
本文作者在一年之內參加過多場面試,應聘崗位均為 Java 開發方向。在不斷的面試中,分類總結了 Java 開發崗位面試中的一些知識點。 主要包括以下幾個部分: 面試,是大家從學校走向社會的第一步。 互聯網公司的校園招聘,從形式上說,面試一般分為 2-3 輪技術面試 +1 輪 HR 面試。但是一些公司 ...
天之道,損有餘而補不足,是故虛勝實,不足勝有餘。
本文作者在一年之內參加過多場面試,應聘崗位均為 Java 開發方向。在不斷的面試中,分類總結了 Java 開發崗位面試中的一些知識點。
主要包括以下幾個部分:
- Java 基礎知識點
- Java 常見集合
- 高併發編程(JUC 包)
- JVM 記憶體管理
- Java 8 知識點
- 網路協議相關
- 資料庫相關
- MVC 框架相關
- 大數據相關
- Linux 命令相關
面試,是大家從學校走向社會的第一步。
互聯網公司的校園招聘,從形式上說,面試一般分為 2-3 輪技術面試 +1 輪 HR 面試。但是一些公司確實是沒有 HR 面試的,直接就是三輪技術面。
技術面試中,面試官一般會先就你所應聘的崗位進行相關知識的考察,也叫基礎知識和業務邏輯面試。只要你回答的不是特別差,面試官通常會說:“咱們寫個代碼吧”,這個時候就開始了演算法面試。
也就是說,一輪技術面試 = 基礎知識和業務邏輯面試 + 演算法面試。
在本篇文章中,我們主要從技術面試聊起。技術面試包括:業務邏輯和基礎知識面試。
首先是業務邏輯面試 ,也就是講項目。
面試官會對你簡歷上寫的若幹個項目其中之一拿出來和你聊聊。在期間,會針對你所做的東西進行深度挖掘。
包括:為什麼要這麼做?優缺點分析,假如重新讓你做一次,你打算怎麼做? 等等。這個環節主要考察我們對自己做過的項目(實習項目或者校內項目)是否有一個清晰的認識。
關於業務邏輯面試的準備,建議在平時多多思考總結,對項目的數據來源、整體運行框架都應該熟悉掌握。
比如說你在某公司實習過程中,就可以進行總結,而不必等到快離職的時候慌慌張張的去總結該項目。
接下來是基礎知識面試。
Java 開發屬於後臺開發方向,有人說後臺開發很坑,因為需要學習的東西太多了。沒錯,這個崗位就是需要學習好多東西。包括:本語言(Java/C++/PHP)基礎、資料庫、網路協議、Linux 系統、電腦原理甚至前端相關知識都可以考察你,而且,並不超綱 。
有時候,你報的是後臺開發崗,並且熟悉的是 Java 語言,但是面試官卻是 C++ 開發方向的,就是這麼無奈~
好了,閑話少說,讓我們開始分類講解常見面試知識點。
(一) Java 基礎知識點
1)面向對象的特性有哪些?
答:封裝、繼承和多態。
2)Java 中覆蓋和重載是什麼意思?
解析:覆蓋和重載是比較重要的基礎知識點,並且容易混淆,所以面試中常見。
答:覆蓋(Override)是指子類對父類方法的一種重寫,只能比父類拋出更少的異常,訪問許可權不能比父類的小。
被覆蓋的方法不能是 private 的,否則只是在子類中重新定義了一個方法;重載(Overload)表示同一個類中可以有多個名稱相同的方法,但這些方法的參數列表各不相同。
面試官: 那麼構成重載的條件有哪些?
答:參數類型不同、參數個數不同、參數順序不同。
面試官: 函數的返回值不同可以構成重載嗎?為什麼?
答:不可以,因為 Java 中調用函數並不需要強制賦值。舉例如下:
如下兩個方法:
void f(){}
int f(){ return 1;}
只要編譯器可以根據語境明確判斷出語義,比如在 int x = f();中,那麼的確可以據此區分重載方法。不過, 有時你並不關心方法的返回值,你想要的是方法調用的其他效果 (這常被稱為 “為了副作用而調用”),這時你可能會調用方法而忽略其返回值,所以如果像下麵的調用:
fun();
此時 Java 如何才能判斷調用的是哪一個 f() 呢?別人如何理解這種代碼呢?所以,根據方法返回值來區分重載方法是行不通的。
3)抽象類和介面的區別有哪些?
答:
- 抽象類中可以沒有抽象方法;介面中的方法必須是抽象方法;
- 抽象類中可以有普通的成員變數;介面中的變數必須是 static final 類型的,必須被初始化 , 介面中只有常量,沒有變數。
- 抽象類只能單繼承,介面可以繼承多個父介面;
- Java8 中介面中會有 default 方法,即方法可以被實現。
面試官:抽象類和介面如何選擇?
答:
- 如果要創建不帶任何方法定義和成員變數的基類,那麼就應該選擇介面而不是抽象類。
- 如果知道某個類應該是基類,那麼第一個選擇的應該是讓它成為一個介面,只有在必須要有方法定義和成員變數的時候,才應該選擇抽象類。因為抽象類中允許存在一個或多個被具體實現的方法,只要方法沒有被全部實現該類就仍是抽象類。
4)Java 和 C++ 的區別:
解析:雖然我們不太懂 C++,但是就是會這麼問,尤其是三面(總監級別)面試中。
答:
- 都是面向對象的語言,都支持封裝、繼承和多態;
- 指針:Java 不提供指針來直接訪問記憶體,程式更加安全;
- 繼承: Java 的類是單繼承的,C++ 支持多重繼承; Java 通過一個類實現多個介面來實現 C++ 中的多重繼承; Java 中類不可以多繼承,但是!!!介面可以多繼承;
- 記憶體: Java 有自動記憶體管理機制,不需要程式員手動釋放無用記憶體。
5)Java 中的值傳遞和引用傳遞
解析:這類題目,面試官會手寫一個例子,讓你說出函數執行結果,詳細舉例請查閱我的博客:Java 值傳遞和引用傳遞基礎分析。
答:值傳遞是指對象被值傳遞,意味著傳遞了對象的一個副本,即使副本被改變,也不會影響源對象。引用傳遞是指對象被引用傳遞,意味著傳遞的並不是實際的對象,而是對象的引用。
因此,外部對引用對象的改變會反映到所有的對象上。
6)JDK 中常用的包有哪些?
