
性能監測著重於電腦系統資源監測,是對系統進行預防性維護的必要工作,可通過分析監視數據來瞭解系統存在哪些瓶頸,應當採取何種措施來調整或更新受影響的資源, Linux系 統提供了多種性能監測工具來幫助管理員完成系統監控工作; 1》性能監測概述: 系統性能監測與調整是Linux系統管理員日常維護工作的一 ...
性能監測著重於電腦系統資源監測,是對系統進行預防性維護的必要工作,可通過分析監視數據來瞭解系統存在哪些瓶頸,應當採取何種措施來調整或更新受影響的資源, Linux系 統提供了多種性能監測工具來幫助管理員完成系統監控工作;
1》性能監測概述:
系統性能監測與調整是Linux系統管理員日常維護工作的一項非常重要的內容,要衡量一個系統的性能狀態,可以從系統的響應時間以及系統吞吐量兩個角度來進行分析,響應 時間是指發出請求的時刻到用戶獲得返回結果所需要的時間,吞吐量是指在給定時間段內系統完成的交易數量,系統的吞吐量越大,系統的處理能力也就越強;管理員在進行性能監 測中的一個主要任務就是要找出系統的性能瓶頸所在,然後有針對性地進行調整,性能瓶頸是指那些對系統的性能起決定性影響的因素,不同的應用系統,性能瓶頸也有所不同,繁 忙的文件伺服器的性能瓶頸大多是磁碟子系統,大量用戶線上的應用程式伺服器的性能瓶頸可能是CPU子系統,而各種Internet網路伺服器的性能瓶頸通常是網路帶寬,需要進行監測 的系統資源主要是CPU,記憶體,磁碟和網路;
紅帽5圖形界面提供有一個類似於Windows任務管理器的性能監測-----系統監視器;從主菜單“系統”中選擇“管理”>“系統監視器”命令即可打開系統監視器,實時地查看進程, CPU,記憶體,網路和文件系統等信息;
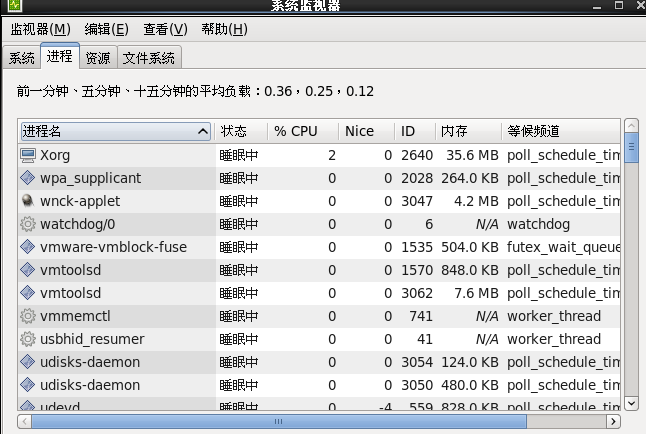
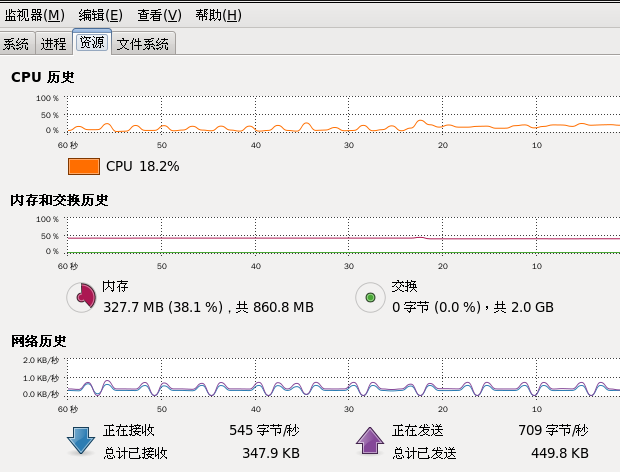
系統監視器雖然很方便,但功能有限,如果要對系統性能 做進一步分析,必須要藉助一些性能監視工具,如vmstat,mpstat,iostat,sar和top等,mpstat提供CPU相關數據;sar用 於收集,報告並存儲系統活動的信息;iostat提供CPU使用率及硬碟吞吐率的數據,vmstat可對虛擬記憶體,進程,CPU活動的總體情況進行統計;top是一個非常優秀的互動式綜合性 能監測工具;iostat和sar命令由sysstat軟體包提供,預設沒有安裝,安裝紅帽5的第三張光碟中的sysstat軟體包sysstat-7.0.0-3.el5.i386.rpm即可;
2》CPU性能監測:
