
前面已經對BeautifulSoup有了瞭解了,相信你基本已經學會怎麼獲取網頁數據了,那麼BeautifulSoup這麼弔,還有沒有其他的功能呢?當然是有的 前面說的Tag對象都還記得吧?像這樣BeautifulSoup.title,得到的就是Tag對象,它其實還有一些屬性: 1.contents: ...
說明一下,這個標題可能有點突兀,結合上一篇一起看就行
前面已經對BeautifulSoup有了瞭解了,相信你基本已經學會怎麼獲取網頁數據了,那麼BeautifulSoup這麼弔,還有沒有其他的功能呢?當然是有的
前面說的Tag對象都還記得吧?像這樣BeautifulSoup.title,得到的就是Tag對象,它其實還有一些屬性:
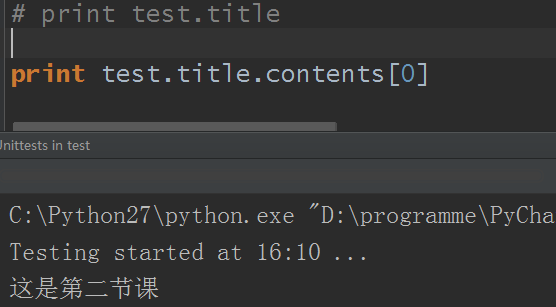
1.contents:將tag的子節點以列表的方式輸出
還是前面的例子:
# -*- coding:utf-8 -*-
import bs4
html='''
<html>
<head>
<title>這是第二節課</title>
<meta charset='utf-8'> <!--meta是單標簽-->
<meta name='keywords' content='hello world,oh yeah'>
</head>
<!--<body bgcolor='green'>-->
<body link='red' vinlk='green' alink='blue'>
<h1>這是一個標題</h1>
<!--超鏈接必須加上http://不然無法跳轉-->
<a href='http://www.baidu.com'>百度</a>
<a href='http://www.163.com'>網易</a>
<a href='http://www.qq.com'>騰訊</a>
<a href='http://www.sina.com'>新浪</a>
</body>
</html>
'''
test=bs4.BeautifulSoup(html,'html.parser')
print test.title
print test.title.contents
結果:
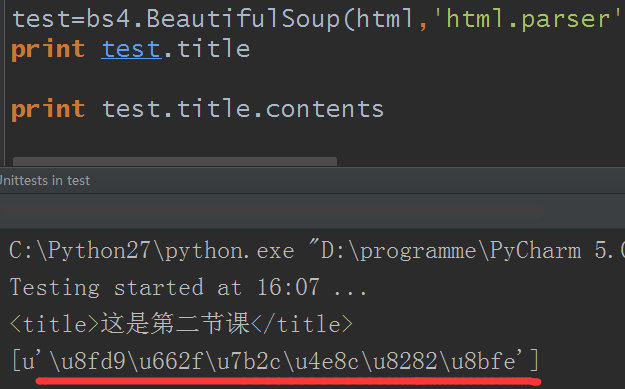
字元型是utf-8,而我用的是python2,前面編碼問題已經說過了,略過
既然是列表對吧,那麼它就可以使用列表的方法了:
