
正則表達式是用於匹配字元串中字元組合的模式。在javascript中,正則表達式也是對象。這些模式被用於`RegExp`的`exec`、`test`方法,以及`String`的`match`、`replace`、`search`和`split`方法。 ...
正則表達式
學習筆記
標簽(空格分隔): 基礎
正則表達式是用於匹配字元串中字元組合的模式。在javascript中,正則表達式也是對象。這些模式被用於RegExp的exec、test方法,以及String的match、replace、search和split方法。
一、創建一個正則表達式
兩種方法構建正則表達式:
- 使用一個正則表達式字面來那個,其由包含在斜杠之間的模式組成。在載入腳本後,正則表達式字面值提供正則表達式的編譯。當正則表達式保持不變時,使用此方法可獲得更好的性能。
const regex = /ab+c/;
const regex_2 = /^[a-zA-Z]+[0-9]*\W?_$/gi;- 調用
RegExp對象的構造函數。使用構造函數提供正則表達式的運行時編譯。使用構造函數,當你知道正則表達式模式將會改變,或者你不知道模式,並從另一個來源,如用戶輸入。
let regex_3 = new RegExp('ab+c');
let regex_4 = new RegExp(/^[a-zA-Z]+[0-9]*\W?_$/, 'gi');
let regex_5 = new RegExp('^[a-zA-Z]+[0-9]*\\W?_$', 'gi');二、編寫一個正則表達式的模式
一個正則表達式模式是由簡單的字元所構成的,比如/ab/,或者是簡單和特殊字元的組合,比如/ab*c/或/Chapter (\d+)\.\d*/。或者用到了括弧,它在正則表達式中可以被用做是一個記憶設備。這一部分的正則所匹配的字元將會被記住,在後面可以被利用。
1. 使用簡單的模式
簡單的模式是由你找到的字元直接匹配所構成的。比如/abc/這個模式就匹配了字元串中僅僅字元'abc'同時出現並按照這個順序。在'Hi, do u know ur abc's?'和'The latest artplane designs evolved from slabcraft.'都能匹配成功。在上面兩個實例中,匹配的是子字元串'abc'。在字元串'Grab crab'中將不會被匹配,因為它不包含任何的'abc'子字元串。
2. 使用特殊字元
當你需要搜索一個比直接匹配需要更多條件的匹配時,比如尋找一個或多個'b'後面跟了零個或者多個'b'(*的意思就是前面一項出現了零個或者多個),而且後面跟著'c'的任何字元串'cbbabbbbcdebc'中,這個模式匹配了子字元串'abbbbc'。
正則表達式中的特殊字元
| 字元 | 含義 |
|---|---|
\ |
轉義 匹配將依照下列規則: 在非特殊字元之前的反斜杠表示下一個字元是特殊的,不能從字面上解釋。例如,沒有''的 'b'匹配小寫'b',而加了\表示匹配一個字元邊界。反斜杠也可以將其後的特殊字元,轉義為字面量。例如,模式 /a*/表示會匹配0個或者多個a;而模式/a\*/表示匹配'a*'這樣的字元串。使用 new RegExp('pattern')時需要將\進行轉義,因為\在字元串里也是一個轉義字元。 |
^ |
匹配輸入的開始。 如果多行標誌被設置為true,那麼也匹配換行符後緊跟的位置。 例如, /^A/並不會匹配'an A'中的A,但是會匹配'An E'中的A。當'^'作為第一個字元出現在一個字元集合模式時,它將會有不同的含義。 |
$ |
匹配輸入的結束。匹配行或字元串的結尾。 如果多行標誌被設置為true,那麼也匹配換行符前的位置。 例如, /t$/不會匹配'eater'中的't',會匹配'eat'中的't'。 |
* |
