
c 參照編譯器底層實現一個 json引擎. 這是第一篇 主要講解解析部分. 可能 寫的不流利,主要看代碼吧. 之前寫了一個,後面看了cJSON的實現,簡單 合併重構了一下. 歡迎嘗試吐槽
引言
以前可能是去年的去年,寫了一個 c json 解析引擎用於一個統計實驗數據項目開發中. 基本上能用. 去年在網上
看見了好多開源的c json引擎 .對其中一個比較標準的 cJSON 引擎 深入學習了一下.
以前那個和cJSON對比了一下, 覺得 以前寫的那個 優點是 空間小, 速度快, 因為採用的是 用時解析.而cJSON採用
的是遞歸下降分析, 結構也比較大.最後 決定再重構一個用的cjson. 目前設計思路以通用為主.
其實 結構 就決定 所有. 等同人的性格.
參照資料
1.json 標準 http://www.json.org/
2.cJSON 源碼 https://sourceforge.net/projects/cjson/
吐槽一下
網上很多朋友 推薦看cJSON源碼, 因為就700多行,可以看看學學. 真的嗎 看下麵 摘錄的代碼
1 void cJSON_ReplaceItemInObject(cJSON *object, const char *string, cJSON *newitem) { int i = 0;cJSON *c = object->child;while (c && cJSON_strcasecmp(c->string, string))i++, c = c->next;if (c) { newitem->string = cJSON_strdup(string);cJSON_ReplaceItemInArray(object, i, newitem); } }
上面就是cJSON中常出現的代碼格式,確實 700多行, 這個700多行全部分開可能要 1400行. 對於這些說700行的朋友只能是呵呵.
但有一點,看了很多nb的json引擎,也就 cJSON最容易理解了.最容易學習了. 性能還行. 這個是不得不說的優點.
後面 再扯一點, 這篇博文也可以理解為cJSON的深入剖析. 最後我採用遞歸下降分析 語法,構造 cjson_t 結構. 設計比cJSON更好用,更高效.
前言
每次寫博文,發現寫的好長,不關註的人很難理解, 這次採用一種新思路. 先將通用的簡單的C開發技巧 . 後面再講主題.
1. 積累的C開發 技巧 看完這個 你就已經賺了, 後面就可以不看了
首先我們分享一個 string convert number 的程式, 首先看下麵代碼.
// 分析數值的子函數,寫的可以 double parse_number(const char* str) { double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示開始正負, 負為-1, nd 表示小數後面位數 int e = 0, es = 1; //e表示後面指數, es表示 指數的正負,負為-1 char c; if ((c = *str) == '-' || c == '+') { ns = c == '-' ? -1.0 : 1.0; //正負號檢測, 1表示負數 ++str; } //處理整數部分 for (c = *str; c >= '0' && c <= '9'; c = *++str) n = n * 10 + c - '0'; if (c == '.') for (; (c = *++str) >= '0' && c <= '9'; --nd) n = n * 10 + c - '0'; // 處理科學計數法 if (c == 'e' || c == 'E') { if ((c = *++str) == '+') //處理指數部分 ++str; else if (c == '-') es = -1, ++str; for (; (c = *str) >= '0' && c <= '9'; ++str) e = e * 10 + c - '0'; } //返回最終結果 number = +/- number.fraction * 10^+/- exponent n = ns * n * pow(10.0, nd + es * e); return n; }
推薦有心的人多寫幾遍, 支持 +19.09 -19.0 19.567e123 -19.09E-9 這些轉換. 這是項目工程代碼,久經考驗.
面試也常考. 沒啥意思 , 那還有一個 不錯的技巧 如下
/* * 10.1 這裡是一個 在 DEBUG 模式下的測試巨集 * * 用法 : * DEBUG_CODE({ * puts("debug start..."); * }); */ #ifndef DEBUG_CODE # ifdef _DEBUG # define DEBUG_CODE(code) code # else # define DEBUG_CODE(code) # endif // ! _DEBUG #endif // !DEBUG_CODE
這是個 測試code 巨集, 有時候我們想 DEBUG下 測試代碼在 Release 模式 刪除 . 就用上面巨集 .在gcc 下 需要 加上 -I_DEBUG
使用舉例如下
/* * 根據索引得到這個數組中對象 * array : 數組對象 * idx : 查找的索引 必須 [0,cjson_getlen(array)) 範圍內 * : 返回查找到的當前對象 */ cjson_t cjson_getarray(cjson_t array, int idx) { cjson_t c; DEBUG_CODE({ if (!array || idx < 0) { SL_FATAL("array:%p, idx=%d params is error!", array, idx); return NULL; } }); for (c = array->child; c&&idx > 0; c = c->next) --idx; return c; }
是不是很酷. 到這裡 可以認為 值了學到了. 後面不好懂,可看可不看了!
