
大數據:Hadoop入門 一:什麼是大數據 (1.)大數據是指在一定時間內無法用常規軟體對其內容進行抓取,管理和處理的數據集合,簡而言之就是數據量非常大,大到無法用常規工具進行處理,如關係型資料庫,數據倉庫等。這裡“大”是一個什麼量級呢?如在阿裡巴巴每天處理數據達到20PB(即20971520GB) ...
大數據:Hadoop入門
一:什麼是大數據
- 什麼是大數據:
(1.)大數據是指在一定時間內無法用常規軟體對其內容進行抓取,管理和處理的數據集合,簡而言之就是數據量非常大,大到無法用常規工具進行處理,如關係型資料庫,數據倉庫等。這裡“大”是一個什麼量級呢?如在阿裡巴巴每天處理數據達到20PB(即20971520GB).
2.大數據的特點:
(1.)體量巨大。按目前的發展趨勢來看,大數據的體量已經到達PB級甚至EB級。
(2.)大數據的數據類型多樣,以非結構化數據為主,如網路雜誌,音頻,視屏,圖片,地理位置信息,交易數據,社交數據等。
(3.)價值密度低。有價值的數據僅占到總數據的一小部分。比如一段視屏中,僅有幾秒的信息是有價值的。
(4.)產生和要求處理速度快。這是大數據區與傳統數據挖掘最顯著的特征。
3.除此之外還有其他處理系統可以處理大數據。
Hadoop (開源)
Spark(開源)
Storm(開源)
MongoDB(開源)
IBM PureDate(商用)
Oracle Exadata(商用)
SAP Hana(商用)
Teradata AsterData(商用)
EMC GreenPlum(商用)
HP Vertica(商用)
註:這裡我們只介紹Hadoop。
二:Hadoop體繫結構
- Hadoop來源:
Hadoop源於Google在2003到2004年公佈的關於GFS(Google File System),MapReduce和BigTable的三篇論文,創始人Doug Cutting。Hadoop現在是Apache基金會頂級項目,“Hadoop”一個虛構的名字。由Doug Cutting的孩子為其黃色玩具大象所命名。
- Hadoop的核心:
(1.)HDFS和MapReduce是Hadoop的兩大核心。通過HDFS來實現對分散式儲存的底層支持,達到高速並行讀寫與大容量的儲存擴展。
(2.)通過MapReduce實現對分散式任務進行處理程式支持,保證高速分區處理數據。
3.Hadoop子項目:

(1.)HDFS:分散式文件系統,整個Hadoop體系的基石。
(2.)MapReduce/YARN:並行編程模型。YARN是第二代的MapReduce框架,從Hadoop 0.23.01版本後,MapReduce被重構,通常也稱為MapReduce V2,老MapReduce也稱為 MapReduce V1。
(3.)Hive:建立在Hadoop上的數據倉庫,提供類似SQL語音的查詢方式,查詢Hadoop中的數據,
(4.)Pig:一個隊大型數據進行分析和評估的平臺,主要作用類似於資料庫中儲存過程。
(5.)HBase:全稱Hadoop Database,Hadoop的分散式的,面向列的資料庫,來源於Google的關於BigTable的論文,主要用於隨機訪問,實時讀寫的大數據。
(6.)ZooKeeper:是一個為分散式應用所設計的協調服務,主要為用戶提供同步,配置管理,分組和命名等服務,減輕分散式應用程式所承擔的協調任務。
還有其它特別多其它項目這裡不做一一解釋了。
三:安裝Hadoop運行環境
- 用戶創建:
(1.)創建Hadoop用戶組,輸入命令:
groupadd hadoop
(2.)創建hduser用戶,輸入命令:
useradd –p hadoop hduser
(3.)設置hduser的密碼,輸入命令:
passwd hduser
按提示輸入兩次密碼
(4.)為hduser用戶添加許可權,輸入命令:
#修改許可權
chmod 777 /etc/sudoers
#編輯sudoers
Gedit /etc/sudoers
#還原預設許可權
chmod 440 /etc/sudoers
先修改sudoers 文件許可權,併在文本編輯視窗中查找到行“root ALL=(ALL)”,緊跟後面更新加行“hduser ALL=(ALL) ALL”,將hduser添加到sudoers。添加完成後切記還原預設許可權,否則系統將不允許使用sudo命令。
(5.)設置好後重啟虛擬機,輸入命令:
Sudo reboot
重啟後切換到hduser用戶登錄
- 安裝JDK
