
首先聲明:未經本人同意,請勿轉載,謝謝! 本人使用自己編譯的開源版本的greenplum資料庫用於學習,版本為PostgreSQL 8.3.23 (Greenplum Database 4.3.99.00 build dev) on x86_64-unknown-linux-gnu, compile ...
首先聲明:未經本人同意,請勿轉載,謝謝!
本人使用自己編譯的開源版本的greenplum資料庫用於學習,版本為PostgreSQL 8.3.23 (Greenplum Database 4.3.99.00 build dev) on x86_64-unknown-linux-gnu, compiled by GCC gcc (GCC) 4.8.5 20150623
在使用的過程中遇到不少的問題,今天記錄一下高併發的情況下,執行insert和vacuum操作造成的死鎖,以及解決方案
一、問題描述:
在對ao分區表進行高併發測試的時候同時執行了vacuum的動作,發現會有死鎖的問題產生,可以通過如下手段復現:
1)多個線程迴圈執行insert into t3 select * from XX(t3為本例中用於測試的分區表),為了提高問題復現的速度,可以僅對錶中的一個分區進行操作
2)單個線程迴圈執行vacuum的動作
一段時間後會發現vacuum和insert都卡住,至此問題被覆現出來。
二、結論:
該問題僅在AO分區表中會出現,產生的原因是由於資料庫加鎖的流程設計不合理導致(詳情見分析過程)。
三、問題定位及解決方案
拋磚引玉,僅分享自己知道的一點點東西,如果有錯誤的地方還請指正,歡迎大家一起來討論這個問題。
1)首先連接master執行:
select * from pg_stat_activity;
查到如下結果:

(圖一)
發現有一個session是lock狀態,為了弄清楚這裡的lock的具體情況,則連接master和standby查看鎖的具體情況,執行如下sql:
select a.locktype,b.relname,substring(c.current_query,1,50),c.xact_start,a.pid,a.mode,a.granted from pg_locks a,pg_class b,pg_stat_activity c where a.relation = b.oid and a.pid = c.procpid and relname like 't3%';
master:

(圖二)
segment1:

(圖三)
segment2:

(圖四)
需要註意的是,這裡圖三和圖四中在pg_stat_activity表中的current_query一列有<IDLE> in transaction,這裡的值和我們平時看到的<IDLE>不是一回事,並不是一個空閑的連接,要弄清楚它的意義來看下官方文檔:

(圖五)
官方的文檔里,對該值僅有這麼一小段描述,這裡並不能完全的表達出這個欄位的意思,我們來看源碼:
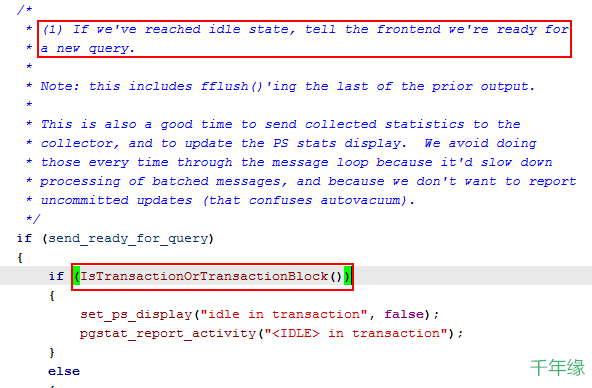
(圖六)
源碼里就可以看出這種狀態說明該連接的事務是處於阻塞狀態。
那麼又是為什麼會有鎖等待的出現呢,因為同一時間,針對同一個對象,有些鎖是不能夠同時被不同的事務所持有的,如果一個事務持有了某個鎖,另一個事務需要獲取相同的鎖或者是與這個鎖衝突的鎖,就會出現等待的情況,我們來看下鎖之間的衝突情況:

(圖七)
綜合以上的所有信息,畫出瞭如下的圖:
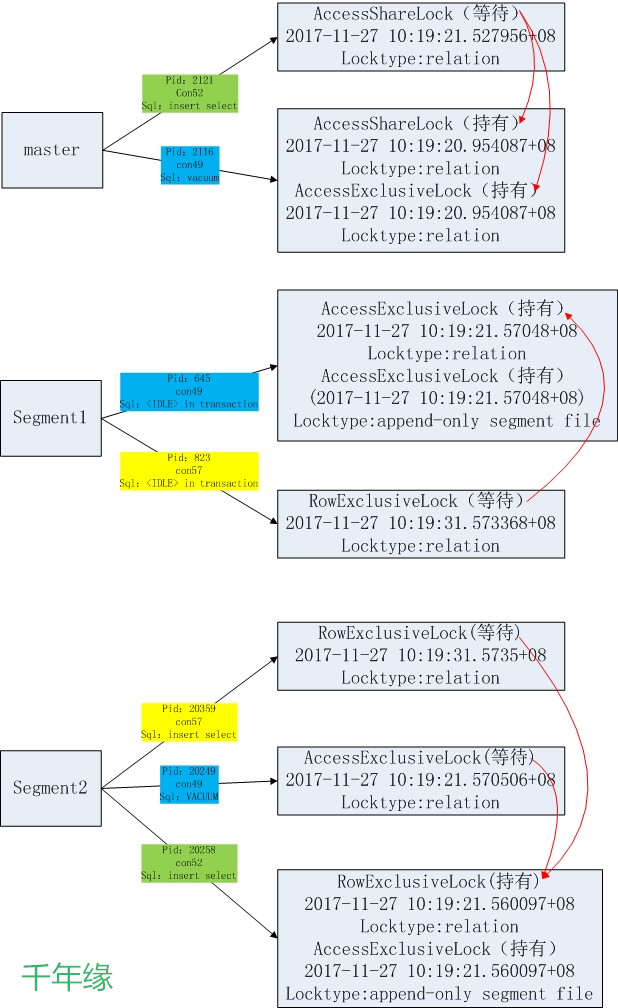
(圖七)
說明:
相同顏色的色塊表示同一個連接(在物理機上,由ps -ef | grep $pid查到的con確定),紅色的線表示等待關係。
由上圖可以清晰的看出,在master上,con52等待con49持有的鎖,而在segment2中,con49等待con52持有的鎖,因此產生了死鎖。 那麼又是什麼造成了這種鎖的狀態的形成?官方的描述中AccessShareLock僅僅是在對錶數據不產生任何影響的查詢語句才會申請: (圖八)
這裡看圖七的master節點,明明產生的是AccessShareLock,與官方的描述出現了不一致,對於這個疑惑,只有源碼能告訴我們答案:
(圖八)
這裡看圖七的master節點,明明產生的是AccessShareLock,與官方的描述出現了不一致,對於這個疑惑,只有源碼能告訴我們答案:
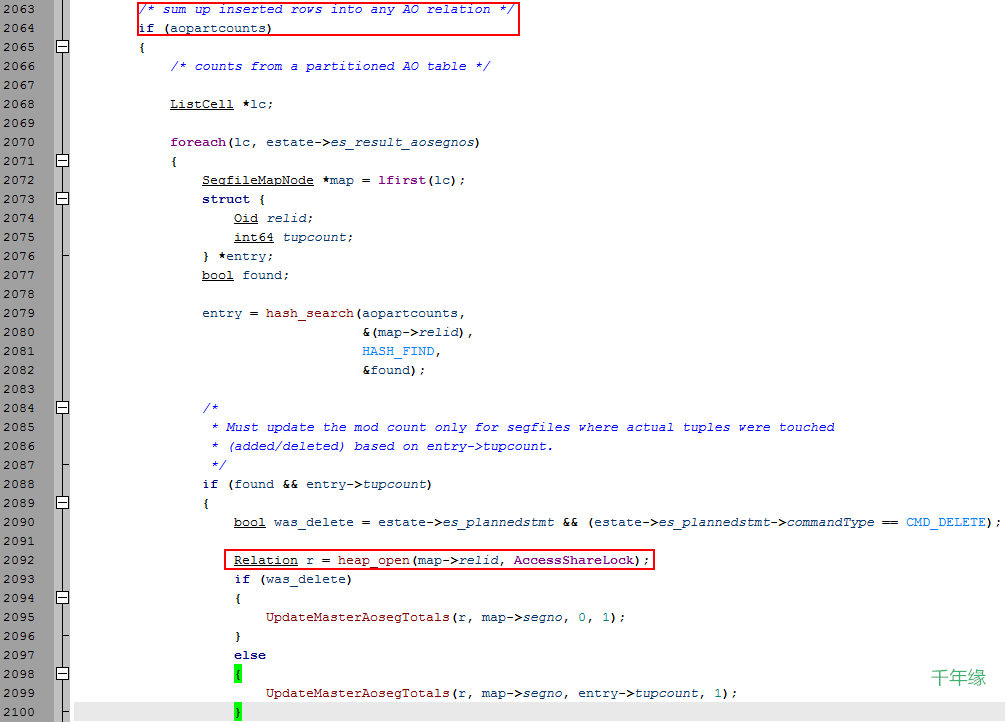 (圖九)
這裡有個if條件,這說明在處理ao分區表的時候,會在處理完成後會在master上加上AccessShareLock,結合圖七和圖九,也就解釋了為什麼在master會產生insert的鎖等待vacuum的情況了,同時也回答了為什麼結論中說該問題僅會出現在ao分區表中。
至此,產生這個問題的原因基本明晰了,那麼遇到了這種情況該如何解決?
要知道不同的鎖之間誰等待了誰,提供如下sql,很方便的就能知道等待關係:
(圖九)
這裡有個if條件,這說明在處理ao分區表的時候,會在處理完成後會在master上加上AccessShareLock,結合圖七和圖九,也就解釋了為什麼在master會產生insert的鎖等待vacuum的情況了,同時也回答了為什麼結論中說該問題僅會出現在ao分區表中。
至此,產生這個問題的原因基本明晰了,那麼遇到了這種情況該如何解決?
要知道不同的鎖之間誰等待了誰,提供如下sql,很方便的就能知道等待關係:
create or replace function f_lock_level(i_mode text) returns integer as $$
begin
RETURN (select case i_mode
when 'INVALID' then 0
when 'AccessShareLock' then 1
when 'RowShareLock' then 2
when 'RowExclusiveLock' then 3
when 'ShareUpdateExclusiveLock' then 4
when 'ShareLock' then 5
when 'ShareRowExclusiveLock' then 6
when 'ExclusiveLock' then 7
when 'AccessExclusiveLock' then 8
else 0
end );
end;
$$ language plpgsql strict;
--查詢
with t_wait as
(select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.objid,a.objsubid,
a.pid,a.virtualtransaction,a.virtualxid,a,transactionid,b.current_query,b.xact_start,b.query_start,
b.usename,b.datname from pg_locks a,pg_stat_activity b where a.pid=b.procpid and not a.granted),
t_run as
(select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.objid,a.objsubid,
a.pid,a.virtualtransaction,a.virtualxid,a,transactionid,b.current_query,b.xact_start,b.query_start,
b.usename,b.datname from pg_locks a,pg_stat_activity b where a.pid=b.procpid and a.granted)
select r.locktype,r.mode r_mode,r.usename r_user,r.datname r_db,r.relation::regclass,r.pid r_pid,
r.page r_page,r.tuple r_tuple,r.xact_start r_xact_start,r.query_start r_query_start,
now()-r.query_start r_locktime,r.current_query r_query,w.mode w_mode,w.pid w_pid,w.page w_page,
w.tuple w_tuple,w.xact_start w_xact_start,w.query_start w_query_start,
now()-w.query_start w_locktime,w.current_query w_query
from t_wait w,t_run r where
r.locktype is not distinct from w.locktype and
r.database is not distinct from w.database and
r.relation is not distinct from w.relation and
r.page is not distinct from w.page and
r.tuple is not distinct from w.tuple and
r.classid is not distinct from w.classid and
r.objid is not distinct from w.objid and
r.objsubid is not distinct from w.objsubid and
r.transactionid is not distinct from w.transactionid and
r.pid <> w.pid
order by f_lock_level(w.mode)+f_lock_level(r.mode) desc,r.xact_start;
註意:上面的sql適用於文章開頭部分greenplum內核版本,不同的版本會有些許差異,這個sql是我根據文章最後參考資料德哥給出的SQL自己修改的,如果您的環境中無法運行,請使用德哥給出的語句。
該sql會返回類似如下的結果(部分):