正文
1. json 的語法解析 分析
恭喜到這裡了,上面第一個分享的函數還有一種好思路 是 整數部分 和 小數部分分開算,後面再加起來. 就到這裡吧.
json 的語法解析 同
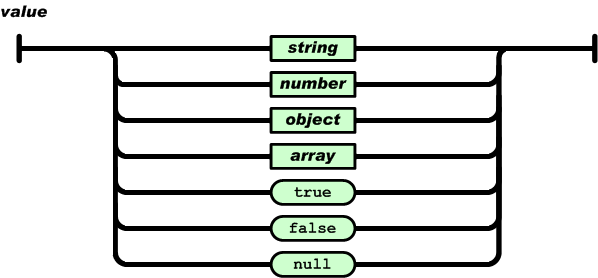
從 value 解析開始 遇到的 string number true false null 直接解析
到 array , object 開始解析的時候 解析完畢直接 到value 解析, 這樣遞歸下降解析完成 函數調用的流程圖如下:
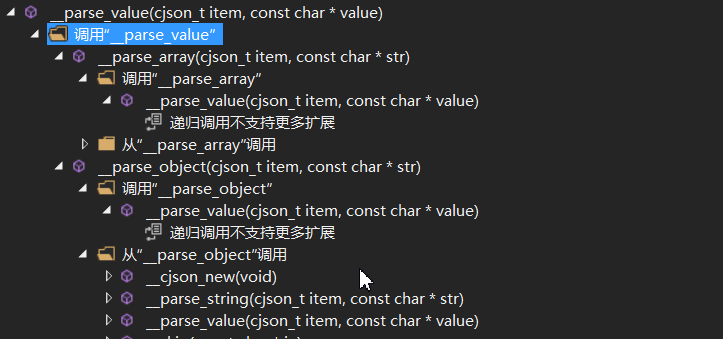
例如value 解析如下
// 將value 轉換塞入 item json值中一部分 static const char* __parse_value(cjson_t item, const char* value) { char c; if ((value) && (c = *value)) { switch (c) { // n = null, f = false, t = true case 'n' : return item->type = _CJSON_NULL, value + 4; case 'f' : return item->type = _CJSON_FALSE, value + 5; case 't' : return item->type = _CJSON_TRUE, item->vd = 1.0, value + 4; case '\"': return __parse_string(item, value); case '0' : case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': case '+' : case '-': return __parse_number(item, value); case '[' : return __parse_array(item, value); case '{' : return __parse_object(item, value); } } // 迴圈到這裡是意外 數據 SL_WARNING("params value = %s!", value); return NULL; }
這裡是 value函數入口, 再以 array處理為例 流程 如下
// 分析數組的子函數, 採用遞歸下降分析 static const char* __parse_array(cjson_t item, const char* str) { cjson_t child; if (*str != '[') { SL_WARNING("array str error start: %s.", str); return NULL; } item->type = _CJSON_ARRAY; str = __skip(str + 1); if (*str == ']') // 低估提前結束 return str + 1; item->child = child = __cjson_new(); str = __skip(__parse_value(child, str)); if (!str) {//解析失敗 直接返回 SL_WARNING("array str error e n d one: %s.", str); return NULL; } while (*str == ',') { cjson_t nitem = __cjson_new(); child->next = nitem; nitem->prev = child; child = nitem; str = __skip(__parse_value(child, __skip(str + 1))); if (!str) {// 寫代碼是一件很爽的事 SL_WARNING("array str error e n d two: %s.", str); return NULL; } } if (*str != ']') { SL_WARNING("array str error e n d: %s.", str); return NULL; } return str + 1; // 跳過']' }
主要看 while中內容,挨個分析 數組中內容,最後又導向於 value中.