匹配前一個表達式0次或多次。等價於{0,}。 例如, /bo*/會匹配'A ghost boooooed'中的'booooo'和'A bird warbled'中的'b',但是在'A goat grunted'中將不會匹配。 |
+ |
匹配前面一個表達式1次或者多次。等價於{1,}。 例如,在 /a+/匹配了'candy'中的'a',和在'caaaaandy'中的所有'a'。 |
? |
匹配前面一個表達式0次或1次。等價於{0,1}。 例如, /e?le?/匹配'angel'中的'el','angle'中的'le','oslo'中的'l'。如果緊跟在任何量詞、+?或{}的後面,將會使量詞變為非貪婪的(匹配儘量少的字元),和預設使用的貪婪模式正好相反。 例如,'123abc'應用 /\d+/將會返回'123',如果使用/\d+?/,就只會匹配到'1'。還可以運用於先行斷言,比如本表的 x(?=y)和x(?!y)條目中所述。 |
. |
(小數點)匹配除換行符之外的任何單個字元。 例如, /.n/匹配'nay, an apple is on the tree'中的'an'和'on',不會匹配'nay'。 |
(x) |
匹配'x'並且記住匹配項,就像下麵的例子展示的那樣,括弧被稱為捕獲括弧 模式 /(foo) (bar) \1 \2/中的'(foo)'和'(bar)'匹配並記住字元串'foo bar foo bar'中的前兩個單詞。模式中的\1和\2匹配字元串的後兩個單詞。註意使用\1、\2、\n是用在正則表達式的匹配環節。在正則表達式的替換環節,則要使用像$1、$2、$n的語法,例如,'bar foo'.replace(/(...) (...)/, '$2 $1')。 |
(?:x) |
匹配'x'但是不記住匹配項。這種叫做非捕獲括弧,使得你能夠定義為與正則表達式運算符一起使用的子表達式。 來看示例表達式 /(?:foo){1,2}/。如果表達式是/foo{1,2}/,{1,2}將只對'foo'的最後一個字元'o'生效。如果使用非捕獲括弧,則{1,2}會匹配整個'foo'單詞。 |
x(?=y) |
匹配'x'僅僅當'x'後面跟著'y'。這種叫做正向肯定查找。 例如, /Jack(?=Sprat)/會匹配到'Jack'僅僅當它後面跟著'Sprat'。/Jack(?=Sprat\|Frost)/匹配'Jack'僅當它後面跟著'Sprat'或者是'Frost'。但是'Sprat'和'Frost'都不是匹配結果的一部分。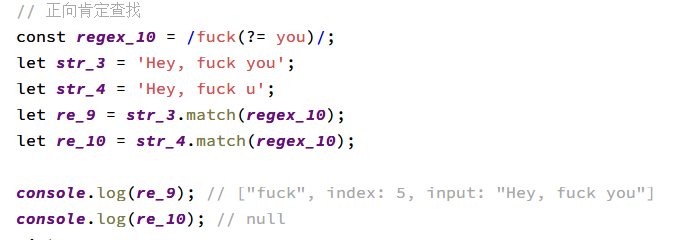 |
x(?!y) |
匹配'x'僅當'x'後面不跟著'y',這叫做正向否定查找。 例如, /\d+(?!\.)/匹配一個數字僅僅當這個數字後面沒有跟小數點的時候。正則表達式/\d+(?!\.)/.exec('3.141')匹配'141'而不是'3.141'。 |
x\|y |
匹配x或者y。 例如,/green|red/匹配'green apple'中的'green'和'red apple'中的'red'。 |
{n} |
n是一個正整數,匹配了前面一個字元剛好發生了n次。 比如, /a{2}/不會匹配'candy'中的'a',但是會匹配'caandy'中所有的a,以及'caaandy'中的前兩個'a'。 |
{n,m} |
n和m都是整數。匹配前面的字元至少n次,最多m次。如果n或者m的值是0,這個值被忽略。 例如, /a{1,3}/並不匹配'cndy'中的任意字元,匹配'candy'中的a,匹配'caandy'中的前兩個a,匹配'caaaaaandy'中的前3個a。 |
[xyz] |
一個字元集合。匹配方括弧中的任意字元,包括轉義序列。 你可以用短橫線( -)來指定一個字元範圍。對於點(.)和星號(*)這樣的特殊符號在一個字元集中沒有特殊的意義。他們不必進行轉義,不過轉義也是起作用的。例如, [abcd]和[a-d]是一樣的,他們都匹配'brisket'中的'b',也都匹配'city'中的'c'。/[a-z.]+/和/[\w.]+/都匹配'test.i.ng'中的所有字元。 |
