
編寫Python網路爬蟲,爬取新浪新聞首頁新聞列表。有代碼,有詳細步驟,有截圖,歡迎嘗試! ...
引言:
昨天在網易雲課堂自學了《Python網路爬蟲實戰》,視頻鏈接 老師講的很清晰,跟著實踐一遍就能掌握爬蟲基礎了,強烈推薦!
另外,在網上看到一位學友整理的課程記錄,非常詳細,可以優先參考學習。傳送門:請點擊
本篇文章是自己同步跟著視頻學習的記錄,歡迎閱讀~~~
實驗:新浪新聞首頁爬蟲實踐
http://news.sina.com.cn/china/
一、準備
-
瀏覽器內建的開發人員工具(以Chrome為例)
-
Python3 requests 庫
-
Python3 BeautifulSoup4 庫(註意,BeautifulSoup4和BeautifulSoup是不一樣的)
-
jupyter notebook
二、抓取前的分析
以Chrome為例,抓取前的分析步驟如圖:
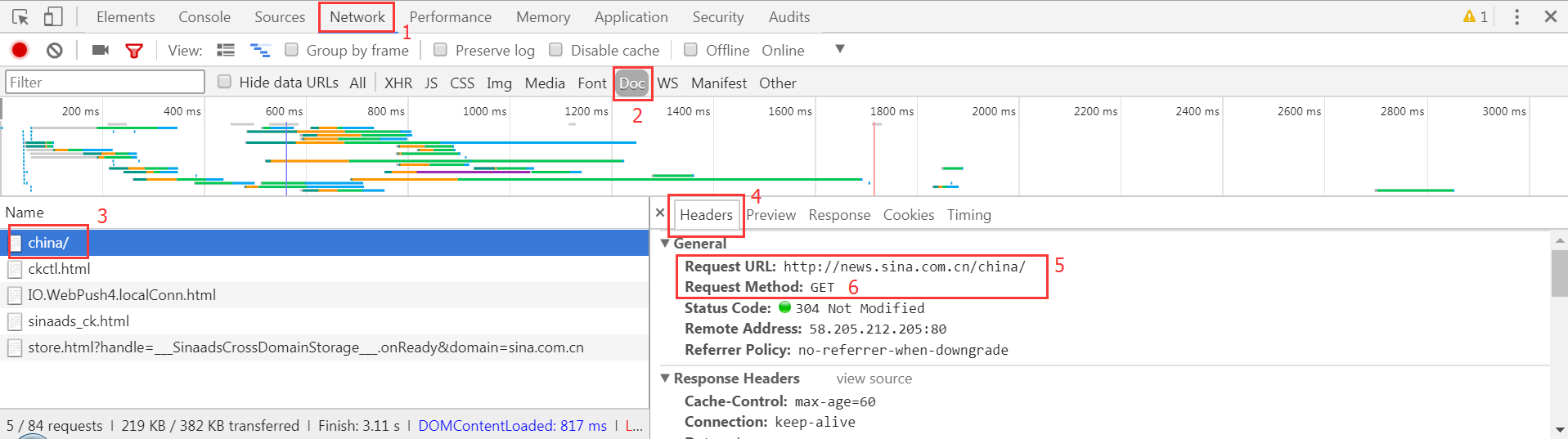
- 按
F12進入到開發者工具; - 點擊
Network; 刷新頁面;(按F5)- 找到
Doc; - 找到左邊
Name這一欄的第一個(需要爬去的鏈接90%的情況都是第一個); - 點擊右邊的
Headers; - 找到請求的URL和請求方式。
三、開始撰寫第一隻網路爬蟲
Requests庫
- 網路資源擷取套件
- 改善Urllib2的缺點,讓使用者以最簡單的方式獲取網路資源
- 可以使用REST操作存取網路資源
jupyter
使用jupyter來抓取網頁並列印在瀏覽器中,再按Ctrl-F查找對應的內容,以確定我們要爬去的內容在該網頁中。
測試示例:
1 import requests 2 res = requests.get('http://www.sina.com.cn/') 3 res.encoding = 'utf-8' 4 print(res.text)
四、用BeautifulSoup4剖析網頁元素
測試示例:
1 from bs4 import BeautifulSoup 2 html_sample = ' \ 3 <html> \ 4 <body> \ 5 <h1 id="title">Hello World</h1> \ 6 <a href="#" class="link">This is link1</a> \ 7 <a href="# link2" class="link">This is link2</a> \ 8 </body> \ 9 </html>' 10 11 soup = BeautifulSoup(html_sample, 'lxml') 12 print(soup.text)
五、BeautifulSoup基礎操作
使用select找出含有h1標簽的元素
soup = BeautifulSoup(html_sample) header = soup.select('h1') print(header) print(header[0]) print(header[0].text)
使用select找出含有a的標簽
soup = BeautifulSoup(html_sample, 'lxml') alink = soup.select('a') print(alink) for link in alink: print(link) print(link.txt)
使用select找出所有id為title的元素(id前面需要加#)
alink = soup.select('#title') print(alink)
使用select找出所有class為link的元素(class前面需要加.)