CPU決定著系統的運算能力,系統內所有的程式指令都是經過CPU處理的,由於Linux自身是一個多用戶多任務的操作系統,因此CPU同時處理著來自不同優先等級的程式,如 果過多的程式同時執行,CPU就有可能形成系統的性能瓶頸;關於CPU的總體性能情況,可以使用sar命令進行查看,sar命令的基本用法如下:
sar [選項] [採樣間隔] [採樣次數]
採樣的時間間隔單位是秒,管理員可以根據需要按照一定的採樣間隔收集一定時間段的性能數據進行分析,以瞭解系統的性能狀況,為更準確地評估系統的性能,應該分析一 段時間內而不是單純某個具體時刻的性能數據,列如每隔5秒收集一次CPU性能數據,共收集三次,可以運行以下命令:
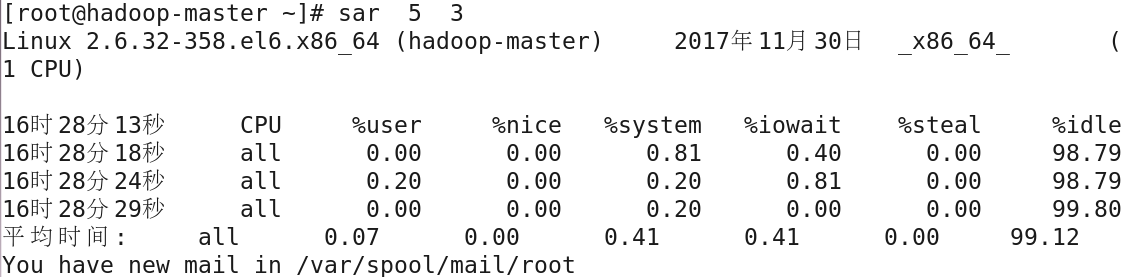
上述信息中列出了採樣時間,並對CPU的使用率按類目分類統計,最後一行是平均值,其中,%user表示用戶進程的CPU時間占用率;%nice表示用戶進程的nice操作(特 權進程)的CPU時間占用率;%system表示系統進程的CPU時間占用率;%iowait表示等待磁碟I/O所消耗的CPU時間占用率;%steal表示虛擬設備的CPU時間占用率;%idel表示 CPU空閑時間所占百分比;sar命令顯示CPU總的性能情況,對於有多處理器系統或者多核心的處理器,可以使用mpstat命令分別查看各個CPU的情況,語法格式如下:
mpstat [-P CPU編號|ALL] [採樣間隔] [採樣次數]
通過選項-P來指定要查看的CPU,CPU編號從0開始,例如查看第一個CPU:

該命令提供的信息比sar多3種,%irq列表表示硬中斷的CPU時間占用率,%soft列表示軟中斷的CPU時間占用率,intr/s列表示每秒鐘處理的中斷次數(次/秒);
3》記憶體性能監測:
電腦的記憶體是有一定容量的,當所需要的記憶體數量超過物理記憶體的容量時,系統會使用虛擬記憶體的分頁技術和交換技術,即將程式進程的一部分或全部移到硬碟上,以便為 新的進程騰出空間,當分頁和交換不太頻繁時,系統是完全可以接受的,當頻繁地進行分頁和交換時,系統性能就會受到影響,從而形成性能瓶頸;
1>使用free命令顯示系統的各種記憶體情況:
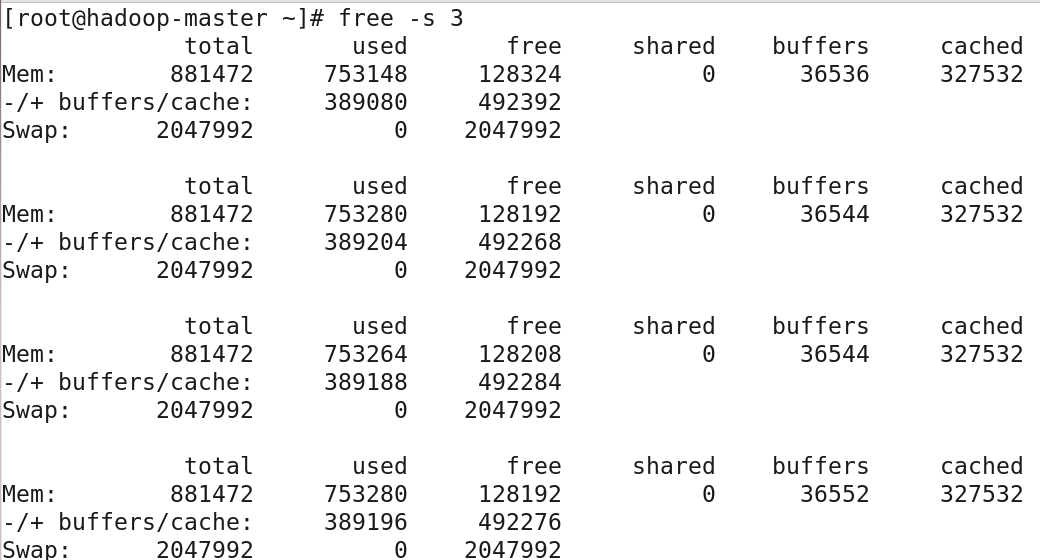
free命令可以用來查看記憶體和虛擬記憶體的使用情況,預設單位KB,這裡給出一個實例:

Mem行顯示的是物理記憶體,total列顯示物理記憶體總量,used列顯示使用量(分配給緩存使用的數量,其中可能部分緩存並未實際使用),free列表示可用量(未被分 配的記憶體),shared列顯示多個進程共用的記憶體,buffers列顯示系統分配但未被使用的緩衝(用作緩衝區的記憶體數量),cache列顯示系統分配但未被使用的緩存(用作高 速緩存的記憶體數量);
提示:buffers與cache都占用記憶體,應註意他們的區別,buffers是塊設備的讀寫緩存區,是存放待寫到磁碟上的數據的記憶體,是物理級的,它根據磁碟的讀寫設 計,將分散的寫操作集中進行,以減少磁碟碎片和反覆尋道,提高系統性能;cache一般意思是緩存,是作為頁面高速緩存的記憶體,屬於文件系統,存放從磁 盤讀取後待處理的數據,它將讀取過的數據保存起來,重新讀取時若命中(找到需要的數據)就不去讀取硬碟,若沒有命中就讀硬碟,當然,其中的數據根據 讀取頻率進行組織,會將最頻繁讀取的內容放在最容易找到的位置;
接下來的一行顯示應用程式的記憶體使用,兩列分別顯示真正用掉的記憶體(分配給緩存使用的數量減去未被使用的buffers與cache,也就是實際使用的buffers與cache總 量)和系統當前實際可用的記憶體(未被使用的buffers與cache和未被分配的記憶體之和),“-/+”符號表示buffers/cache的大小是可以改變的,不是實際占記憶體的;
最後一行Swap顯示交換空間記憶體的使用狀態,3列分別顯示交換的容量(total),使用量(used)和可用的空閑交換區(free);要通過free進行一段時間的記憶體使用 監測,可以使用-s選項指定一個時間間隔(單位s)進行持續的監測:
2>使用vmstat命令全面監測記憶體:
要全面監測記憶體性能,可以使用vmstat命令,vmstat命令可以用來顯示物理記憶體和虛擬記憶體的有關狀態,同時也可以顯示CPU的有關信息:

vmstat命令監測的數據比較多,分成幾大類來顯示:
procs(進程)部分的r,b列分別顯示準備就緒等待運行的進程數量和處於不可中斷的休眠狀態的進程數量,所謂不可中斷的休眠狀態是指進程收到任何信號都不 會被喚醒成為可運行狀態,將一直等待硬體狀態的改變;
memore(記憶體)部分的swpd,free,buff和cache列分別顯示虛擬記憶體的使用量,空閑物理記憶體,記憶體緩衝區和高速緩存的大小;
swap(交換)部分的si和so列分別顯示每秒交換到磁碟和從磁碟中讀取的位元組數;
io(輸入輸出)部分的bi和bo列分別顯示每秒寫入塊設備和從塊設備中讀取的快數;