(1.)下載jdk-7u67-linux-x64.rpm,併進入下載目錄。
(2.)運行安裝命令:
Sudo rpm –ivh jdk-7u67-linux-x64.rpm
完成後查看安裝路徑,輸入命令:
Rpm –qa jdk –l
記住該路徑,
(3.)配置環境變數,輸入命令:
Sudo gedit /etc/profile
打開profile文件在文件最下麵加入如下內容
export JAVA_HOME=/usr/java/jdk.7.0.67
export CLASSPATH=$ JAVA_HOME/lib:$ CLASSPATH
export PATH=$ JAVA_HOME/bin:$PATH
保存後關閉文件,然後輸入命令使環境變數生效:
Source /etc/profile
(4.)驗證JDK,輸入命令:
Java –version
若出現正確的版本則安裝成功。
- 配置本機SSH免密碼登錄:
(1.)使用ssh-keygen 生成私鑰與公鑰文件,輸入命令:
ssh-keygen –t rsa
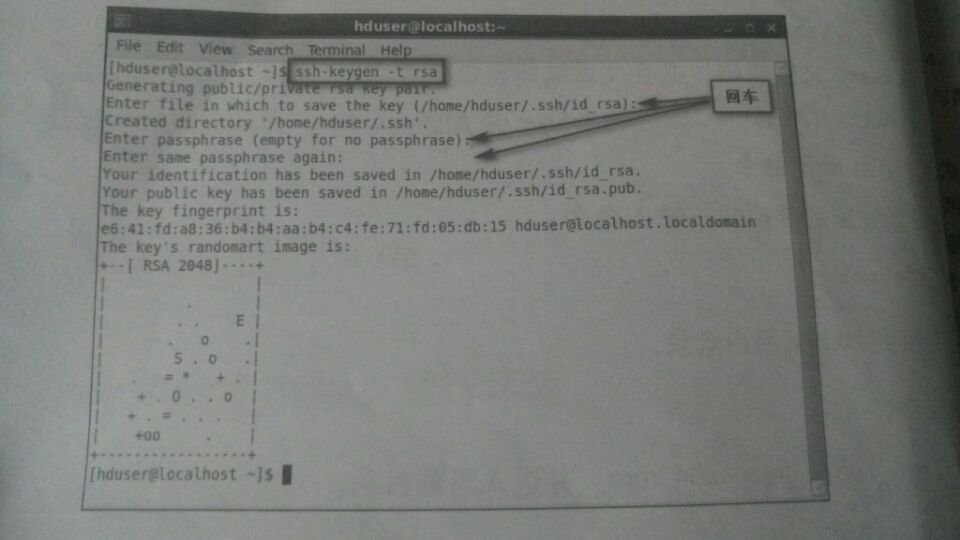
(2.)私鑰留在本機,公鑰發給其它主機(現在是localhost)。輸入命令:
ssh-copy-id localhost
(3.)使用公鑰來登錄輸入命令:
ssh localhost
- 配置其它主機SSH免密登錄
(1.)克隆兩次。在VMware左側欄中選中虛擬機右擊,在彈出的快捷鍵菜單中選中管理---克隆命令。在克隆類型時選中“創建完整克隆”,單擊“下一步”,按鈕直到完成。
(2.)分別啟動併進入三台虛擬機,使用ifconfig查詢個主機IP地址。
(3.)修改每台主機的hostname及hosts文件。
步驟1:修改hostname,分別在各主機中輸入命令。
Sudo gedit /etc/sysconfig/network
步驟2:修改hosts文件:
sudo gedit /etc/hosts
步驟3:修改三台虛擬機的IP
第一臺對應node1虛擬機的IP:192.168.1.130
第二台對應node2虛擬機的IP:192.168.1.131
第三台對應node3虛擬機的IP:192.168.1.132
(4.)由於已經在node1上生成過密鑰對,所有現在只要在node1上輸入命令:
ssh-copy-id node2
ssh-copy-id node3
這樣就可以將node1的公鑰發佈到node2,node3。
(5.)測試SSH,在node1上輸入命令:
ssh node2
#退出登錄
exit
ssh node3
exit
四:Hadoop完全分散式安裝
- 1. Hadoop有三種運行方式:
(1.)單機模式:無須配置,Hadoop被視為一個非分散式模式運行的獨立Java進程
(2.)偽分散式:只有一個節點的集群,這個節點即是Master(主節點,主伺服器)也是Slave(從節點,從伺服器),可在此單節點上以不同的java進程模擬分散式中的各類節點
(3.)完全分散式:對於Hadoop,不同的系統會有不同的節點劃分方式。
2.安裝Hadoop
(1.)獲取Hadoop壓縮包hadoop-2.6.0.tar.gz,下載後可以使用VMWare Tools通過共用文件夾,或者使用Xftp工具傳到node1。進入node1 將壓縮包解壓到/home/hduser目錄下,輸入命令:
#進入HOME目錄即:“/home/hduser”
cd ~
tar –zxvf hadoop-2.6.0.tar.gz
(2.)重命名hadoop輸入命令:
mv hadoop-2.6.0 hadoop
(3.)配置Hadoop環境變數,輸入命令:
Sudo gedit /etc/profile
將以下腳本加到profile內:
#hadoop
export HADOOP_HOME=/home/hduser/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存關閉,最後輸入命令使配置生效
source /etc/profile
註:node2,和node3都要按照以上配置進行配置。
3.配置Hadoop
(1.)hadoop-env.sh文件用於指定JDK路徑。輸入命令:
[hduser@node1 ~]$ cd ~/hadoop/etc/hadoop
[hduser@node1 hadoop]$ gedit hadoop-env.sh