(圖十)
每條結果以w_開頭的結果表示正在等待的會話信息,以r_開頭的代表正在運行的會話信息。 為了不影響正常的插入流程,可以找到vacuum語句的pid,使用select pg_terminate_backend($pid);語句終止vacuum的會話,業務即可繼續進行。 那麼問題是不是就此可以結束?其實並沒有,我們來看官方文檔: 官方指出,在發生死鎖的情況下,會自動的回滾一個事務,保證另一個事務的正常運行,那麼在上面所述的情況下,為什麼沒有發生事務的自動回滾?這是我一直沒有想明白的問題,如果有相關的專業人士看到這篇文章請指點一二,解答我心中的疑問,感激不盡!
參考資料:
https://yq.aliyun.com/articles/86631
https://github.com/greenplum-db/gpdb/pull/425
官方指出,在發生死鎖的情況下,會自動的回滾一個事務,保證另一個事務的正常運行,那麼在上面所述的情況下,為什麼沒有發生事務的自動回滾?這是我一直沒有想明白的問題,如果有相關的專業人士看到這篇文章請指點一二,解答我心中的疑問,感激不盡!
參考資料:
https://yq.aliyun.com/articles/86631
https://github.com/greenplum-db/gpdb/pull/425https://github.com/greenplum-db/gpdb/issues/2837 在github中,有提出使用debug的方式復現死鎖的問題,這是最快捷的方式,同時也給出了源碼級別的修複建議,感興趣的朋友可以自行閱讀。 結語: 本人一直做的是java的開發工作,C並不是特別熟悉,要解決這個問題,根本上還得從源碼入手,本人沒有這個能力,如果有朋友知道如何修複這個問題,還請告知。同時本文如有表述不對的地方,還請各位指出,我會加強自身的學習,保證分享出來的東西是正確的。 另外,推薦一個好朋友的公眾號,我覺得裡面文章特別好,很多問題是真正講清楚了,全都是他自己一點點整理出來的,我一直在讀他的文章,受益良多。