soup = BeautifulSoup(html_sample) for link in soup.select('.link'): print(link)
使用select找出所有a tag的href鏈接
alinks = soup.select('a') for link in alinks: print(link['href']) # 原理:會把標簽的屬性包裝成字典
六、觀察如何抓取新浪新聞信息
關鍵在於尋找CSS定位
- Chrome開發人員工具(進入開發人員工具後,左上角點選元素觀測,就可以看到了)
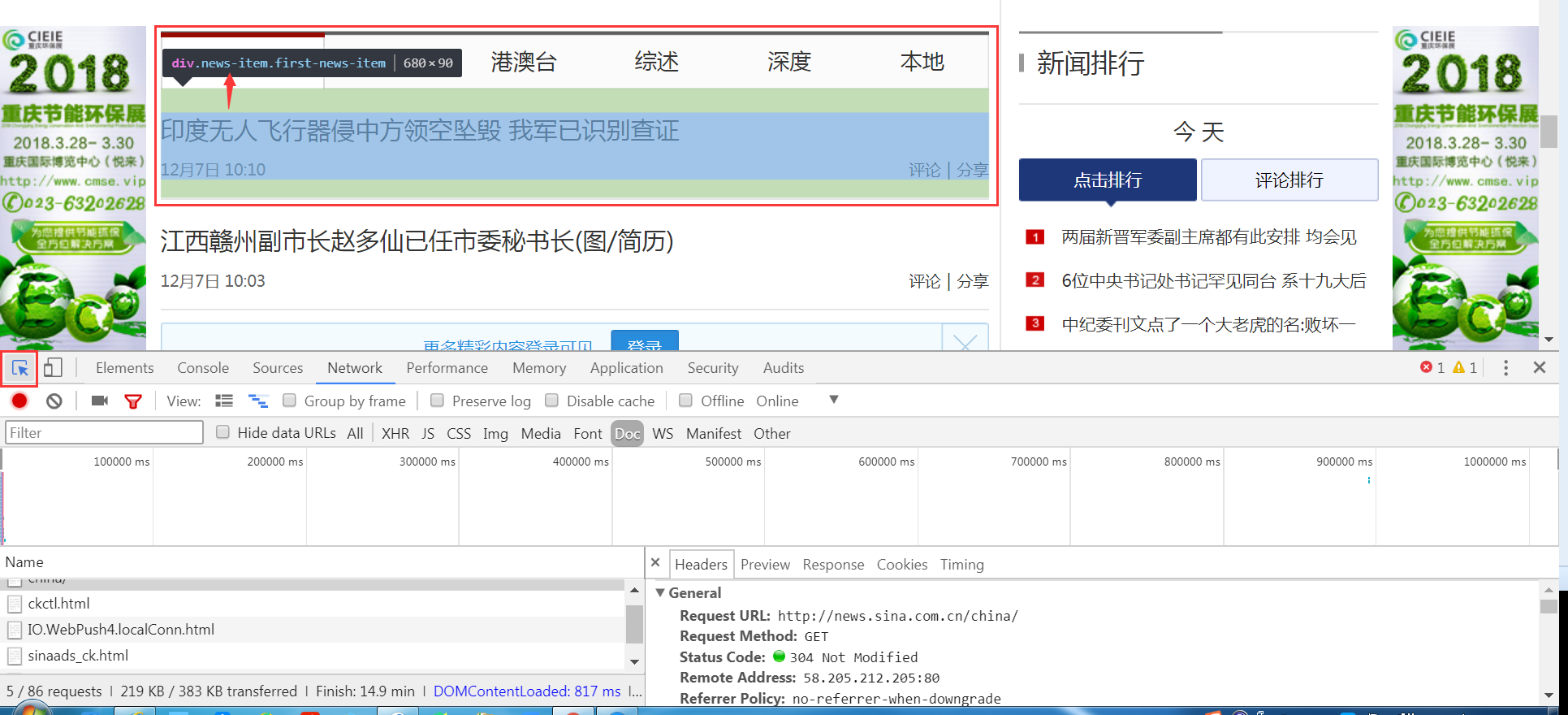
Chrome尋找元素定位.png
- Firefox開發人員工具
- InfoLite(需FQ)
七、製作新浪新聞網路爬蟲
抓取時間、標題、內容
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/china') res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'lxml') for