system(系統)部分的in和cs列分別顯示每秒中斷(包括時鐘中斷)和上下文切換(context switches)的次數,當一個進程用完時間片或者被更高優先順序的 進程搶占時間塊後,它會被轉到CPU的等待運行隊列中,同時讓其他進程在CPU上運行,這個進程切換的過程被稱作上下文切換,過多的上 下文切換會造成系統很大的開銷;
cpu部分是顯示占用CPU時間的百分比,u表示用戶進程時間,sy表示系統進程時間,id表示空閑時間,wa表示等待時間,st表示虛擬機占用時間;
vmstat命令也可以指定數據採樣間隔和採樣次數,即使用以下格式:
vmstat [採樣間隔] [採樣次數]

4》磁碟I/O性能監測:
由於磁碟設備的運行速度比CPU的指令處理速度要慢很多,因此涉及磁碟操作的部分是整個過程執行過程中最慢的操作,儘管磁碟自身硬體技術如轉速,緩存等不斷提 高,但是磁碟依然很容易形成系統性能的瓶頸;iostat工具可以對系統的磁碟操作活動進行監測,並報告磁碟活動統計情況,包括數據吞吐量和傳輸請求等數據,基本用法如下:
iostat [選項] [採樣間隔] [採樣次數]
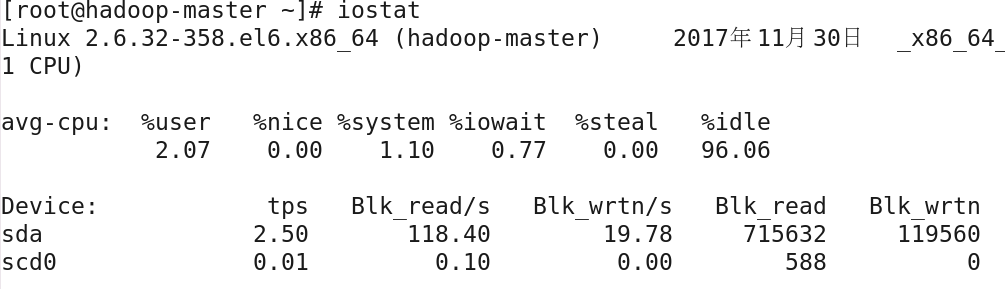
預設情況下,iostat命令按磁碟設備(Device列)來顯示彙總的使用情況,並顯示CPU使用情況(avg-cpu部分),如果加上選項-d將只統計磁碟使用情況,關於磁碟的 數據使用情況,具體的統計數據包括5項:tps表示每秒發送到設備上的I/O請求次數;BLK_read/s和BLK_wrtn/s分別表示設備每秒讀取和寫入數據的快數;BLK_read和 BLK_wrtn分別表示設備讀取和寫入數據的總快數;如果要查看磁碟中分區的使用情況,可以使用-p選項指定分區;選項-t表示在每次的統計結果中顯示時間,如果要改變磁碟使 用統計單位塊,使用選項-k以KB代替塊,-m以MB代替塊;
另外,還可以使用sar -b命令統計I/O和傳輸速率,預設以10分鐘作為一個間隔顯示最近一段時間以來的數據,統計內容包括5項:tps表示每秒從物理磁碟I/O請求的次 數(多個邏輯請求會被合併為一個I/O磁碟請求,一次傳輸的大小不確定),rtps和wtps分別表示每秒鐘讀請求和寫請求的次數,bread/s和bwrtn/s分別表示每秒鐘從磁碟讀取和 寫入到磁碟的數據的快數;
5》通過top實現綜合監控:
top命令是一個非常優秀的互動式性能監測工具,可以在一個統一的界面中按照用戶指定的時間間隔刷新顯示包括記憶體,CPU,進程,用戶數據,運行時間等的性能信息, 其命令格式如下:
top -hv | -bcHisS -d 刷新間隔 -n 刷新次數 -p pid [,pid....]
