正則表達式可以用來處理大量的文件和字元串,運維工作中過濾日記簡單高效,Linux最常應用正則表達式的命令有grep(egrep)、sed、awk。 正則表達式和文本通配符不同容易混淆。 字元匹配 . 匹配任意單個字元 [] 匹配指定範圍內的任意單個字元 [^] 匹配指定範圍外的任意單個字元 [:al ...
正則表達式可以用來處理大量的文件和字元串,運維工作中過濾日記簡單高效,Linux最常應用正則表達式的命令有grep(egrep)、sed、awk。
正則表達式和文本通配符不同容易混淆。
字元匹配
. 匹配任意單個字元
[] 匹配指定範圍內的任意單個字元
[^] 匹配指定範圍外的任意單個字元
[:alnum:] 字母和數字
[:alpha:] 代表任何英文大小寫字元,亦即A-Z, a-z
[:lower:] 小寫字母 [:upper:] 大寫字母
[:blank:] 空白字元(空格和製表符)
[:space:]水平和垂直的空白字元(比[:blank:]包含的範圍廣)
[:cntrl:] 不可列印的控制字元(退格、刪除、警鈴...)
[:digit:] 十進位數字[:xdigit:]十六進位數字
[:graph:] 可列印的非空白字元
[:print:] 可列印字元
[:punct:] 標點符號
匹配次數
* 匹配前面的字元任意次,包括0次,儘可能長的匹配
.*任意長度的任意字元
\?匹配其前面的字元0或1次
\+匹配其前面的字元至少1次
\{n\} 匹配前面的字元n次
\{m,n\} 匹配前面的字元至少m次,至多n次
\{,n\} 匹配前面的字元至多n次
\{n,\} 匹配前面的字元至少n次
位置錨定
^ 行首錨定,用於模式的最左側
$ 行尾錨定,用於模式的最右側
^PATTERN$ 用於模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或\b詞首錨定,用於單詞模式的左側
\> 或\b詞尾錨定;用於單詞模式的右側
\<PATTERN\>匹配整個單詞
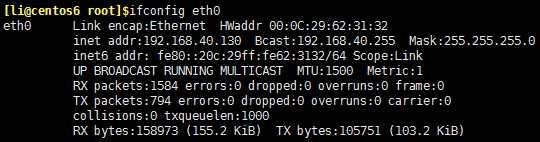
找出ifconfig eth0 命令結果中的IPv4地址

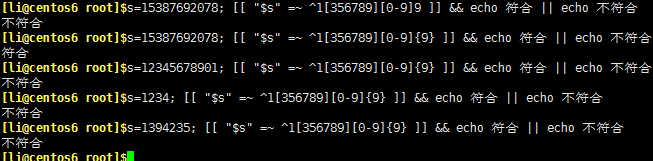
驗證手機號碼是否符合規範(擴展表達式)