然後增加如下內容指定jDK路徑。
export JAVA_HOME=/usr/java/jdk1.7.0_67
(2.)打開指定JDK路徑,輸入命令:
export JAVA_HOME=/usr/java/jdk1.7.0_67
(3.)slaves:用於增加slave節點即DataNode節點。
[hduser@node1 hadoop]$ gedit slaves
打開並清空原內容,然後輸入如下內容:
node2
node3
表示node2,node3作為slave節點。
(4.)core-site.xml:該文件是Hadoop全局配置,打開併在<configuration>元素中增加配置屬性如下:
<configuration>
<property>
<name>fs.defaultFs</name>
<value>hdfs://node1:9000</value>
</property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/hadoop/tmp</value>
</property>
<configuration>
這裡給出了兩個常用的配置屬性,fs.defaultFS表示客戶端連接HDFS時,預設路徑首碼,9000是HDFS工作的埠。Hadoop.tmp.dir如不指定會保存到系統的預設臨時文件目錄/tmp中。
(5.)hdfs-site.xml:該文件是hdfs的配置。打開併在<configuration>元素中增加配置屬性。
(6.)mapred-site.xml:該文件是MapReduce的配置,可從模板文件mapred-site.xml.template中複製打開併在<configuration>元素中增加配置。
(7.)yarn-site.xml:如果在mapred-site.xml配置了使用YARN框架,那麼YARN框架就使用此文件中的配置,打開併在<configuration>元素中增加配置屬性。
(8.)複製這七個命令到node2,node3。輸入命令如下:
scp –r /home/hduser/hadoop/etc/hadoop/ hduser@node2:/home/hduser/hadoop/etc/
scp –r /home/hduser/hadoop/etc/hadoop/ hduser@node3:/home/hduser/hadoop/etc/
4.驗證:
下麵驗證hadoop是否正確
(1.)在Master主機(node1)上格式化NameNode。輸入命令:
[hduser@node1 ~]$ cd ~/hadoop
[hduser@node1 hadoop]$ bin/hdfs namenode –format
(2)關閉node1,node2 ,node3,系統防火牆並重啟虛擬機。輸入命令:
service iptables stop
sudo chkconfig iptables off
reboot
(3.)輸入以下啟動HDFS:
[hduser@node1 ~]$ cd ~/hadoop
(4.)啟動所有
[hduser@node1 hadoop]$ sbin/start-all.sh
(5.)查看集群狀態:
[hduser@node1 hadoop]$ bin/hdfs dfsadmin –report
(6.)在瀏覽器中查看hdfs運行狀態,網址:http://node1:50070
(7.)停止Hadoop。輸入命令:
[hduser@node1 hadoop]$ sbin/stop-all.sh
五:Hadoop相關的shell操作
(1.)在操作系統中/home/hduser/file目錄下創建file1.txt,file2.txt可使用圖形界面創建。
file1.txt輸入內容:
Hello World hi HADOOP
file2.txt輸入內容
Hello World hi CHIAN
(2.)啟動hdfs後創建目錄/input2
[hduser@node1 hadoop]$ bin/hadoop fs –mkdir /input2
(3.)將file1.txt.file2.txt保存到hdfs中:
[hduser@node1 hadoop]$ bin/hadoop fs –put -/file/file*.txt /input2/
(4.)[hduser@node1 hadoop]$ bin/hadoop fs –ls /input2


