
正所謂怕什麼來什麼,這是知名的“墨菲定律”。Java基礎涵蓋各個方面,敢說Java基礎扎實的人不是剛畢業的學生,就是工作N年的程式員。工作N年的程式員甚至也不敢人人都說Java基礎扎實,甚至精通,往往只是“無他唯熟爾”——熟手而已。 IO這塊我確實怕,它不難,只有兩個方面:輸入/輸出。但你說它用得多 ...
正所謂怕什麼來什麼,這是知名的“墨菲定律”。Java基礎涵蓋各個方面,敢說Java基礎扎實的人不是剛畢業的學生,就是工作N年的程式員。工作N年的程式員甚至也不敢人人都說Java基礎扎實,甚至精通,往往只是“無他唯熟爾”——熟手而已。
IO這塊我確實怕,它不難,只有兩個方面:輸入/輸出。但你說它用得多不多,我相信沒有你寫的併發多,併發往往是處處可見,寫著寫著就熟了,而IO卻往往只是某個模塊會涉及,所以也就並不是每個程式員在開發維護自己的模塊時都會用到有關IO的API,而碰到的時候常常陷入窘迫,不知道怎麼寫。
我想研究IO這塊願意正是想鞏固自己的Java基礎,並希望能成為精通Java的那個人。 本文作為Java IO系列的開篇,首先要介紹幾個概念:位元組與字元。原因在於,Java IO的API分為位元組流和字元流,瞭解什麼是位元組和字元有助於我們後續IO的理解。
位元組(Byte)
電腦中存儲數據的一個單位。比它小的是位(bit,也叫比特),這是在電腦中數據存儲的最小計量單位,1位存放的是二進位的數據0和1,如下所示。
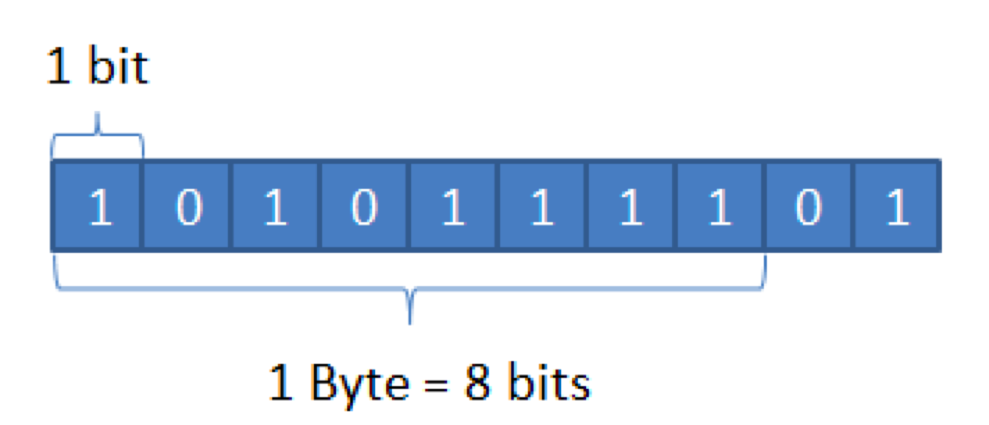
當然比位元組更大的是KB(千位元組),1KB = 1024B,再到後面就是MB(兆位元組),1MB = 1024KB,GB、TB……
Java中有用於表示位元組的數據類型——byte,再次不妨回顧下有關在Java中有關byte的一些知識。
前面提到1個位元組等於8個二進位位,那麼也就是說1個位元組能表示的最大數為[0, 255](閉區間),但是,在Java中byte類型是有符號型的,也就是說在它的最高位是符號位。也就是說除去最高位符號位,還剩下7個二進位位,那麼7個二進位所能表示的最大數為[0, 127],這是正數,加上最高位為1表示負數時,byte型數據類型所能表示的最大數為[-127, 0],也就是說byte型的數據範圍是[-127, 127],真的是這樣嗎?錯了。上面的分析是錯誤的。Java中byte型數據類型的取值範圍為[-128, 127]。
錯誤的原因是沒有考慮到電腦中數值存儲的編碼問題。所以這又會繼續延伸到原碼、反碼、補碼的概念。
- 原碼:最高位表示符號位,0表示正數,1表示負數,其餘位表示真實數值。前面的錯誤分析正是將電腦中數值存儲定義為了原碼,所以才會得到Java中byte型數據類型的取值範圍是[-127, 127]。