[^xyz] |
一個反向字元集。也就是說,它匹配任何沒有包含在方括弧中的字元。你可以使用短橫線(-)來指定一個字元範圍。任何普通字元在這裡都起作用。例如, [^abc]和[^a-c]是一樣的。他們匹配'brisket'中的'r',也匹配'chop'中的'h'。 |
[\b] |
匹配一個退格(U+0008)(不要和\b混淆)。 |
\b |
匹配一個詞的邊界。一個詞的邊界就是一個詞不被另外一個詞跟隨的位置或者不是另一個辭彙字元前邊的位置。註意一個匹配的詞的邊界並不包含在匹配內容中。換句話說,一個匹配的詞的邊界的內容長度是0。 例如, /\bm/匹配'moon'中的'm'。/oo\b/不匹配'moon'中的'oo',因為'oo'被一個辭彙字元'n'緊跟著。/oon\b/匹配'moon'中的'oon',因為'oon'是這個字元串的結束部分。這樣它沒有被一個辭彙字元緊跟著。/\w\b\w/將不能匹配任何字元串,因為一個單詞中的字元永遠也不可能被一個非辭彙字元和一個辭彙字元同時緊跟著。註意:javascript的正則表達式引擎將»特定的字元集定義為“字”字元。不在該集合中的任何字元都被認為是一個斷詞。這組字元相當有限:它只包括大寫和小寫的羅馬字母,小數位數和下劃線字元。不幸的是,重要的字元,例如'é'和'ü'被視為斷詞。 |
\B |
匹配一個非單詞邊界。它匹配一個前後字元都是相同類型的位置:都是字元或者都不是單詞。一個字元串的開始和結尾都被認為是非單詞。 例如, /\B../匹配'noonday'中的'oo',而/y\B/匹配'possibly yesterday'中的'y'。 |
\cX |
當X是處於A到Z之間的字元的時候,匹配字元串中的一個控制符。 例如, /\cM/匹配字元串中的control-M(U+000D)。 |
\d |
匹配一個數字。 等價於 [0-9]。例如, /\d/或者/[0-9]/匹配'B2 is the suite number.'中的'2'。 |
\D |
匹配一個非數字子字元。 等價於 [^0-9]。例如, /\D/或者/[^0-9]/匹配'B2 is the suite number.'中的'B'。 |
\f |
匹配一個換頁符(U+000C)。 |
\n |
匹配一個換頁符(U+000A)。 |
\r |
匹配一個換頁符(U+000D)。 |
\s |
匹配一個空白字元,包括空格、製表符、換頁符和換行符。 等價於 [\f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。例如, /\s\w*/匹配'foo bar'中的' bar'。 |
\S |
匹配一個非空白字元。 等價於 [^\f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。例如, /\S\w*/匹配'foo bar'中的'foo'。 |
\t |
匹配一個水平製表符(U+0009)。 |
\v |
匹配一個垂直製表符(U+000B)。 |
\w |
匹配一個單字字元(字母、數字、下劃線)。 等價於 [A-Za-z0-9_]。例如, /\w/匹配'apple'中的'a','$5.28'中的'5','3D.'中的'3'。 |
\W |
匹配一個非單字字元。 等價於 [^A-Za-z0-9_]。例如, /\W/匹配'50%'中的'%'。 |
\n |
當n是一個正整數,一個返回引用到最後一個與有n插入的zh正值表達式(counting left parentheses)匹配的副字元串。 比如, /apple(,)\sorange\1/匹配'apple, orange, cherry, peach'中的'apple,orange,'。 |
To be continued... Last updated by: Jehorn, Dec 29, 2017, 2:57 PM