選項-p pid表示只顯示指定的pid進程信息,top命令運行結果如下:

第一行(top):顯示系統運行時間,用戶數以及負載的平均值信息;
第二行(Tasks):顯示進程的概要信息,分別是當前進程總數,正在運行的進程數,正在休眠的進程數,已停止的進程數和僵死的進程數;
第三行(CPU):顯示CPU占用百分比,分別是用戶進程,系統進程,改變過優先順序的用戶進程,空閑狀態,等待I/O,硬體中斷,軟體中斷和虛擬設備所占的CPU百分 比;
第四行(Mem):顯示物理記憶體信息,分別是物理記憶體總量,已使用的物理記憶體數量,未被使用的物理記憶體數量,用作緩衝區的記憶體數量;
第五行(Swap):顯示虛擬記憶體信息,分別是虛擬記憶體總量,已使用的虛擬記憶體數量,空閑的虛擬記憶體數量,用作緩存的虛擬記憶體數量;
最後一部分是每個進程的性能統計信息,每個進程有12項信息:PID(進程ID),USER(執行進程的用戶),PR(優先順序),NI(nice值),VIRT(進程使用 的虛擬記憶體大小),RES(進程使用的物理記憶體大小),SHR(共用記憶體),S(進程狀態),%CPU(占用CPU百分比),%MEM(使用物理記憶體的百分比), TIME+(使用CPU的時間),COMMAND(進程的名稱);
6》優化系統性能:
優化系統性能的基本步驟可以歸納 如下:
1)使用監測工具監視系統的活動;
2)分析得到的性能數據,找出不能滿足性能要求的環節;
3)分析造成性能降低的原因,採取相應的優化措施;
提高系統性能常用的方法是從硬體配置上提高性能,例如用SCSI介面硬碟代替IDE硬碟,使用多個硬碟建立RAID,使用儘可能大的物理記憶體,使用多處理系統等;
如果只是進行Linux預設的安裝,而不對其中涉及性能的選項進行具體詳細的配置,系統的性能往往不會達到最優化的效果,通過對內核的調整可以使系統整體性能達 到最優,建議在調整內核的時候,先將內核升級到一個比較新的內核版本,一般來說,新的內核版本對於性能方面有更多的選項給予支持,為使性能達到最優,應該根據用戶 自己的需要,主動捨棄一些占用資源太多的功能,配置一個適合自己的自定義內核;
系統目前CPU使用率高是由於IO等待所造成的,並非由於CPU資源不足,用戶應檢查系統中正在進行IO操作的進程,併進行調整和優化;
系統的空閑記憶體少不一定說明系統性能有問題,這需要結合si和so(記憶體和磁碟的頁面交換)兩個指標進行分析,當物理記憶體能足以存放所有進程的數據,物理記憶體 和磁碟(虛擬記憶體)是不應該存在頻繁的頁面交換操作的,只有當物理記憶體不能滿足需要時系統才會把記憶體中的數據交換到磁碟中,由於磁碟的性能是比記憶體慢很多的,所以 如果存在大量的頁面交換,那麼系統的性能必然會受到很大影響;