答:java.lang、java.util、http://java.io、http://java.net、java.sql。
7)JDK,JRE 和 JVM 的聯繫和區別:
答:JDK 是 java 開發工具包,是 java 開發環境的核心組件,並提供編譯、調試和運行一個 java 程式所需要的所有工具,可執行文件和二進位文件,是一個平臺特定的軟體。
JRE 是 java 運行時環境,是 JVM 的實施實現,提供了運行 java 程式的平臺。JRE 包含了 JVM,但是不包含 java 編譯器 / 調試器之類的開發工具。
JVM 是 java 虛擬機,當我們運行一個程式時,JVM 負責將位元組碼轉換為特定機器代碼,JVM 提供了記憶體管理 / 垃圾回收和安全機制等。
這種獨立於硬體和操作系統,正是 java 程式可以一次編寫多處執行的原因。
區別:
- JDK 用於開發,JRE 用於運行 java 程式;
- JDK 和 JRE 中都包含 JVM;
- JVM 是 java 編程語言的核心並且具有平臺獨立性。
Others:限於篇幅,面試中 Java 基礎知識點還有:反射、泛型、註解等。
小結:本節主要闡述了 Java 基礎知識點,這些問題主要是一面面試官在考察,難度不大,適當複習下,應該沒什麼問題。
(二)Java 中常見集合
集合這方面的考察相當多,這部分是面試中必考的知識點。
1)說說常見的集合有哪些吧?
答:Map 介面和 Collection 介面是所有集合框架的父介面:
- Collection 介面的子介面包括:Set 介面和 List 介面;
- Map 介面的實現類主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap 以及 Properties 等;
- Set 介面的實現類主要有:HashSet、TreeSet、LinkedHashSet 等;
- List 介面的實現類主要有:ArrayList、LinkedList、Stack 以及 Vector 等。
(2)HashMap 和 Hashtable 的區別有哪些?(必問)
答:
- HashMap 沒有考慮同步,是線程不安全的;Hashtable 使用了 synchronized 關鍵字,是線程安全的;
- 前者允許 null 作為 Key;後者不允許 null 作為 Key。
3)HashMap 的底層實現你知道嗎?
答:在 Java8 之前,其底層實現是數組 + 鏈表實現,Java8 使用了數組 + 鏈表 + 紅黑樹實現。此時你可以簡單的在紙上畫圖分析:
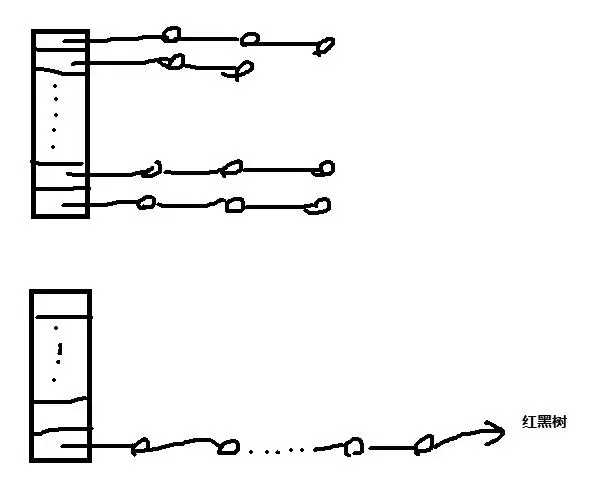
4)ConcurrentHashMap 和 Hashtable 的區別? (必問)
答:ConcurrentHashMap 結合了 HashMap 和 HashTable 二者的優勢。HashMap 沒有考慮同步,hashtable 考慮了同步的問題。但是 hashtable 在每次同步執行時都要鎖住整個結構。 ConcurrentHashMap 鎖的方式是稍微細粒度的。 ConcurrentHashMap 將 hash 表分為 16 個桶(預設值),諸如 get,put,remove 等常用操作只鎖當前需要用到的桶。
面試官:ConcurrentHashMap 的具體實現知道嗎?
答:
- 該類包含兩個靜態內部類 HashEntry 和 Segment;前者用來封裝映射表的鍵值對,後者用來充當鎖的角色;
- Segment 是一種可重入的鎖 ReentrantLock,每個 Segment 守護一個 HashEntry 數組裡得元素,當對 HashEntry 數組的數據進行修改時,必須首先獲得對應的 Segment 鎖。
5)HashMap 的長度為什麼是 2 的冪次方?
答:
- 通過將 Key 的 hash 值與 length-1 進行 & 運算,實現了當前 Key 的定位,2 的冪次方可以減少衝突(碰撞)的次數,提高 HashMap 查詢效率;
- 如果 length 為 2 的次冪 則 length-1 轉化為二進位必定是 11111……的形式,在於 h 的二進位與操作效率會非常的快,而且空間不浪費;
- 如果 length 不是 2 的次冪,比如 length 為 15,則 length-1 為 14,對應的二進位為 1110,在於 h 與操作,最後一位都為 0,而 0001,0011,0101,1001,1011,0111,1101 這幾個位置永遠都不能存放元素了,空間浪費相當大。
更糟的是這種情況中,數組可以使用的位置比數組長度小了很多,這意味著進一步增加了碰撞的幾率,減慢了查詢的效率!這樣就會造成空間的浪費。
6)List 和 Set 的區別是啥?
答:List 元素是有序的,可以重覆;Set 元素是無序的,不可以重覆。
7)List、Set 和 Map 的初始容量和載入因數
答:
1. List
- ArrayList 的初始容量是 10;載入因數為 0.5; 擴容增量:原容量的 0.5 倍 +1;一次擴容後長度為 16。
- Vector 初始容量為 10,載入因數是 1。擴容增量:原容量的 1 倍,如 Vector 的容量為 10,一次擴容後是容量為 20。
2. Set
HashSet,初始容量為 16,載入因數為 0.75; 擴容增量:原容量的 1 倍; 如 HashSet 的容量為 16,一次擴容後容量為 32
3. Map
HashMap,初始容量 16,載入因數為 0.75; 擴容增量:原容量的 1 倍; 如 HashMap 的容量為 16,一次擴容後容量為 32
8)Comparable 介面和 Comparator 介面有什麼區別?