news in soup.select('.news-item'): if (len(news.select('h2')) > 0): h2 = news.select('h2')[0].text time = news.select('.time')[0].text a = news.select('a')[0]['href'] print(time, h2, a)
抓取新聞內文頁面
新聞網址為:http://news.sina.com.cn/o/2017-12-06/doc-ifypnyqi1126795.shtml
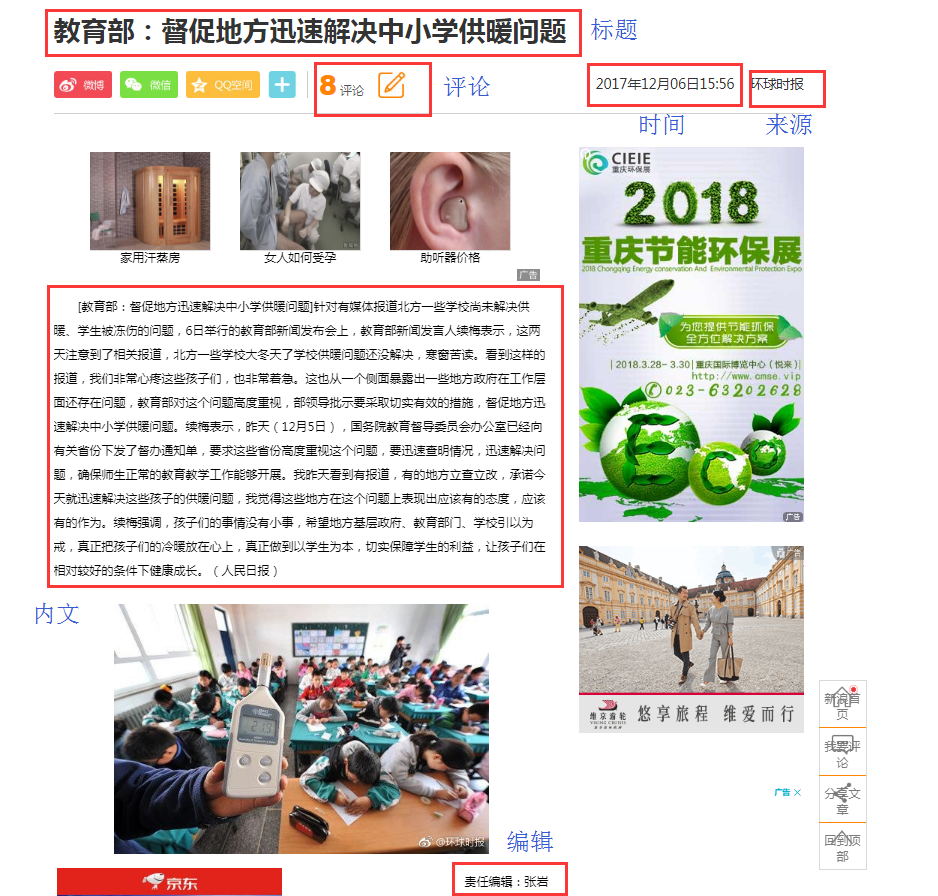
內文資料信息說明圖.png
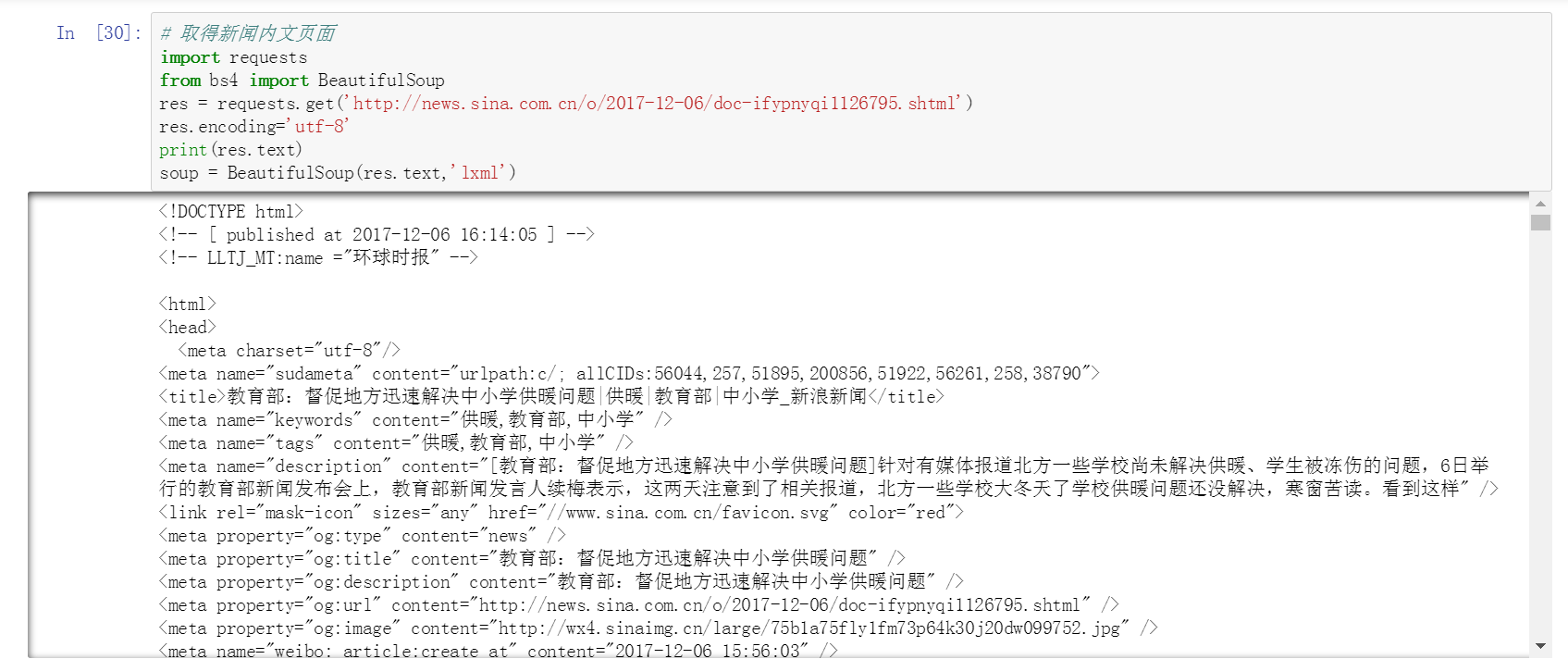
獲取新聞內文標題、時間、來源
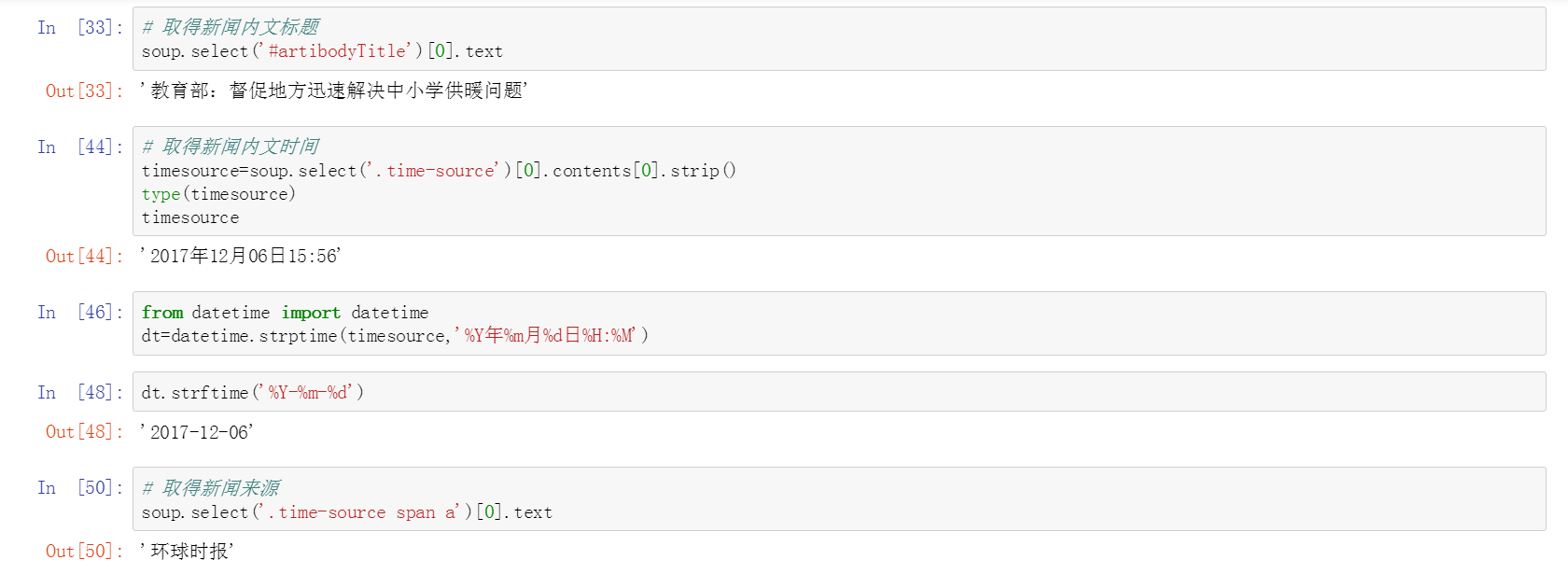
其中涉及時間和字元串轉換