- 反碼:同樣最高位表示符號位,正數的反碼與原碼相同,而負數的反碼除符號位外,其餘位取反。
- 補碼:同樣最高位表示符號位,正數的反碼與原碼相同,而負數的補碼除符號位外,其餘位取反+1。電腦中數值的存儲正是補碼。
可以通過程式來觀察體會,電腦中數值存儲是通過補碼來存儲的。
System.out.println("正數3的二進位原碼為:11,其補碼與原碼相同為:" + Integer.toBinaryString(3));
System.out.println("負數-3的二進位原碼為:111,其補碼與為(int型占4bytes=32bits,只看最後的3位):" + Integer.toBinaryString(-3) + "(不信將最後三位補碼-1取反得到原碼)");
通過運算結果可以看到,電腦中的數值確實是以補碼方式存儲的。

在瞭解了原碼、反碼、補碼,以及知道電腦中數值是以補碼方式存儲過後,現在回到Java中byte型數據類型的範圍上來。就算是以補碼方式的存儲,可以確定的是在byte型數組中正數(最高位為0)的範圍是[0, 127]一共128個數,那麼負數(最高位為1)的原碼範圍則是[-127, -0],二進位也就是[11111111, 10000000],註意這是原碼,並且這個地方有點衝突,也就是出現了-0這種表示,這顯然是不合理的或者說0已經在正數中已經包括了,在這裡實際上byte型數組做了一定的處理,也就是把把-0的補碼當做了-128,-0的原碼是10000000,它的反碼則是11111111,它的補碼則還是10000000,反碼+1過後需要進位,但是最高位表示符號位,所以被擠掉了,總之此時負數的範圍則是[-128, 0),byte型數組的範圍則是[-128, 127]。原因是由於-0和0表示的都是0為避免浪費,將-0表示為-128擴大了範圍。
這一段我們通過位元組(Byte)這種表示電腦數據存儲的單位,延伸了Java中byte型數據類型的取值範圍,進而回顧了電腦中數值存儲的編碼方式,應該是能更好的理解位元組這個概念。下麵將介紹什麼又是字元。
字元(Char)
字元表示文字和符號。人與人之間通過人類語言進行溝通,電腦通過二進位來進行溝通,當人-電腦-人,中間多了電腦的媒介過後,中間就需要電腦對我們人類的語言符號“編碼”進行傳輸,而電腦-人這個過程又稱之為“解碼”。這有點類似“加密”“解密”的過程。
在電腦剛出現的時候只能傳輸英文字元,這裡的傳輸包括是顯示和存儲,前面提到要進行編碼存儲,既然要編碼就需要一張表來表示A是什麼,B是什麼,就好比摩斯密碼中的密碼本一樣。那時的“碼表”也就是編碼方式叫做ASCII。