答:
- 前者簡單,但是如果需要重新定義比較類型時,需要修改源代碼。
- 後者不需要修改源代碼,自定義一個比較器,實現自定義的比較方法。
具體解析參考我的博客:Java 集合框架—Set
9)Java 集合的快速失敗機制 “fail-fast”
答:它是 java 集合的一種錯誤檢測機制,當多個線程對集合進行結構上的改變的操作時,有可能會產生 fail-fast 機制。
例如 :假設存在兩個線程(線程 1、線程 2),線程 1 通過 Iterator 在遍歷集合 A 中的元素,在某個時候線程 2 修改了集合 A 的結構(是結構上面的修改,而不是簡單的修改集合元素的內容),那麼這個時候程式就會拋出 ConcurrentModificationException 異常,從而產生 fail-fast 機制。
原因: 迭代器在遍歷時直接訪問集合中的內容,並且在遍歷過程中使用一個 modCount 變數。集合在被遍歷期間如果內容發生變化,就會改變 modCount 的值。
每當迭代器使用 hashNext()/next() 遍歷下一個元素之前,都會檢測 modCount 變數是否為 expectedmodCount 值,是的話就返回遍歷;否則拋出異常,終止遍歷。
解決辦法:
- 在遍歷過程中,所有涉及到改變 modCount 值得地方全部加上 synchronized;
- 使用 CopyOnWriteArrayList 來替換 ArrayList。
小結:本小節是 Java 中關於集合的考察,是 Java 崗位面試中必考的知識點,除了應該掌握以上的問題,包括各個集合的底層實現也建議各位同學閱讀,加深理解。
(三)高併發編程-JUC 包
在 Java 5.0 提供了 java.util.concurrent(簡稱 JUC )包,在此包中增加了在併發編程中很常用的實用工具類,用於定義類似於線程的自定義子系統,包括線程池、非同步 IO 和輕量級任務框架。
1)多線程和單線程的區別和聯繫:
答:
- 在單核 CPU 中,將 CPU 分為很小的時間片,在每一時刻只能有一個線程在執行,是一種微觀上輪流占用 CPU 的機制。
- 多線程會存線上程上下文切換,會導致程式執行速度變慢,即採用一個擁有兩個線程的進程執行所需要的時間比一個線程的進程執行兩次所需要的時間要多一些。
結論:即採用多線程不會提高程式的執行速度,反而會降低速度,但是對於用戶來說,可以減少用戶的響應時間。
2)如何指定多個線程的執行順序?
解析:面試官會給你舉個例子,如何讓 10 個線程按照順序列印 0123456789?(寫代碼實現)
答:
- 設定一個 orderNum,每個線程執行結束之後,更新 orderNum,指明下一個要執行的線程。並且喚醒所有的等待線程。
- 在每一個線程的開始,要 while 判斷 orderNum 是否等於自己的要求值!!不是,則 wait,是則執行本線程。
3)線程和進程的區別:(必考)
答:
- 進程是一個 “執行中的程式”,是系統進行資源分配和調度的一個獨立單位;
- 線程是進程的一個實體,一個進程中擁有多個線程,線程之間共用地址空間和其它資源(所以通信和同步等操作線程比進程更加容易);
- 線程上下文的切換比進程上下文切換要快很多。
- (1)進程切換時,涉及到當前進程的 CPU 環境的保存和新被調度運行進程的 CPU 環境的設置。
- (2)線程切換僅需要保存和設置少量的寄存器內容,不涉及存儲管理方面的操作。
4)多線程產生死鎖的 4 個必要條件?
答:
- 互斥條件:一個資源每次只能被一個線程使用;
- 請求與保持條件:一個線程因請求資源而阻塞時,對已獲得的資源保持不放;
- 不剝奪條件:進程已經獲得的資源,在未使用完之前,不能強行剝奪;
- 迴圈等待條件:若幹線程之間形成一種頭尾相接的迴圈等待資源關係。
面試官:如何避免死鎖?(經常接著問這個問題哦~)
答:指定獲取鎖的順序,舉例如下:
- 比如某個線程只有獲得 A 鎖和 B 鎖才能對某資源進行操作,在多線程條件下,如何避免死鎖?
- 獲得鎖的順序是一定的,比如規定,只有獲得 A 鎖的線程才有資格獲取 B 鎖,按順序獲取鎖就可以避免死鎖!!!
5)sleep( ) 和 wait( n)、wait( ) 的區別:
答:
- sleep 方法:是 Thread 類的靜態方法,當前線程將睡眠 n 毫秒,線程進入阻塞狀態。當睡眠時間到了,會解除阻塞,進行可運行狀態,等待 CPU 的到來。睡眠不釋放鎖(如果有的話);
- wait 方法:是 Object 的方法,必須與 synchronized 關鍵字一起使用,線程進入阻塞狀態,當 notify 或者 notifyall 被調用後,會解除阻塞。但是,只有重新占用互斥鎖之後才會進入可運行狀態。睡眠時,釋放互斥鎖。
6)synchronized 關鍵字:
答:底層實現:
- 進入時,執行 monitorenter,將計數器 +1,釋放鎖 monitorexit 時,計數器-1;
- 當一個線程判斷到計數器為 0 時,則當前鎖空閑,可以占用;反之,當前線程進入等待狀態。
含義:(monitor 機制)
Synchronized 是在加鎖,加對象鎖。對象鎖是一種重量鎖(monitor),synchronized 的鎖機制會根據線程競爭情況在運行時會有偏向鎖(單一線程)、輕量鎖(多個線程訪問 synchronized 區域)、對象鎖(重量鎖,多個線程存在競爭的情況)、自旋鎖等。
該關鍵字是一個幾種鎖的封裝。
7)volatile 關鍵字
答:該關鍵字可以保證可見性不保證原子性。
功能:
- 主記憶體和工作記憶體,直接與主記憶體產生交互,進行讀寫操作,保證可見性;
- 禁止 JVM 進行的指令重排序。
解析:關於指令重排序的問題,可以查閱 DCL 雙檢鎖失效相關資料。
8)ThreadLocal(線程局部變數)關鍵字:
答:當使用 ThreadLocal 維護變數時,其為每個使用該變數的線程提供獨立的變數副本,所以每一個線程都可以獨立的改變自己的副本,而不會影響其他線程對應的副本。
ThreadLocal 內部實現機制:
- 每個線程內部都會維護一個類似 HashMap 的對象,稱為 ThreadLocalMap,裡邊會包含若幹了 Entry(K-V 鍵值對),相應的線程被稱為這些 Entry 的屬主線程;
- Entry 的 Key 是一個 ThreadLocal 實例,Value 是一個線程特有對象。Entry 的作用即是:為其屬主線程建立起一個 ThreadLocal 實例與一個線程特有對象之間的對應關係;
- Entry 對 Key 的引用是弱引用;Entry 對 Value 的引用是強引用。
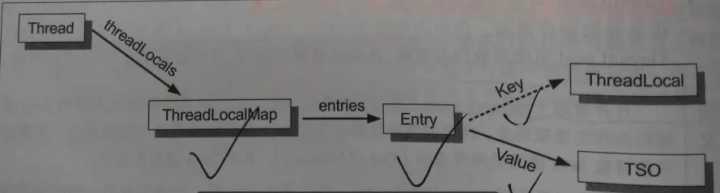
9)Atomic 關鍵字:
答:可以使基本數據類型以原子的方式實現自增自減等操作。參考我的博客:concurrent.atomic 包下的類 AtomicInteger 的使用。
10)線程池有瞭解嗎?(必考)
答:java.util.concurrent.ThreadPoolExecutor 類就是一個線程池。客戶端調用 ThreadPoolExecutor.submit(Runnable task) 提交任務,線程池內部維護的工作者線程的數量就是該線程池的線程池大小,有 3 種形態:
- 當前線程池大小 :表示線程池中實際工作者線程的數量;
- 最大線程池大小 (maxinumPoolSize):表示線程池中允許存在的工作者線程的數量上限;
- 核心線程大小 (corePoolSize ):表示一個不大於最大線程池大小的工作者線程數量上限。
- 如果運行的線程少於 corePoolSize,則 Executor 始終首選添加新的線程,而不進行排隊;
- 如果運行的線程等於或者多於 corePoolSize,則 Executor 始終首選將請求加入隊列,而不是添加新線程;
- 如果無法將請求加入隊列,即隊列已經滿了,則創建新的線程,除非創建此線程超出 maxinumPoolSize, 在這種情況下,任務將被拒絕。
小結:本小節內容涉及到 Java 中多線程編程,線程安全等知識,是面試中的重點和難點。
(四)JVM 記憶體管理
既然是 Java 開發麵試,那麼對 JVM 的考察當然也是必須的,面試官一般會問你對 JVM 有瞭解嗎?