from datetime import datetime // 字元串轉時間 --- strptime dt = datetime.strptime(timesource, '%Y年%m月%d日%H:%M') // 時間轉字元串 --- strftime dt.strftime(%Y-%m-%d)
整理新聞內文、獲取編輯名稱
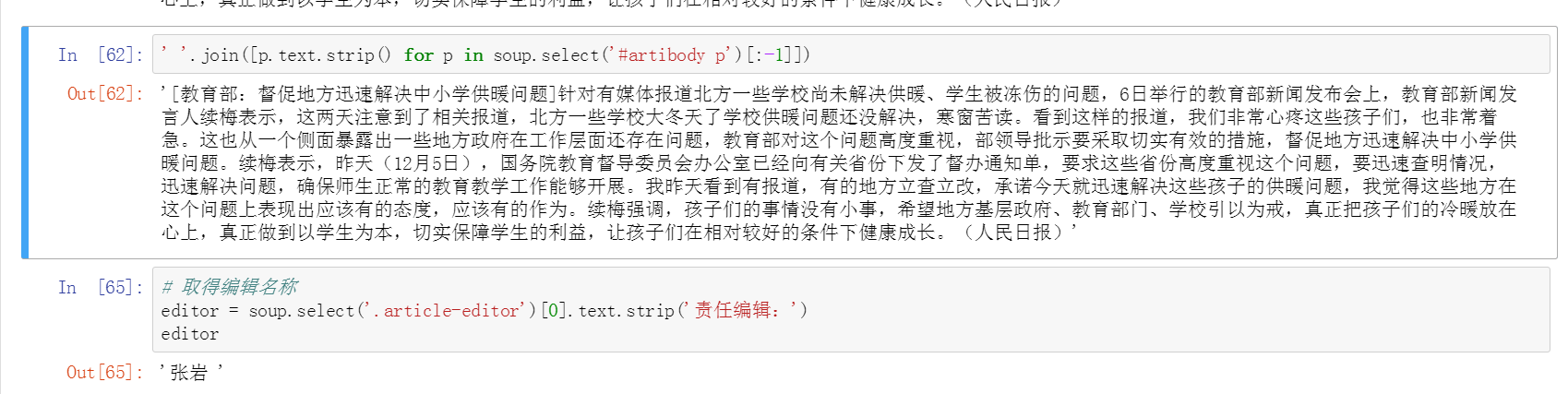
整理新聞內文步驟:
1、抓取;
2、獲取段落;
3、去掉最後一行的編輯者信息;
4、去掉空格;
5、將空格替換成\n,這裡可以自行替換成各種其他形式;
最終簡寫為一句話。
抓取新聞評論數
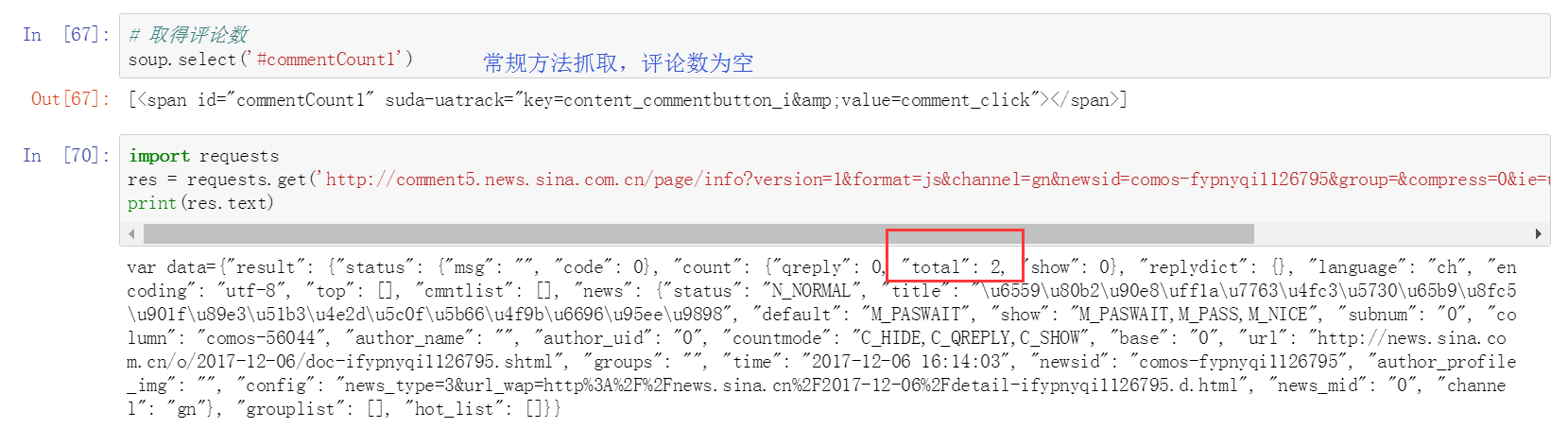
解釋:
評論是是通過JS代碼傳過來的;既然是JS,那麼通過AJAX傳過來的概率很高,於是點到XHR中看,但是發現Response中沒有出現總評論數2;然後就只能去JS裡面了,地毯式搜索,找哪個Response里出現了總評論數2,終於找到了。