電腦繼續在發展,需要發展到其他國家和地區,此時就需要對漢字、日文、韓文等進行編碼,但原有的ASCII肯定不能滿足,它的設計是包括了英文和符號,此時就出現了ANSI編碼(也叫做ASCII擴展),這實際上是一種規範,一種本地化的規範編碼,例如在中文操作系統中ANSI代表的就是GB2312編碼(當然也有它的擴展叫做GBK編碼),在日文操作系統中ANSI代表的就是JIS等等。ANSI編碼採用2個位元組來表示一個字元(範圍在0x80-0xFF),兩個位元組也就是16個二進位位,理論上可以表示216個字元,當然這需要減去0x00-0x79這個範圍,這就能表示很多很多的字元了。GB2312編碼也就才表示了6000多個常用漢字。不過這種編碼方式還是帶來了新的問題,這隻是做了本地化,也就是說在GB2312的編碼環境下,無法對日文進行編碼。所以還需要做國際化。
隨著電腦的繼續發展,國際化越來越重要這當然也就包括編碼方式的改變,為避免ANSI不相容的狀況,又制定了新的編碼規則——UNICODE。在Java中使用的就是UNICODE編碼,這符合Java跨平臺的特性,這也就解釋了Java中char字元的數據類型占用的是2個位元組,因為Java使用UNICODE編碼,而UNICODE是2個位元組表示1個字元。UNICODE解決了不同語言在不同平臺不相容的情況,但也有一個小小的弊端,也就是稍微比前面兩種要占空間,以UNICODE字元集在記憶體中存儲的字元串我們稱之為為“寬位元組字元串”,實際上之後對於字元編碼的工作就集中在瞭如何縮短位元組空間上。 這裡就著重介紹UNICODE編碼,UNICODE編碼之所以略占空間,是因為它使用2個位元組來表示1個字元。就算是英文也是使用2個位元組。而ACSII和ANSI則使用1個位元組表示英文。空間的占用就體現在了這個地方,如下圖所示。
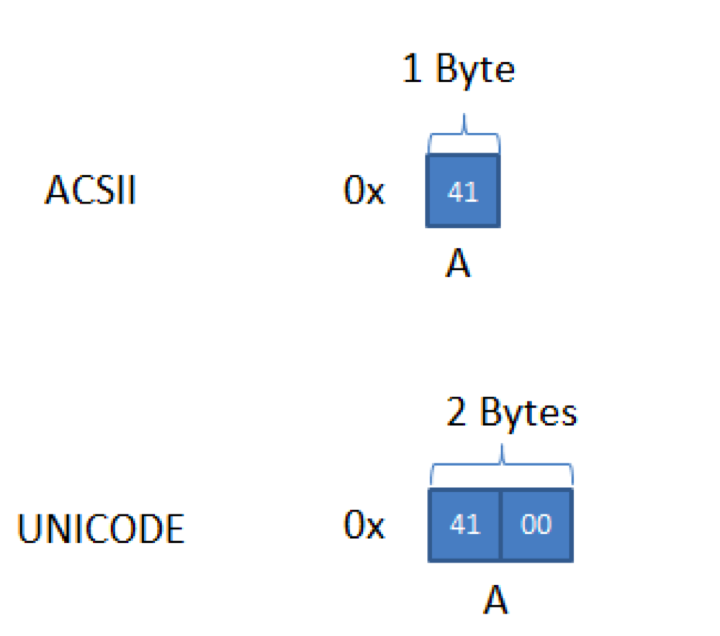
可以看出,這就白白地浪費掉了1個位元組的空間,在這裡實際上又可以繼續延伸出有關電腦基礎的知識,也就是在電腦中的數據在記憶體中的存儲方式是大端模式(Big-Endian,也稱高位元組在前),還是小端模式(Little-Endian,也稱低位元組在前)。所謂大端模式就是高位位元組在記憶體的低地址端,低位位元組在記憶體的高地址端。而小端模式則是高位位元組在記憶體的高地址端,低位位元組在記憶體的低地址端。上圖所示方式就是大端模式,可以看到低位位元組跑到了地址的左邊也就是高地址端。需要清楚的是Java中採用的是大端模式。
繼續回到編碼上來,由於UNICODE給任意字元都是採用的2個位元組表示1個字元,會造成空間浪費,所以在UNICODE編碼基礎上,又出現了可變長編碼的UTF-8編碼,這種編碼方式會靈活地進行字元的空間分配,不同字元所占用的記憶體空間不相同,在保證相容性的同時,也保證了空間的最合理使用。
這就是Java IO的基礎知識,為的是便於後面Java IO中有關位元組流和字元流的更好理解。
這是一個能給程式員加buff的公眾號