大體流程就如上了,通過間接遞歸處理了 json語法的語句.
2.cjson 的 結構分析
首先看 結構文件
// json 中幾種數據類型定義 #define _CJSON_FALSE (0) #define _CJSON_TRUE (1) #define _CJSON_NULL (2) #define _CJSON_NUMBER (3) #define _CJSON_STRING (4) #define _CJSON_ARRAY (5) #define _CJSON_OBJECT (6) #define _CJSON_ISREF (256) //set 時候用如果是引用就不釋放了 #define _CJSON_ISCONST (512) //set時候用, 如果是const char* 就不釋放了 struct cjson { struct cjson *next, *prev; struct cjson *child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那麼 child 就不為空 int type; char *key; // json內容那塊的 key名稱 char *vs; // type == _CJSON_STRING, 是一個字元串 double vd; // type == _CJSON_NUMBER, 是一個num值, ((int)c->vd) 轉成int 或 bool }; //定義cjson_t json類型 typedef struct cjson* cjson_t;
來分析一下 struct cjson 中結構欄位意思, 其中 next,prev 理解為雙向鏈表, 為了查找同一層的 對象.例如
[1,2,3,4,[6,5]] 其中 1,2,3,4, [6,5] 就是同一層, 6,5 是同一層
4->next 後面 的 child 就是 [6,5]每次解析到新的 array 或 object 都用child 導向它.
type 表示類型 預設有其中 [0,6], 如上 _CJSON_*
key 用於關聯對象.
是不是很好理解
這裡提供介面如下
/* * 這個巨集,協助我們得到 int 值 或 bool 值 * * item : 待處理的目標cjson_t結點 */ #define cjson_getint(item) \ ((int)((item)->vd)) /* * 刪除json串內容 * c : 待釋放json_t串內容 */ extern void cjson_delete(cjson_t* pc); /* * 對json字元串解析返回解析後的結果 * jstr : 待解析的字元串 */ extern cjson_t cjson_parse(const char* jstr); /* * 根據 item當前結點的 next 一直尋找到 NULL, 返回個數 *推薦是數組使用 * array : 待處理的cjson_t數組對象 * : 返回這個數組中長度 */ extern int cjson_getlen(cjson_t array); /* * 根據索引得到這個數組中對象 * array : 數組對象 * idx : 查找的索引 必須 [0,cjson_getlen(array)) 範圍內 * : 返回查找到的當前對象 */ extern cjson_t cjson_getarray(cjson_t array, int idx); /* * 根據key得到這個對象 相應位置的值 * object : 待處理對象中值 * key : 尋找的key * : 返回 查找 cjson_t 對象 */ extern cjson_t cjson_getobject(cjson_t object, const char* key);
看一遍是不是就理解了,看代碼還是比較好懂的. 自己寫就難一點了. 主要難在
設計 => 開發 => 測試 => 優化 => 設計 => 開發 => 測試 .................................. 流程很多,出一個好東西最難的是時間和執著.
3.cjson 部分源碼分析
先看最重要的 記憶體釋放代碼
// 刪除cjson static void __cjson_delete(cjson_t c) { cjson_t next; while (c) { next = c->next; //遞歸刪除兒子 if (!(c->type & _CJSON_ISREF)) { if (c->child) //如果不是尾遞歸,那就先遞歸 __cjson_delete(c->child); if (c->vs) free(c->vs); } else if (!(c->type & _CJSON_ISCONST) && c->key) free(c->key); free(c); c = next; } } /* * 刪除json串內容,最近老是受清華的老學生打擊, 會起來的...... * c : 待釋放json_t串內容 */ void cjson_delete(cjson_t* pc) { if (!pc || !*pc) return; __cjson_delete(*pc); *pc = NULL; }
上面做法是 防止野指針, 用時間換安全. 時間空間安全 三要素,基本就是編程三大元素. 上面 _CJSOn_ISREF 是為了 set 後面設計留的, 添加了不需要釋放的東西
我們就不處理.