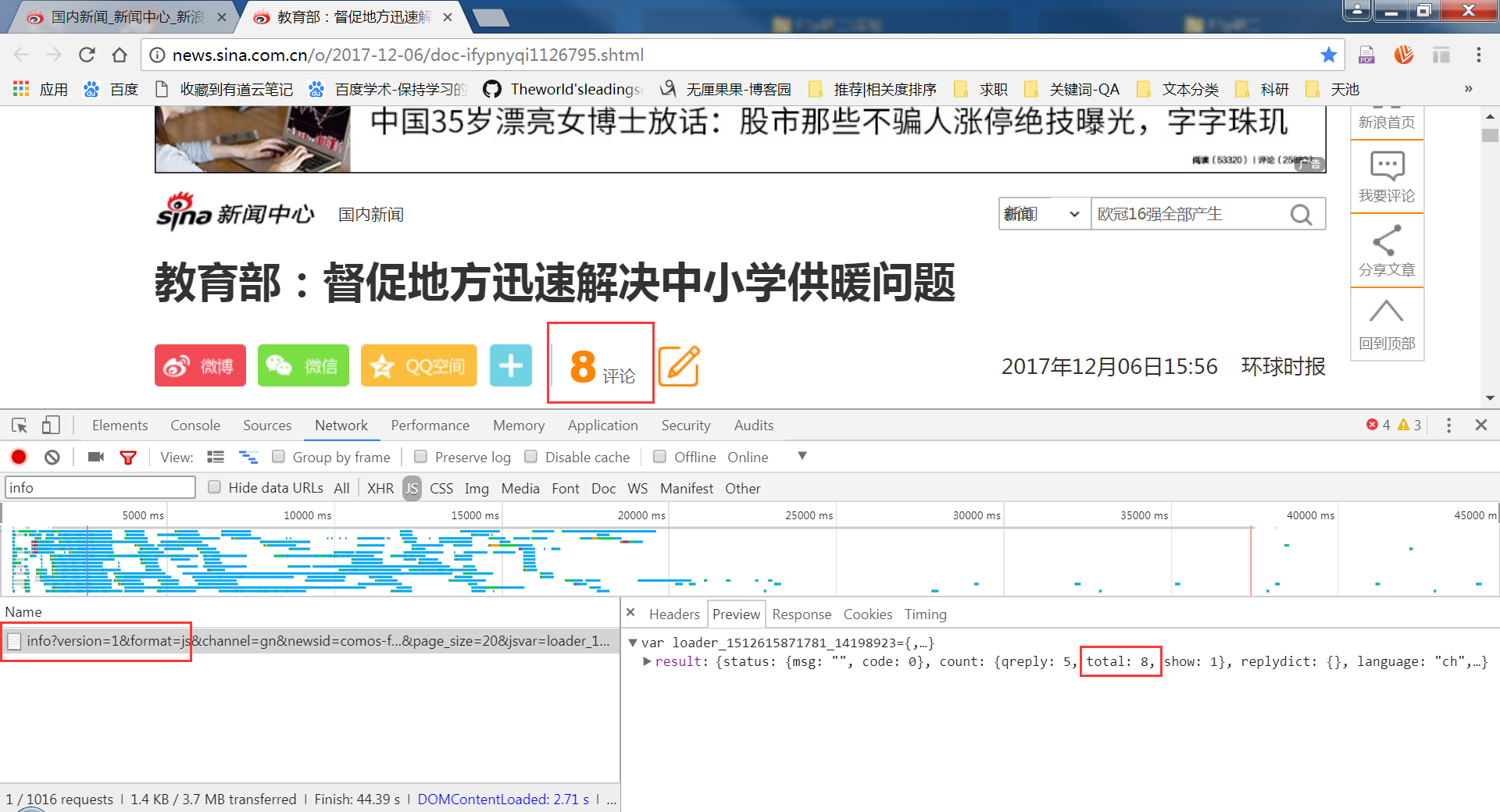
找到鏈接和請求方式
今天補的截圖,評論數實時增加,請不要覺得奇怪 ^_^
然後就可以擼碼了。
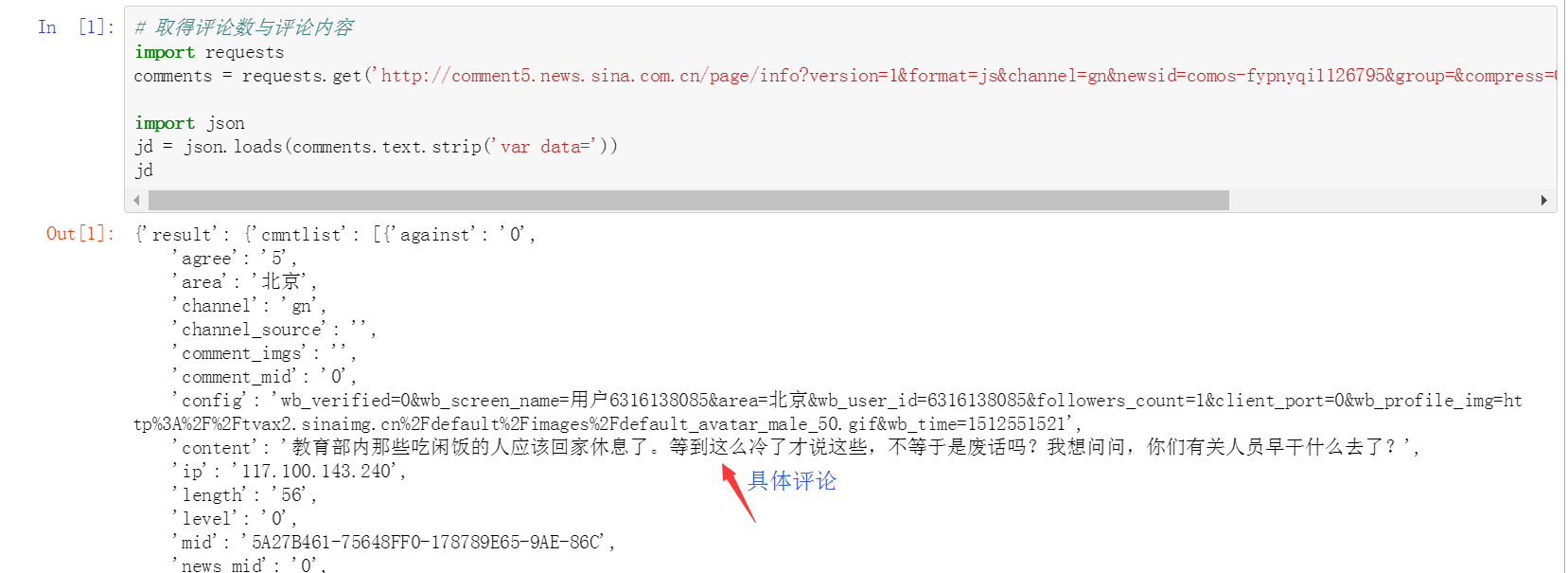
解釋:
var data={......}看著很像是個json串,去掉var data=,使其變為json串。
可以看到,jd串中就是評論的信息了。
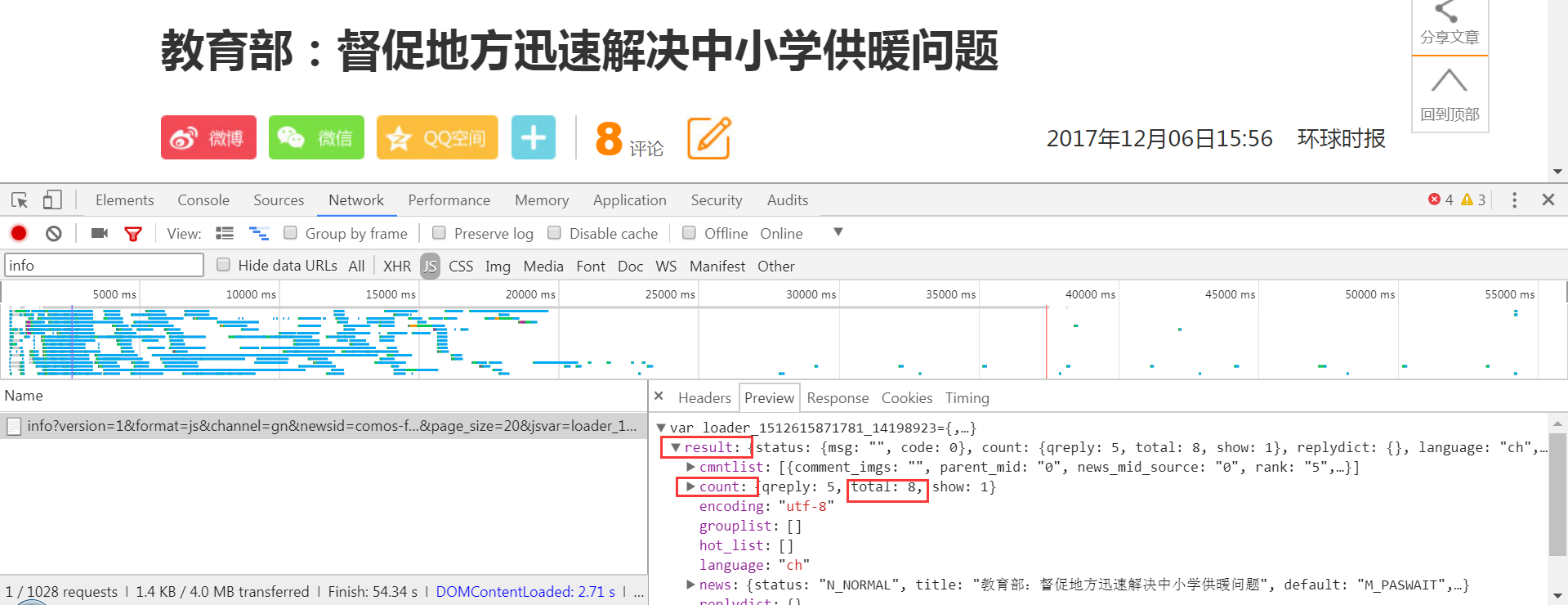
回到Chrome開發工具中,瀏覽評論數量。

獲取新聞標識符(新聞ID)
方式1:切割法
# 取得新聞編號 newsurl = 'http://news.sina.com.cn/o/2017-12-06/doc-ifypnyqi1126795.shtml' newsid = newsurl.split('/')[-1].rstrip('.shtml').lstrip('doc-i') newsid
方式2:正則表達式
