就創建一個
REDIS_ENCODING_SKIPLIST編碼的有序集
對於一個 REDIS_ENCODING_ZIPLIST 編碼的有序集, 只要滿足以下任一條件, 就將它轉換為 REDIS_ENCODING_SKIPLIST 編碼
-
ziplist所保存的元素數量超過伺服器屬性server.zset_max_ziplist_entries的值(預設值為128) -
新添加元素的
member的長度大於伺服器屬性server.zset_max_ziplist_value的值(預設值為64)
使用場景:Redis sorted set的使用場景與set類似,區別是set不是自動有序的,而sorted set可以通過用戶額外提供一個優先順序(score)的參數來為成員排序,並且是插入有序的,即自動排序。當你需要一個有序的並且不重覆的集合列表,那麼可以選擇sorted set數據結構,比如twitter 的public timeline可以以發表時間作為score來存儲,這樣獲取時就是自動按時間排好序的。
另外還可以用Sorted Sets來做帶權重的隊列,比如普通消息的score為1,重要消息的score為2,然後工作線程可以選擇按score的倒序來獲取工作任務。讓重要的任務優先執行。
127.0.0.1:6379> zadd ssets 0 redis (integer) 1 127.0.0.1:6379> zadd ssets 0 mongodb (integer) 1 127.0.0.1:6379> zadd ssets 0 hbase (integer) 1 127.0.0.1:6379> zrangebyscore ssets 0 10 1) "hbase" 2) "mongodb" 3) "redis"
三、其他
1、Pub/Sub
Pub/Sub 從字面上理解就是發佈(Publish)與訂閱(Subscribe),在Redis中,你可以設定對某一個key值進行消息發佈及消息訂閱,當一個key值上進行了消息發佈後,所有訂閱它的客戶端都會收到相應的消息。這一功能最明顯的用法就是用作實時消息系統,比如普通的即時聊天,群聊等功能
2、Transactions
誰說NoSQL都不支持事務,雖然Redis的Transactions提供的並不是嚴格的ACID的事務(比如一串用EXEC提交執行的命令,在執行中伺服器宕機,那麼會有一部分命令執行了,剩下的沒執行),但是這個Transactions還是提供了基本的命令打包執行的功能(在伺服器不出問題的情況下,可以保證一連串的命令是順序在一起執行的,中間有會有其它客戶端命令插進來執行)。Redis還提供了一個Watch功能,你可以對一個key進行Watch,然後再執行Transactions,在這過程中,如果這個Watched的值進行了修改,那麼這個Transactions會發現並拒絕執行