在看一個獲取關聯對象的值
/* * 根據key得到這個對象 相應位置的值 * object : 待處理對象中值 * key : 尋找的key * : 返回 查找 cjson_t 對象 */ cjson_t cjson_getobject(cjson_t object, const char* key) { cjson_t c; DEBUG_CODE({ if (!object || !key || !*key) { SL_FATAL("object:%p, key=%s params is error!", object, key); return NULL; } }); for (c = object->child; c && str_icmp(key, c->key); c = c->next) ; return c; }
是不是很容易 一下都明白了. 其中 str_icmp 上一篇博文中好像講過源碼 如下
/*
* 這是個不區分大小寫的比較函數
* ls : 左邊比較字元串
* rs : 右邊比較字元串
* : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
*/
int
str_icmp(const char* ls, const char* rs)
{
int l, r;
if(!ls || !rs)
return (int)ls - (int)rs;
do {
if((l=*ls++)>='a' && l<='z')
l -= 'a' - 'A';
if((r=*rs++)>='a' && r<='z')
r -= 'a' - 'A';
} while(l && l==r);
return l-r;
}
到這裡 目前 瞭解的設計基本就完工了.
4.cjson 源碼源碼展示
這裡就是普通展示所有的源碼 首先是 cjson.h
#ifndef _H_CJSON #define _H_CJSON // json 中幾種數據類型定義 #define _CJSON_FALSE (0) #define _CJSON_TRUE (1) #define _CJSON_NULL (2) #define _CJSON_NUMBER (3) #define _CJSON_STRING (4) #define _CJSON_ARRAY (5) #define _CJSON_OBJECT (6) #define _CJSON_ISREF (256) //set 時候用如果是引用就不釋放了 #define _CJSON_ISCONST (512) //set時候用, 如果是const char* 就不釋放了 struct cjson { struct cjson *next, *prev; struct cjson *child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那麼 child 就不為空 int type; char *key; // json內容那塊的 key名稱 char *vs; // type == _CJSON_STRING, 是一個字元串 double vd; // type == _CJSON_NUMBER, 是一個num值, ((int)c->vd) 轉成int 或 bool }; //定義cjson_t json類型 typedef struct cjson* cjson_t; /* * 這個巨集,協助我們得到 int 值 或 bool 值 * * item : 待處理的目標cjson_t結點 */ #define cjson_getint(item) \ ((int)((item)->vd)) /* * 刪除json串內容 * c : 待釋放json_t串內容 */ extern void cjson_delete(cjson_t* pc); /* * 對json字元串解析返回解析後的結果 * jstr : 待解析的字元串 */ extern cjson_t cjson_parse(const char* jstr); /* * 根據 item當前結點的 next 一直尋找到 NULL, 返回個數 *推薦是數組使用 * array : 待處理的cjson_t數組對象 * : 返回這個數組中長度 */ extern int cjson_getlen(cjson_t array); /* * 根據索引得到這個數組中對象 * array : 數組對象 * idx : 查找的索引 必須 [0,cjson_getlen(array)) 範圍內 * : 返回查找到的當前對象 */ extern cjson_t cjson_getarray(cjson_t array, int idx); /* * 根據key得到這個對象 相應位置的值 * object : 待處理對象中值 * key : 尋找的key * : 返回 查找 cjson_t 對象 */ extern cjson_t cjson_getobject(cjson_t object, const char* key); #endif // !_H_CJSON
後買你是 cjson.c 的實現
#include <cjson.h> #include <schead.h> #include <sclog.h> #include <tstring.h> #include <math.h> // 刪除cjson static void __cjson_delete(cjson_t c) { cjson_t next; while (c) { next = c->next; //遞歸刪除兒子 if (!(c->type & _CJSON_ISREF)) { if (c->child) //如果不是尾遞歸,那就先遞歸 __cjson_delete(c->child); if (c->vs) free(c->vs); } else if (!(c->type & _CJSON_ISCONST) && c->key) free(c->key); free(c); c = next; } } /* * 刪除json串內容,最近老是受清華的老學生打擊, 會起來的...... * c : 待釋放json_t串內容 */ void cjson_delete(cjson_t* pc) { if (!pc || !