我通常都會把我所瞭解的都說一遍,包括:JVM 記憶體劃分、JVM 垃圾回收的含義,有哪些 GC 演算法,年輕代和老年代各自的特點統統闡述一遍。
1)JVM 記憶體劃分:
- 方法區(線程共用):常量、靜態變數、JIT(即時編譯器) 編譯後的代碼也都在方法區;
- 堆記憶體(線程共用):垃圾回收的主要場所;
- 程式計數器: 當前線程執行的位元組碼的位置指示器;
- 虛擬機棧(棧記憶體):保存局部變數、基本數據類型變數以及堆記憶體中某個對象的引用變數;
- 本地方法棧 :為 JVM 提供使用 native 方法的服務。
2)類似-Xms、-Xmn 這些參數的含義:
答:
堆記憶體分配:
- JVM 初始分配的記憶體由-Xms 指定,預設是物理記憶體的 1/64;
- JVM 最大分配的記憶體由-Xmx 指定,預設是物理記憶體的 1/4;
- 預設空餘堆記憶體小於 40% 時,JVM 就會增大堆直到-Xmx 的最大限制;空餘堆記憶體大於 70% 時,JVM 會減少堆直到 -Xms 的最小限制;
- 因此伺服器一般設置-Xms、-Xmx 相等以避免在每次 GC 後調整堆的大小。對象的堆記憶體由稱為垃圾回收器的自動記憶體管理系統回收。
非堆記憶體分配:
- JVM 使用-XX:PermSize 設置非堆記憶體初始值,預設是物理記憶體的 1/64;
- 由 XX:MaxPermSize 設置最大非堆記憶體的大小,預設是物理記憶體的 1/4;
- -Xmn2G:設置年輕代大小為 2G;
- -XX:SurvivorRatio,設置年輕代中 Eden 區與 Survivor 區的比值。
3)垃圾回收演算法有哪些?
答:
- 引用計數 :原理是此對象有一個引用,即增加一個計數,刪除一個引用則減少一個計數。垃圾回收時,只用收集計數為 0 的對象。此演算法最致命的是無法處理迴圈引用的問題;
- 標記-清除 :此演算法執行分兩階段。第一階段從引用根節點開始標記所有被引用的對象,第二階段遍歷整個堆,把未標記的對象清除;
此演算法需要暫停整個應用,同時,會產生記憶體碎片;
- 複製演算法 :此演算法把記憶體空間劃為兩個相等的區域,每次只使用其中一個區域。垃圾回收時,遍歷當前使用區域,把正在使用中的對象複製到另外一個區域中;
此演算法每次只處理正在使用中的對象,因此複製成本比較小,同時複製過去以後還能進行相應的記憶體整理,不會出現 “碎片” 問題。當然,此演算法的缺點也是很明顯的,就是需要兩倍記憶體空間;
- 標記-整理 :此演算法結合了 “標記-清除” 和 “複製” 兩個演算法的優點。也是分兩階段,第一階段從根節點開始標記所有被引用對象,第二階段遍歷整個堆,把清除未標記對象並且把存活對象 “壓縮” 到堆的其中一塊,按順序排放。
此演算法避免了 “標記-清除” 的碎片問題,同時也避免了 “複製” 演算法的空間問題。
4)root 搜索演算法中,哪些可以作為 root?
答:
- 被啟動類(bootstrap 載入器)載入的類和創建的對象;
- JavaStack 中的引用的對象 (棧記憶體中引用的對象);
- 方法區中靜態引用指向的對象;
- 方法區中常量引用指向的對象;
- Native 方法中 JNI 引用的對象。
5)GC 什麼時候開始?