import re m = re.search('doc-i(.*).shtml', newsurl) newsid = m.group(1) newsid
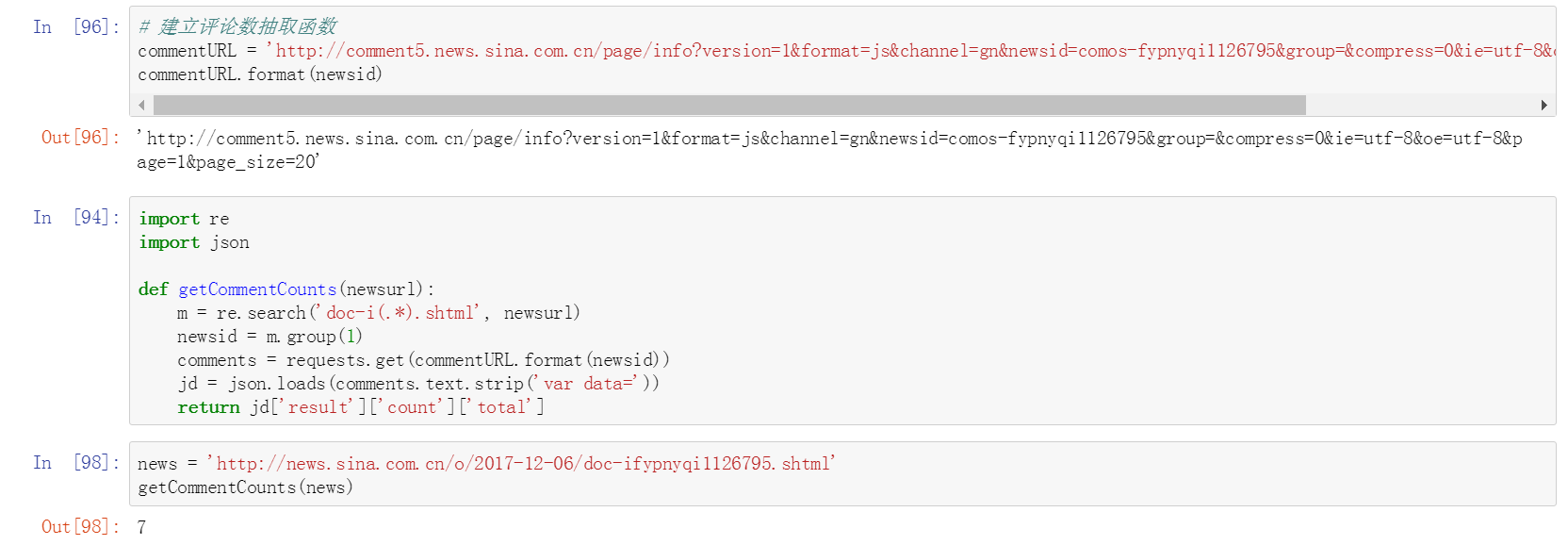
八、建立獲取評論數函數
做一個總整理,把剛剛取得評論數的方法整理成一個函數。之後有新聞網頁的鏈接丟進來,可以通過這個函式去取得它的總評論數。
九、建立新聞內文信息抽取函數


十、從列錶鏈接中取出每篇新聞內容
如果Doc下麵沒有我們想要找的東西,那麼就有理由懷疑,這個網頁產生資料的方式,是通過非同步的方式產生的。因此需要去XHR和JS下麵去找。
有時候會發現非同步方式的資料XHR下沒有,而是在JS下麵。這是因為這些資料會被JS的函式包裝,Chrome的開發者工具認為這是JS文件,因此就放到了JS下麵。
在JS中找到我們感興趣的資料,然後點擊Preview預覽,如果確定是我們要找的,就可以去Headers中查看Request URL和Request Method了。
一般JS中的第一個可能就是我們要找的,要特別留意第一個。