*pc) return; __cjson_delete(*pc); *pc = NULL; } //構造一個空 cjson 對象 static inline cjson_t __cjson_new(void) { cjson_t c = calloc(1, sizeof(struct cjson)); if (!c) { SL_FATAL("calloc sizeof struct cjson error!"); exit(_RT_EM); } return c; } // 簡化的代碼段,用巨集來簡化代碼書寫 , 16進位處理 #define __parse_hex4_code(c, h) \ if (c >= '0' && c <= '9') \ h += c - '0'; \ else if (c >= 'A' && c <= 'F') \ h += 10 + c - 'A'; \ else if (c >= 'a' && c <= 'z') \ h += 10 + c - 'F'; \ else \ return 0 // 等到unicode char代碼 static unsigned __parse_hex4(const char* str) { unsigned h = 0; char c = *str; //第一輪 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第二輪 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第三輪 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第四輪 __parse_hex4_code(c, h); return h; } // 分析字元串的子函數, static const char* __parse_string(cjson_t item, const char* str) { static unsigned char __marks[] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC }; const char *ptr; char *nptr, *out; int len; char c; unsigned uc, nuc; if (*str != '\"') { // 檢查是否是字元串內容 SL_WARNING("need \\\" str => %s error!", str); return NULL; } for (ptr = str + 1, len = 0; (c = *ptr++) != '\"' && c; ++len) if (c == '\\') //跳過轉義字元 ++ptr; if (!(out = malloc(len + 1))) { SL_FATAL("malloc %d size error!", len + 1); return NULL; } // 這裡複製拷貝內容 for (ptr = str + 1, nptr = out; (c = *ptr) != '\"' && c; ++ptr) { if (c != '\\') { *nptr++ = c; continue; } // 處理轉義字元 switch ((c = *++ptr)) { case 'b': *nptr++ = '\b'; break; case 'f': *nptr++ = '\f'; break; case 'n': *nptr++ = '\n'; break; case 'r': *nptr++ = '\r'; break; case 't': *nptr++ = '\t'; break; case 'u': // 將utf16 => utf8, 專門的utf處理代碼 uc = __parse_hex4(ptr + 1); ptr += 4;//跳過後面四個字元, unicode if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == 0) break; /* check for invalid. */ if (uc >= 0xD800 && uc <= 0xDBFF) /* UTF16 surrogate pairs. */ { if (ptr[1] != '\\' || ptr[2] != 'u') break; /* missing second-half of surrogate. */ nuc = __parse_hex4(ptr + 3); ptr += 6; if (nuc < 0xDC00 || nuc>0xDFFF) break; /* invalid second-half of surrogate. */ uc = 0x10000 + (((uc & 0x3FF) << 10) | (nuc & 0x3FF)); } len = 4; if (uc < 0x80) len = 1; else if (uc < 0x800) len = 2; else if (uc < 0x10000) len = 3; nptr += len; switch (len) { case 4: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 3: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 2: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 1: *--nptr = (uc | __marks[len]); } nptr += len; break; default: *nptr++ = c; } } *nptr = '\0'; if (c == '\"') ++ptr; item->vs = out; item->type = _CJSON_STRING; return ptr; } // 分析數值的子函數,寫的可以 static const char* __parse_number(cjson_t item, const char* str) { double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示開始正負, 負為-1, nd 表示小數後面位數 int e = 0, es = 1; //e表示後面指數, es表示 指數的正負,負為-1 char c; if ((c = *str) == '-' || c == '+') { ns = c == '-' ? -1.0 : 1.0; //正負號檢測, 1表示負數 ++str; } //處理整數部分 for (c = *str; c >= '0' && c <= '9'; c = *++str) n = n * 10 + c - '0'; if (c == '.') for (; (c = *++str) >= '0' && c <= '9'; --nd) n = n * 10 + c - '0'; // 處理科學計數法 if (c == 'e' || c == 'E') { if ((c = *++str) == '+') //處理指數部分 ++str; else if (c == '-') es = -1, ++str; for (; (c = *str) >= '0' && c <= '9'; ++str) e = e * 10 + c - '0'; } //返回最終結果 number = +/- number.fraction * 10^+/- exponent n = ns * n * pow(10.0, nd + es * e); item->vd = n; item->type = _CJSON_NUMBER; return str; } // 跳過不需要處理的字元 static const char* __skip(const char