答:GC 經常發生的區域是堆區,堆區還可以細分為新生代、老年代,新生代還分為一個 Eden 區和兩個 Survivor 區。
- 對象優先在 Eden 中分配,當 Eden 中沒有足夠空間時,虛擬機將發生一次 Minor GC,因為 Java 大多數對象都是朝生夕滅,所以 Minor GC 非常頻繁,而且速度也很快;
- Full GC,發生在老年代的 GC,當老年代沒有足夠的空間時即發生 Full GC,發生 Full GC 一般都會有一次 Minor GC。
大對象直接進入老年代,如很長的字元串數組,虛擬機提供一個;XX:PretenureSizeThreadhold 參數,令大於這個參數值的對象直接在老年代中分配,避免在 Eden 區和兩個 Survivor 區發生大量的記憶體拷貝;
- 發生 Minor GC 時,虛擬機會檢測之前每次晉升到老年代的平均大小是否大於老年代的剩餘空間大小,如果大於,則進行一次 Full GC,如果小於,則查看 HandlePromotionFailure 設置是否允許擔保失敗,如果允許,那隻會進行一次 Minor GC,如果不允許,則改為進行一次 Full GC。
6)記憶體泄漏和記憶體溢出
答:
概念:
- 記憶體溢出指的是記憶體不夠用了;
- 記憶體泄漏是指對象可達,但是沒用了。即本該被 GC 回收的對象並沒有被回收;
- 記憶體泄露是導致記憶體溢出的原因之一;記憶體泄露積累起來將導致記憶體溢出。
記憶體泄漏的原因分析:
- 長生命周期的對象引用短生命周期的對象;
- 沒有將無用對象置為 null。
小結:本小節涉及到 JVM 虛擬機,包括對記憶體的管理等知識,相對較深。除了以上問題,面試官會繼續問你一些比較深的問題,可能也是為了看看你的極限在哪裡吧。
比如:記憶體調優、記憶體管理,是否遇到過記憶體泄漏的實際案例、是否真正關心過記憶體等。由於本人實際項目經驗不足,這些深層次問題並沒有接觸過,各位有需要可以上網查閱。
(五)Java 8 相關知識點
關於 Java8 中新知識點,面試官會讓你說說 Java8 你瞭解多少,下邊主要闡述我所瞭解,並且在面試中回答的 Java8 新增知識點。
1)HashMap 的底層實現有變化:HashMap 是數組 + 鏈表 + 紅黑樹(JDK1.8 增加了紅黑樹部分)實現。
2)JVM 記憶體管理方面,由元空間代替了永久代。
區別:
- 元空間並不在虛擬機中,而是使用本地記憶體;
- 預設情況下,元空間的大小僅受本地記憶體限制;
- 也可以通過-XX:MetaspaceSize 指定元空間大小。
3)Lambda 表達式(也稱為閉包),允許我們將函數當成參數傳遞給某個方法,或者把代碼本身當做數據處理。
4)函數式介面:指的是只有一個函數的介面,java.lang.Runnable 和 java.util.concurrent.Callable 就是函數式介面的例子;java8 提供了一個特殊的註解 @Functionallnterface 來標明該介面是一個函數式介面。
5)引入重覆註解:Java 8 中使用 @Repeatable 註解定義重覆註解。
6)介面中可以實現方法 default 方法。
7) 註解的使用場景拓寬: 註解幾乎可以使用在任何元素上:局部變數、介面類型、超類和介面實現類,甚至可以用在函數的異常定義上。
8) 新的包 java.time 包
- 包含了所有關於日期、時間、時區、持續時間和時鐘操作的類;
- 這些類都是不可變的、線程安全的。
小結:Java8 的一些新特性,面試官一般情況下不要求你有多麼精通,主要是看看你有沒有一些瞭解。
(六)網路協議相關
網路協議方面,考察最多的包括伺服器和客戶端在三次握手、四次揮手過程中的狀態變化;還有網路擁塞控制,及其解決辦法等。
1)三次握手、四次揮手示意圖:
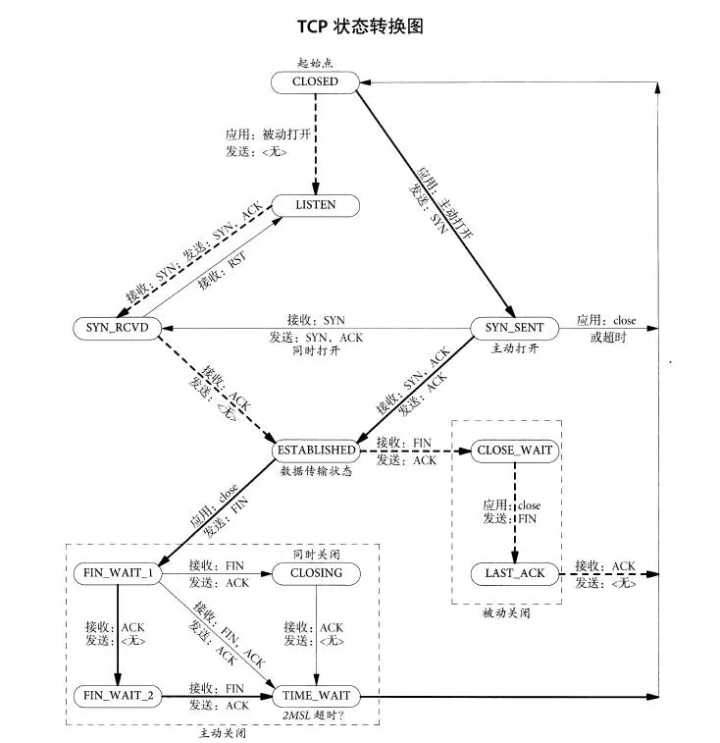
總共有四種狀態:主動建立連接、主動斷開連接、被動建立連和被動斷開連接
兩兩組合還是 4 種組合:
- 主動建立連接、主動斷開連接會經歷的狀態:
SYNC_SENT——ESTABLISHED—-FIN_WAIT_1—-FIN_WAIT_2—-TIME_WAIT - 主動建立連接、被動斷開連接會經歷的狀態:
SYNC_SENT——ESTABLISHED—-CLOSE_WAIT—-LAST_ACK - 被動建立連接、主動斷開連接會經歷的狀態:
LISTEN—-SYN_RCVD—-ESTABLISHED—-FIN_WAIT_1—-FIN_WAIT_2—-TIME_WAIT - 被動建立連接、被動斷開連接會經歷的狀態:
LISTEN—-SYN_RCVD—-ESTABLISHED—-CLOSE_WAIT—-LAST_ACK
2)滑動視窗機制
由發送方和接收方在三次握手階段,互相將自己的最大可接收的數據量告訴對方。也就是自己的數據接收緩衝池的大小。這樣對方可以根據已發送的數據量來計算是否可以接著發送。