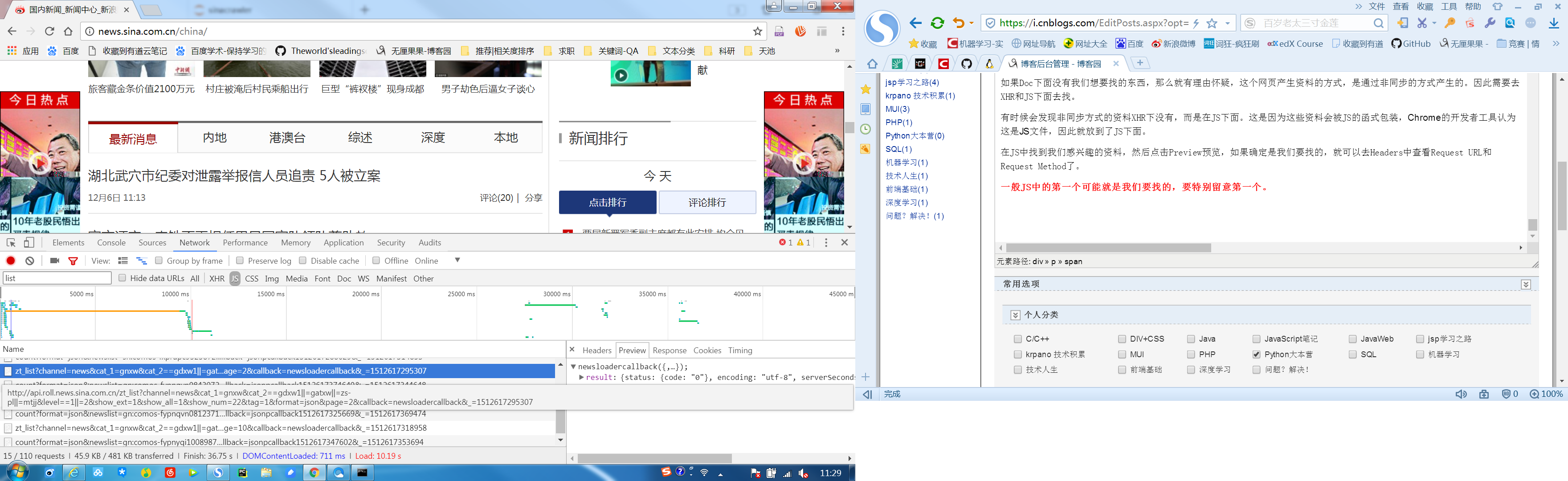
1、選擇Network標簽
2、點選JS
3、找到頁面鏈接page=2
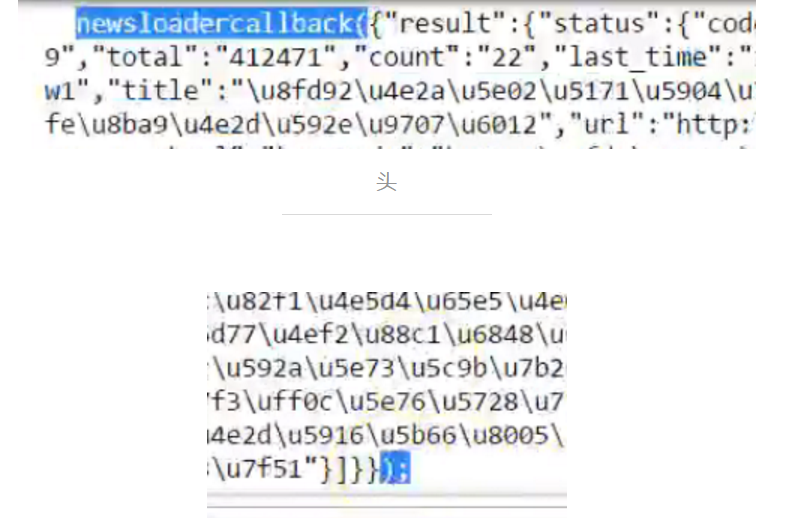
處理分頁鏈接

註意頭尾,需要去掉頭和尾,將其變成標準的json格式。
十一、建立剖析清單鏈接函數
將前面的步驟整理一下,封裝到一個函式中。
def parseListLinks(url): newsdetails = [] res = requests.get(url) jd = json.loads(res.text.lstrip('newsloadercallback()').rstrip(');')) for ent in jd['result']['data']: newsdetails.append(getNewsDetail(ent['url'])) return newsdetails
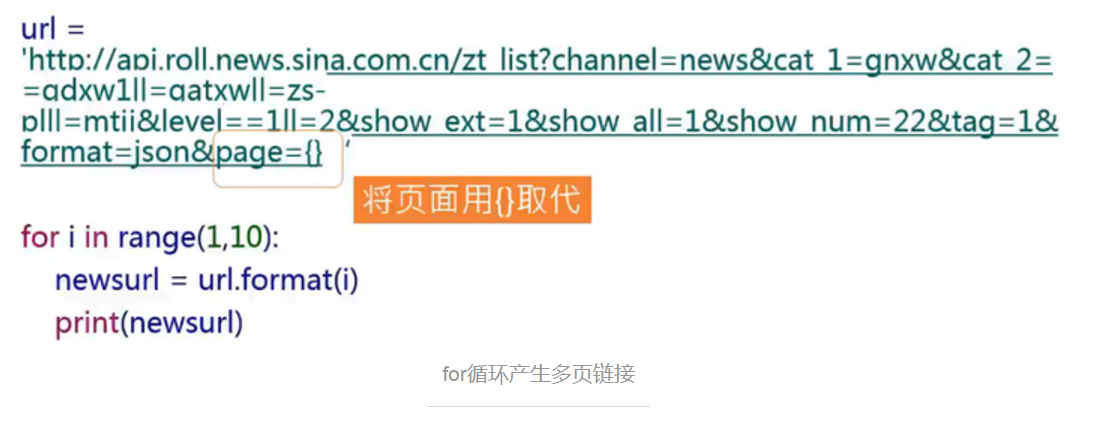