在處理過程中,當接收緩衝池的大小發生變化時,要給對方發送更新視窗大小的通知。
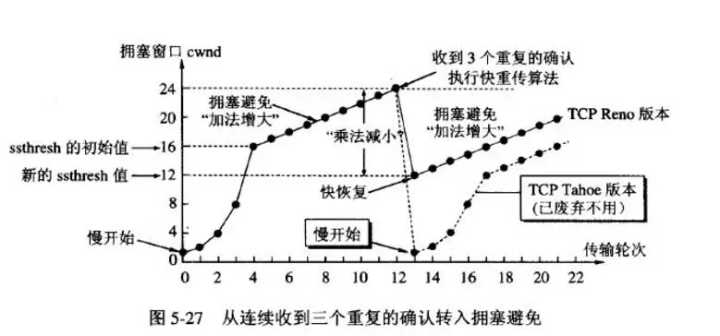
3)擁塞避免機制
擁塞:對資源的需求超過了可用的資源。若網路中許多資源同時供應不足,網路的性能就要明顯變壞,整個網路的吞吐量隨之負荷的增大而下降。
擁塞控制:防止過多的數據註入到網路中,使得網路中的路由器或鏈路不致過載。
擁塞控制方法:
- 慢開始 + 擁塞避免;
- 快重傳 + 快恢復。

4)瀏覽器中輸入:“www.xxx.com” 之後都發生了什麼?請詳細闡述。
解析:經典的網路協議問題。
答:
- 由功能變數名稱→IP 地址
尋找 IP 地址的過程依次經過了瀏覽器緩存、系統緩存、hosts 文件、路由器緩存、 遞歸搜索根功能變數名稱伺服器。 - 建立 TCP/IP 連接(三次握手具體過程)
- 由瀏覽器發送一個 HTTP 請求
- 經過路由器的轉發,通過伺服器的防火牆,該 HTTP 請求到達了伺服器
- 伺服器處理該 HTTP 請求,返回一個 HTML 文件
- 瀏覽器解析該 HTML 文件,並且顯示在瀏覽器端
- 這裡需要註意:
- HTTP 協議是一種基於 TCP/IP 的應用層協議,進行 HTTP 數據請求必須先建立 TCP/IP 連接
- 可以這樣理解:HTTP 是轎車,提供了封裝或者顯示數據的具體形式;Socket 是發動機,提供了網路通信的能力。
- 兩個電腦之間的交流無非是兩個埠之間的數據通信 , 具體的數據會以什麼樣的形式展現是以不同的應用層協議來定義的。
5)常見 HTTP 狀態碼
- 1xx(臨時響應)
- 2xx(成功)
- 3xx(重定向):表示要完成請求需要進一步操作
- 4xx(錯誤):表示請求可能出錯,妨礙了伺服器的處理
- 5xx(伺服器錯誤):表示伺服器在嘗試處理請求時發生內部錯誤
- 常見狀態碼:
- 200(成功)
- 304(未修改):自從上次請求後,請求的網頁未修改過。伺服器返回此響應時,不會返回網頁內容
- 401(未授權):請求要求身份驗證
- 403(禁止):伺服器拒絕請求
- 404(未找到):伺服器找不到請求的網頁
6)TCP 和 UDP 的區別:
答:
- 回答發送數據前是否存在建立連接的過程;
- TCP過確認機制,丟包可以重發,保證數據的正確性;UDP不保證正確性,只是單純的負責發送數據包;
- UDP 是面向報文的。發送方的 UDP 對應用程式交下來的報文,在添加首部後就向下交付給 IP 層。既不拆分,也不合併,而是保留這些報文的邊界,因 此,應用程式需要選擇合適的報文大小;
- UDP 的頭部,只有 8 個位元組,相對於 TCP 頭部的 20 個位元組信息包的額外開銷很小。
限於篇幅,更多網路協議相關知識,請參閱我的博客:TCP/IP 協議面試常問知識點,傾心總結
小結:必須熟練掌握 TCP 和 UDP 的區別、三次握手和四次揮手的狀態切換,必考。
(七)資料庫知識點
既然是後端開發,那麼與資料庫相關的知識點也是必不可少的。
1)MySQL 和 MongoDB 的區別有哪些?如何選擇?
2)MongoDB 的優缺點有哪些?
(ps 本人對這一塊不是很熟悉,就不附上參考答案了,請各位小伙伴自行學習哈~)
3)聽說過事務嗎?(必考)
答:作為單個邏輯工作單元執行的一系列操作,滿足四大特性:
- 原子性(Atomicity):事務作為一個整體被執行 ,要麼全部執行,要麼全部不執行;
- 一致性(Consistency):保證資料庫狀態從一個一致狀態轉變為另一個一致狀態;
- 隔離性(Isolation):多個事務併發執行時,一個事務的執行不應影響其他事務的執行;
- 持久性(Durability):一個事務一旦提交,對資料庫的修改應該永久保存。
4)事務的併發問題有哪幾種?
答:丟失更新、臟讀、不可重覆讀以及幻讀。
5)資料庫中的鎖有哪幾種?
答:獨占鎖、排他鎖以及更新鎖。
6)事務的隔離級別有哪幾種?
答:讀未提交、讀已提交、可重覆讀和序列化。
擴展問題:MySQL 事務預設隔離級別是哪個?
答:可重覆讀。
解析:關於問題(4)(5)(6)的詳細解答,請參閱我的博客:資料庫併發機制和事務的隔離級別詳解
(ps,關於資料庫事務方面的深層次考察還有分散式事務即兩段提交和三段提交等,限於本人水平,請各位自行學習)
7)資料庫的索引有什麼作用?(必考) 底層數據結構是什麼,為什麼使用這種數據結構?
答:
- 索引 是對資料庫表中一列或多列的值進行排序的一種結構,使用索引可快速訪問資料庫表中的特定信息;
- 底層數據結構是 B+ 樹;
- 使用 B+ 樹的原因:查找速度快、效率高,在查找的過程中,每次都能拋棄掉一部分節點,減少遍歷個數。( 此時,你應該在白紙上畫出什麼是 B+ 樹 )
擴展問題:聚簇索引和非聚簇索引的區別?
8)MyISAM 和 InnoDB 的區別有哪些?
答:
- MyISAM 不支持事務,InnoDB 是事務類型的存儲引擎;
- MyISAM 只支持表級鎖,BDB 支持頁級鎖和表級鎖,預設為頁級鎖;而 InnoDB 支持行級鎖和表級鎖,預設為行級鎖;
- MyISAM 引擎不支持外鍵,InnoDB 支持外鍵;
- MyISAM 引擎的表在大量高併發的讀寫下會經常出現表損壞的情況;
- 對於 count( ) 查詢來說 MyISAM 更有優勢;
- InnoDB 是為處理巨大數據量時的最大性能設計,它的 CPU 效率可能是任何其它基於磁碟的關係資料庫引擎所不能匹敵的;
- MyISAM 支持全文索引(FULLTEXT),InnoDB 不支持;
- MyISAM 引擎的表的查詢、更新、插入的效率要比 InnoDB 高。
最主要的區別是:MyISAM 表不支持事務、不支持行級鎖、不支持外鍵。 InnoDB 表支持事務、支持行級鎖、支持外鍵。(可直接回答這個)
9)資料庫中 Where、group by、having 關鍵字:
答: 關鍵字作用:
- where 子句用來篩選 from 子句中指定的操作所產生的的行;
- group by 子句用來分組 where 子句的輸出;
- having 子句用來從分組的結果中篩選行;
having 和 where 的區別:
- 語法類似,where 搜索條件在進行分組操作之前應用;having 搜索條件在進行分組操作之後應用;
- having 可以包含聚合函數 sum、avg、max 等;
- having 子句限制的是組,而不是行。
當同時含有 where 子句、group by 子句 、having 子句及聚集函數時,執行順序如下:
- 執行 where 子句查找符合條件的數據;
- 使用 group by 子句對數據進行分組;對 group by 子句形成的組運行聚集函數計算每一組的值;最後用 having 子句去掉不符合條件的組。
10)還有一些問題,如 MySQL 和 SQL Server 用法上的區別、limit 關鍵字的使用等問題。
小結:資料庫方面還是事務機制、隔離級別比較重要,當然了資料庫索引是必考的問題。偶爾也會給你幾個表,讓你現場寫 SQL 語句,主要考察 group by 和 having 等關鍵字。
(八)MVC 框架相關知識點
我在項目中使用的框架有 Spring MVC 和 MyBatis,所以在簡歷上只寫了這兩種框架,面試官主要針對這兩種框架進行提問。以下問題供小伙伴們參考。
JavaWeb 開發經典的 3 層框架:Web 層、Service 層(業務邏輯層)和 Dao 層(數據訪問層)
- Web 層:包含 JSP 和 Servlet 等與 Web 相關的內容;
- 業務層:只關心業務邏輯;
- 數據層:封裝了對資料庫的訪問細節。
Spring 知識點
1)Spring 的 IOC 和 AOP 有瞭解嗎?
答:
- IOC:控制反轉,(解耦合)將對象間的依賴關係交給 Spring 容器,使用配置文件來創建所依賴的對象,由主動創建對象改為了被動方式;
- AOP:面向切麵編程,將功能代碼從業務邏輯代碼中分離出來。
2)AOP 的實現方式有哪幾種?如何選擇?(必考)
答:JDK 動態代理實現和 cglib 實現。
選擇:
- 如果目標對象實現了介面,預設情況下會採用 JDK 的動態代理實現 AOP,也可以強制使用 cglib 實現 AOP;
- 如果目標對象沒有實現介面,必須採用 cglib 庫,Spring 會自動在 JDK 動態代理和 cglib 之間轉換。
擴展:JDK 動態代理如何實現?(加分點)
答:JDK 動態代理,只能對實現了介面的類生成代理,而不是針對類,該目標類型實現的介面都將被代理。原理是通過在運行期間創建一個介面的實現類來完成對目標對象的代理。
- 定義一個實現介面 InvocationHandler 的類;
- 通過構造函數,註入被代理類;
- 實現 invoke( Object proxy, Method method, Object[] args)方法;
- 在主函數中獲得被代理類的類載入器;
- 使用 Proxy.newProxyInstance( ) 產生一個代理對象;
- 通過代理對象調用各種方法。
解析:關於 IOC 和 AOP 的詳細闡述,請各位參閱我的博客:Spring 核心 AOP(面向切麵編程)總結,Spring 框架學習—控制反轉(IOC)
3)Spring MVC 的核心控制器是什麼?消息處理流程有哪些?
答:核心控制器為 DispatcherServlet。消息流程如下:

4)其他問題包括:重定向和轉發的區別、動態代理和靜態代理的區別等。
Mybatis 知識點
關於 MyBatis 主要考察占位符#和 $ 的區別,區別如下:
- 符號將傳入的數據都當做一個字元串,會對自動傳入的數據加一個雙引號;
- $ 符號將傳入的數據直接顯示生成 SQL 中;
- 符號存在預編譯的過程,,對問號賦值,防止 SQL 註入;
- $ 符號是直譯的方式,一般用在 order by ${列名}語句中;
- 能用#號就不要用 $ 符號。
小結:限於作者水平,MVC 框架方面瞭解不是太多,實戰能力欠缺。面試官偶爾問框架底層實現原理等都知之甚少,有能力的小伙伴可以多加學習。
(九)大數據相關知識點
大數據相關是因為我的簡歷上寫了 KafKa 相關項目,所以面試官會進行提問 KafKa 相關知識點,我也進行了一些簡單概念總結,深層次的實現原理因為並沒有特別多的實戰經驗,所以並不瞭解。
以下概念總結供小伙伴參考。
1)KafKa 基本特性:
答:快速持久化、支持批量讀寫消息、支持消息分區,提高了併發能力、支持線上增加分區、支持為每個分區創建多個副本。
擴展:為什麼可以實現快速持久化?
答:KafKa 將消息保存在磁碟中,並且讀寫磁碟的方式是順序讀寫,避免了隨機讀寫磁碟(尋道時間過長)導致的性能瓶頸;磁碟的順序讀寫速度超過記憶體隨機讀寫。
2)核心概念:
答:
- 生產者(Producer): 生產消息,並且按照一定的規則推送到 Topic 的分區中。
- 消費者(Consumer): 從 Topic 中拉去消息,並且進行消費。
- 主題(Topic): 用於存儲消息的邏輯概念,是一個消息集合。
- 分區(partition):
- 每個 Topic 可以劃分為多個分區,每個消息在分區中都會有一個唯一編號 offset
- kafka 通過 offset 保證消息在分區中的順序
- 同一 Topic 的不同分區可以分配在不同的 Broker 上
- partition 以文件的形式存儲在文件系統中。
副本(replica):
- KafKa 對消息進行了冗餘備份,每個分區有多個副本,每個副本中包含的消息是 “一樣” 的。
- 每個副本中都會選舉出一個 Leader 副本,其餘為 Follower 副本,Follower 副本僅僅將數據從 Leader 副本拉去到本地,然後同步到自己的 Log 中。