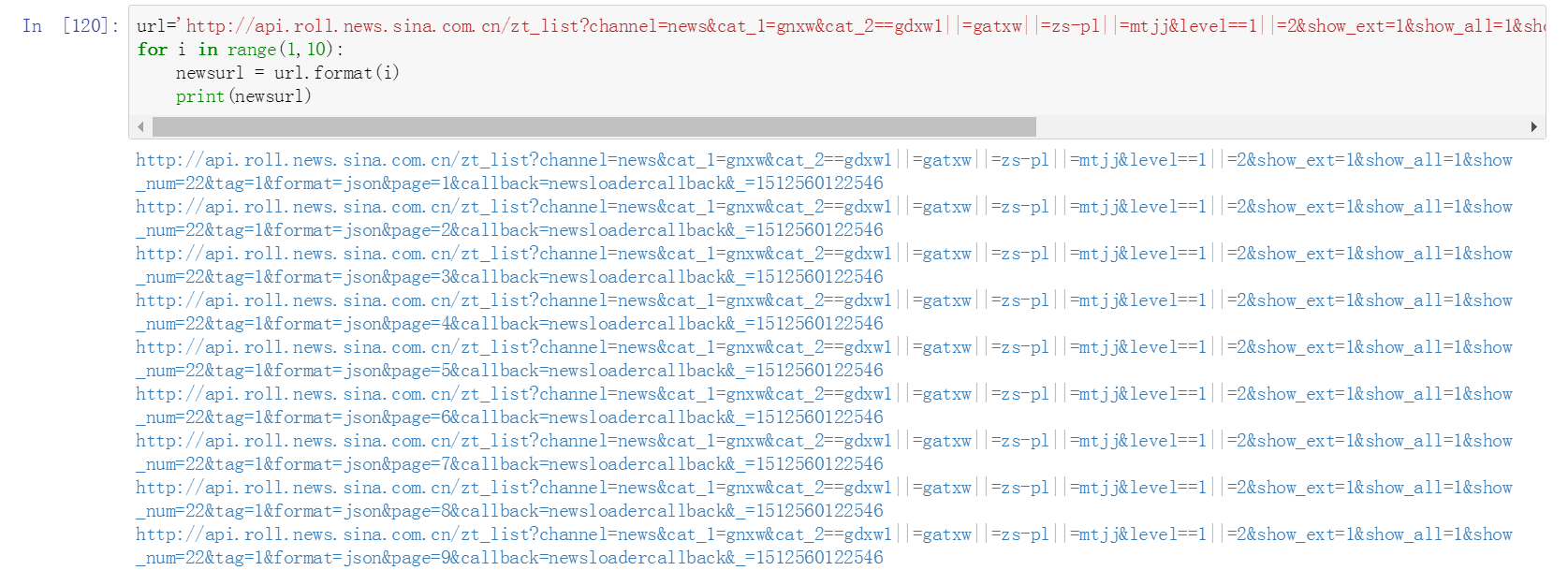
十二、使用for迴圈產生多頁鏈接
十三、批次抓取每頁新聞內文


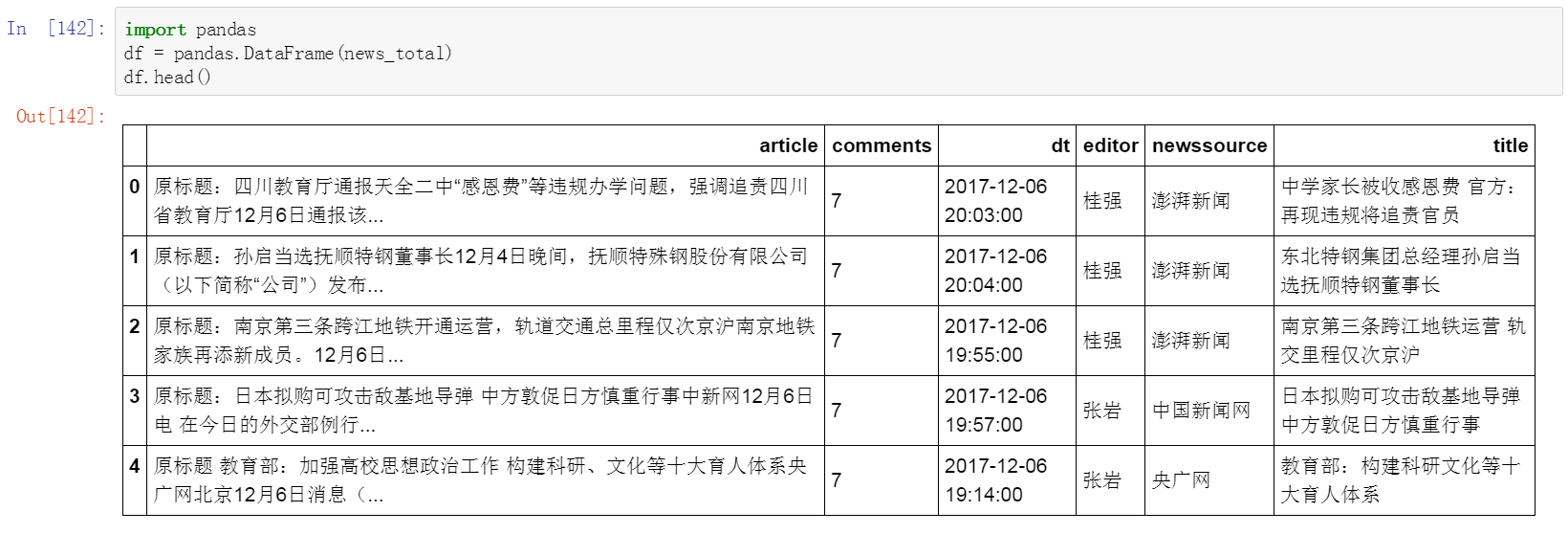
十四、 使用pandas整理數據
Python for Data Analysis
- 源於R
- Table-Like格式
- 提供高效能、簡易使用的資料格式(Data Frame)讓使用者可以快速操作及分析資料
十五、保存數據到資料庫
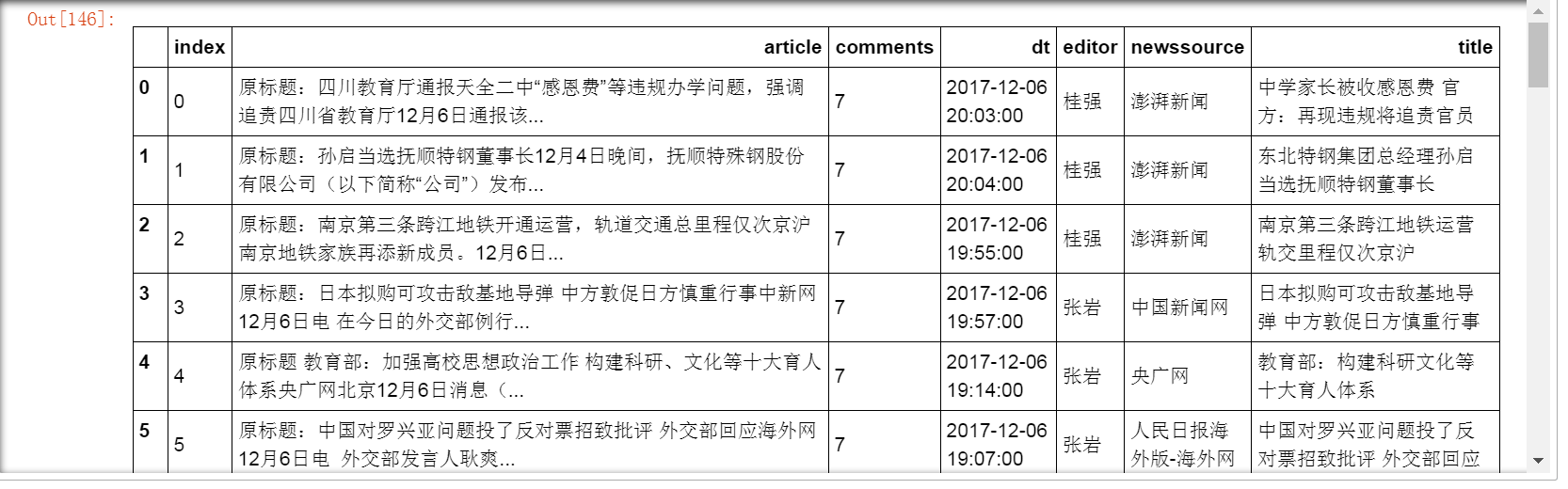
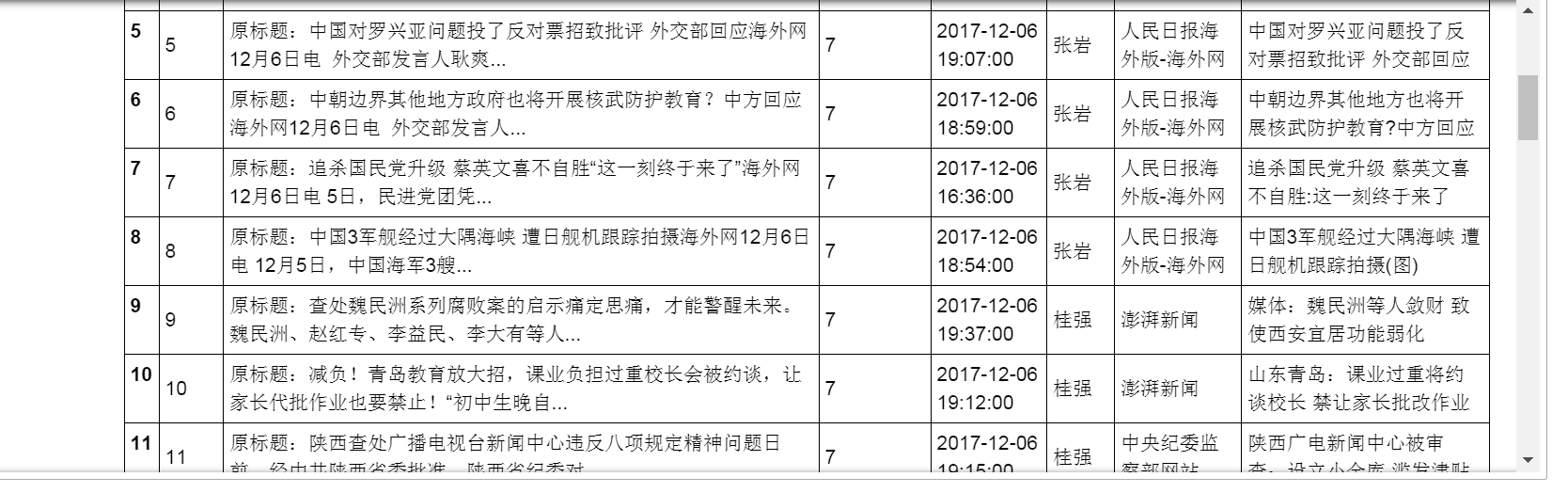
持續戰鬥到這裡,第一隻網路爬蟲終於完成。看著最終的結果,很有成就感啊!^_^
大家感興趣的可以試一試,歡迎討論交流~~~
如果覺得文章有用,請隨手點贊,感謝大家的支持!
特別贈送:GitHub代碼傳送門
感謝大家耐心地閱讀,如果能對大家有一點點幫助,歡迎點亮我的GitHub星標,謝謝~~~