消費者組(Consumer Group): 每個 consumer 都屬於一個 consumer group,每條消息只能被 consumer group 中的一個 Consumer 消費,但可以被多個 consumer group 消費。
Broker:
- 一個單獨的 server 就是一個 Broker;
- 主要工作:接收生產者發過來的消息,分配 offset,並且保存到磁碟中;
Cluster&Controller:
- 多個 Broker 可以組成一個 Cluster,每個集群選舉一個 Broker 來作為 Controller,充當指揮中心
- Controller 負責管理分區的狀態,管理每個分區的副本狀態,監聽 ZooKeeper 中數據的變化等工作
保留策略和日誌壓縮:
- 不管消費者是否已經消費了消息,KafKa 都會一直保存這些消息(持久化到磁碟);
- 通過保留策略,定時刪除陳舊的消息;
- 日誌壓縮,只保留最新的 Key-Value 對。
關於副本機制:(加分點)
ISR 集合 :表示當前 “可用” 且消息量與 Leader 相差不多的副本集合。滿足條件如下:
- 副本所在節點必須維持著與 ZooKeeper 的連接;
- 副本最後一條信息的 offset 與 Leader 副本的最後一條消息的 offset 之間的差值不能超過指定的閾值。
HW&LEO:
- HW 標記了一個特殊的 offset,當消費者處理消息的時候,只能拉取到 HW 之前的消息;
- HW 也是由 Leader 副本管理的;
- LEO(Log End Offset)是所有副本都會有的一個 offset 標記。
ISR、HW 和 LEO 的工作配合:
- producer 向此分區中推送消息;
- Leader 副本將消息追加到 Log 中,並且遞增其 LEO;
- Follower 副本從 Leader 副本中拉取消息進行同步;
- Follower 副本將消息更新到本地 Log 中,並且遞增其 LEO;
- 當 ISR 集合中的所有副本都完成了對 offset 的消息同步,Leader 副本會遞增其 HW
KafKa 的容災機制: 通過分區的副本 Leader 副本和 Follower 副本來提高容災能力。
小結:請小伙伴根據自己的簡歷自行準備學習大數據相關知識點。
(十)Linux 常見命令
作者對這一方面不是很精通,知識點來源於網路總結以及面試官的提問,僅供小伙伴參考。
1)grep、sed 以及 awk 命令
解析:awk 命令如果可以掌握,是面試中的一個 加分點。
2)文件和目錄:
pwd 顯示當前目錄
ls 顯示當前目錄下的文件和目錄:
- ls -F 可以區分文件和目錄;
- ls -a 可以把隱藏文件和普通文件一起顯示出來;
- ls -R 可以遞歸顯示子目錄中的文件和目錄;
- ls -l 顯示長列表;
- ls -l test 過濾器,查看某個特定文件信息。可以只查看 test 文件的信息。
3)處理文件方面的命令有:touch、cp、 In、mv、rm、
4)處理目錄方面的命令:mkdir
5)查看文件內容:file、cat、more、less、tail、head
6)監測程式命令:ps、top
eg. 找出進程名中包括 java 的所有進程:ps -ef | grep java
top 命令 實時監測進程
top 命令輸出的第一部分:顯示系統的概括。
- 第一行顯示了當前時間、系統的運行時間、登錄的用戶數和系統的平均負載(平均負載有 3 個值:最近 1min 5min 15min);
- 第二行顯示了進程的概要信息,有多少進程處於運行、休眠、停止或者僵化狀態;
- 第三行是 CPU 的概要信息;
- 第四行是系統記憶體的狀態。
7)ps 和 top 命令的區別:
- ps 看到的是命令執行瞬間的進程信息 , 而 top 可以持續的監視;
- ps 只是查看進程 , 而 top 還可以監視系統性能 , 如平均負載 ,cpu 和記憶體的消耗;
- 另外 top 還可以操作進程 , 如改變優先順序 (命令 r) 和關閉進程 (命令 k);
- ps 主要是查看進程的,關註點在於查看需要查看的進程;
- top 主要看 cpu, 記憶體使用情況,及占用資源最多的進程由高到低排序,關註點在於資源占用情況。
8) 壓縮數據
- tar -xvf 文件名;
- tar -zxvf 文件名;
- tar -cvzf 文件名。
9)結束進程:kill PID 或者 kill all
至此,從十個不同的方面闡述了 Java 開發麵試崗位中所涉及到的重要知識點。加上我上次發佈的 關於演算法面試的 chat,我大概將最近一年的時間內的面試筆試經驗給大家做了總結分享。
接下來,為了給大家提供更多的幫助,我想針對簡歷方面和大家聊聊,主要包括: 製作簡歷和投遞簡歷兩方面。
製作簡歷:
首先,我想先介紹下我的簡歷都包括哪些部分:
- 個人信息
- 教育背景
- 個人亮點
- 實習項目
- 校內項目
- 獎勵、語言及 IT 能力
- 個人綜述
簡歷應該突出表現自己優秀的地方,所以我將個人技術博客和 github 地址放到了相對靠前的位置,使面試官或者 HR 可以一眼看到。
各位小伙伴如果在校期間參加過什麼大型競賽並且獲獎,也可以寫在明顯的位置。
給大家一個小提示,那就是必須對簡歷上所寫的知識點有一定瞭解,不懂的就不要寫上去了,因為你會被問的很慘(即使一面面試官不問,三面面試官也會問的)。
比如說你在簡歷上寫了一個技術 A,說自己在項目中使用過技術 A,那麼面試官就會問該技術 A 的底層實現、原理等等。
如果你回答出來,確實,這是加分項,但是很多時候我們是回答不出來的。
投遞簡歷
投遞簡歷同樣很重要,對於並不是出身名校的小伙伴來說,在投遞一些互聯網公司的時候,可能會面臨著簡歷被刷的可能。這時候內推的重要性就體現出來了。
內推是內部推薦的意思, 內推的好處一般有兩種:
- 內推免簡歷篩選,直接進入筆試環節;
- 內推可以直接獲得面試資格,面試失敗可以繼續參加後續校招大流程。
內推時間點:
- 暑期實習校園招聘的內推一般從每年 3 月份開始;
- 秋招的內推從每年 8 月份開始,持續到九月份。
如何內推?
內推,意味著你要找到公司內部人員進行推薦,內推渠道主要是找自己的師兄師姐。另外可以時常關註號稱 “全國最大的高校論壇”- 北郵人論壇 。
北郵人論壇資源相當豐富,每年招聘季的內推帖子數不勝數,各位如果有需要,可以關註一下。在牛客網以及賽碼網的討論區內也存在著大量的內推消息,大家可以關註。
結束語
這是一篇很長的文章,然而,再長的文章也道不盡我這一年中面試筆試的所有經歷。找工作是一場持久戰,堅持到最後的才是勝利者。
對於各位志在投身 Java 開發崗位的小伙伴們來說,本文所提到的知識點絕對是面試中的重點,希望各位可以有效掌握。
(限於作者水平,文中如有錯誤之處,煩請各位指出,我們一起進步。)
我有一個微信公眾號,經常會分享一些Java技術相關的乾貨。如果你喜歡我的分享,可以用微信搜索“Java團長”或者“javatuanzhang”關註。

- 原作者姓名:楊小強
- 原出處:CSDN
- 原文鏈接:知名互聯網公司校招 Java 開發崗面試知識點解析