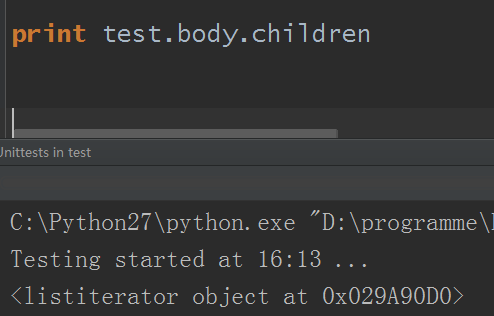
2.children:返回一個列表迭代器
既然是迭代器,那麼就可以迭代出來了:
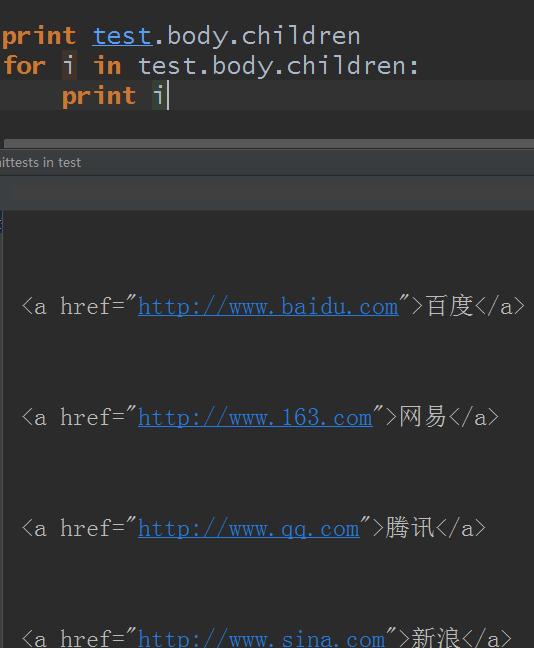
其實BeautifulSoup對象也有類似tag對象的children的屬性:
3.descendants:類似tag對象的children的屬性,不過返回的是一個生成器對象
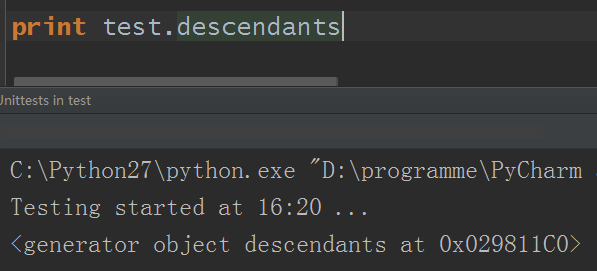
同樣的,使用for迴圈也可以迭代出來,這裡直接略過。
上面的contents和children是什麼屬性呢?官方文檔里有個稱呼叫Tag對象的直接子節點。而descendants是BeautifulSoup的子孫節點。
4.什麼是節點呢?
結合我個人的理解:這裡牽扯到一個知識點,樹形結構知道嗎?就是只某樣事物類似樹枝一樣,由樹幹延伸到樹枝,樹枝再延伸到小樹枝……這樣不斷的蔓延伸展,這種就是樹形結構,而每一個過渡點就叫做節點。那麼這裡的html文檔就好比一棵樹,然後利用BeautifulSoup模塊生成了BeautifulSoup對象,BeautifulSoup對象下麵每一個屬性就是一個節點,屬性下麵又有一個子節點,然後descendants其實就是BeautifulSoup對象的直接子節點,而contents和children就是由BeautifulSoup對象結合html標簽生成的Tag對象的直接子節點(有點遞歸的意思,你可以結合理解)
既然有節點,結合上一篇說的,我們可以在Tag對象下使用string子節點屬性獲得html代碼內的字元串內容,那麼這樣的內容就叫節點內容
我相信,你在自己動手練習時,一定遇到這種情況:
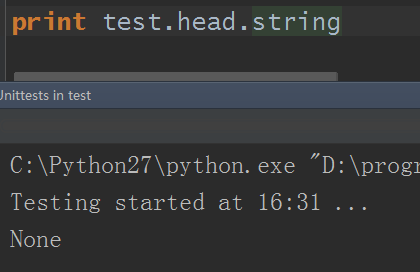
怎麼是None呢?html里不是有數據title標簽和meta標簽等的嗎?對吧?那麼這為何是空呢?這裡就是string屬性的一個特性而來。
string屬性特性:
官方文檔是這麼說的:
如果tag只有一個NavigableString類型(忘記什麼是NavigableString類型回去看上一篇博文)子節點,那麼這個tag可以使用string屬性得到子節點。如果一個tag僅有一個子節點,那麼這個tag也可以使用string屬性,輸出結果與當前唯一子節點的string屬性結果相同。
換句話就是:
- 如果一個標簽裡面沒有子標簽了,那麼 string屬性就會返回標簽裡面的內容。如果標簽裡面只有唯一的一個子標簽了,那麼string屬性也會返回最裡面的內容
- 如果tag包含了多個子節點(子標簽),tag就無法確定string屬性應該調用哪個子節點的內容而返回None
那有朋友說,我就想返回多個內容怎麼辦?使用strings屬性和stripped_strings屬性
5.strings:獲取多個內容,返回一個生成器對象:
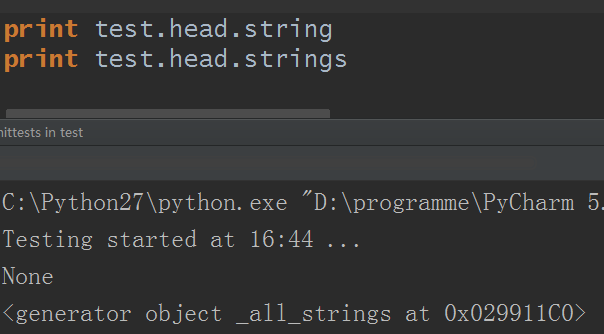
遍歷就直接略過了,你使用工程函數list轉為列表或者用for迭代或者轉為字元串或者使用函數repr輸出都隨便你了
6.stripped_strings :(看單詞意思估計你都能猜到幹嘛的了)同strings返回一個生成器對象,不過生成器對象內的元素已自動去除多餘空白內容:
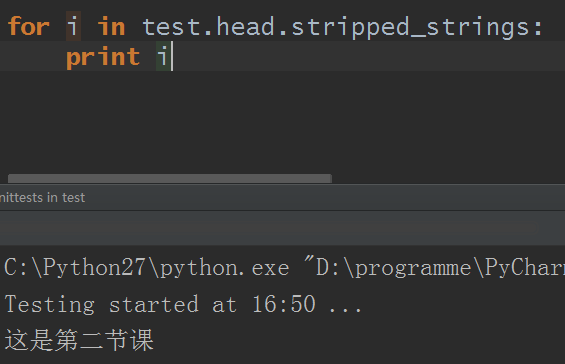
因為只返回字元串內容,而我那個html源碼例子里屬於head標簽的只有這一句字元串內容,所以結果如上。
那麼既然有子節點,自然還有父節點,前後節點,兄弟節點等等的。
7.父節點:parent屬性,即就是當前節點的父級節點
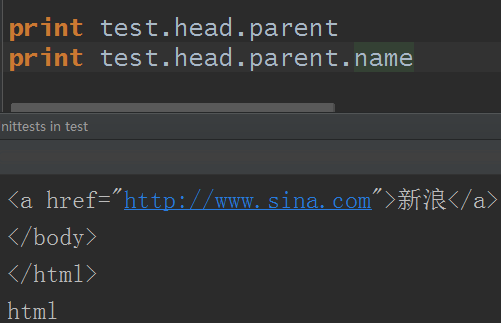
使用parent屬性會列印父級節點所有內容,使用parent.name屬性則顯示父級節點的名字
當然你會想,還有和父級節點同級的節點
8.全部父級節點:parents屬性
同parents,略過
9.兄弟節點:和當前節點同一級別的節點
- next_sibling屬性獲取該節點的下一個兄弟節點
- previous_sibling屬性獲取當前節點的上一個兄弟節點,如果節點不存在,則返回 None
實際文檔中的tag的 .next_sibling 和 .previous_sibling 屬性通常是字元串或空白,因為空白或者換行也可以被視作一個節點,所以得到的結果可能是空白或者換行。
可以利用next_sibling.next_sibling獲得下一個兄弟節點:
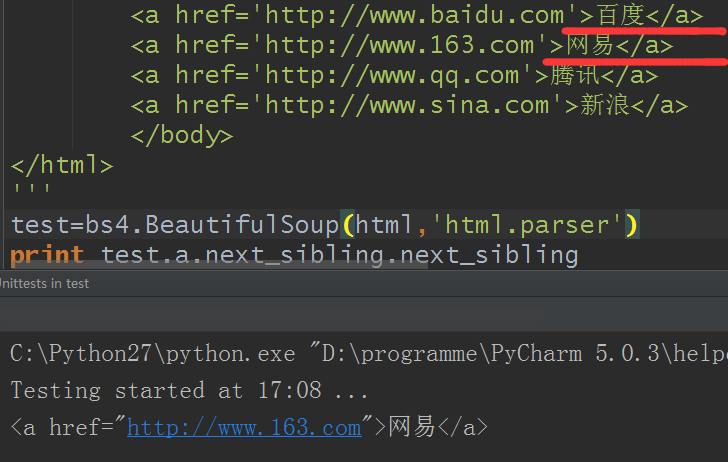
當然上一個兄弟節點也同樣,略過
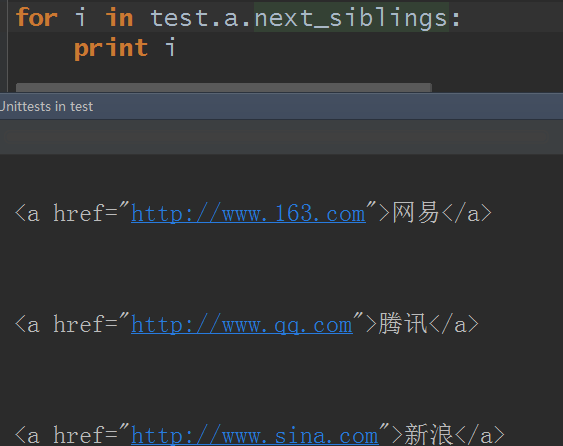
10.全部兄弟節點:獲得當前節點的兄弟節點並返回一個生成器,使用屬性next_siblings和previous_siblings
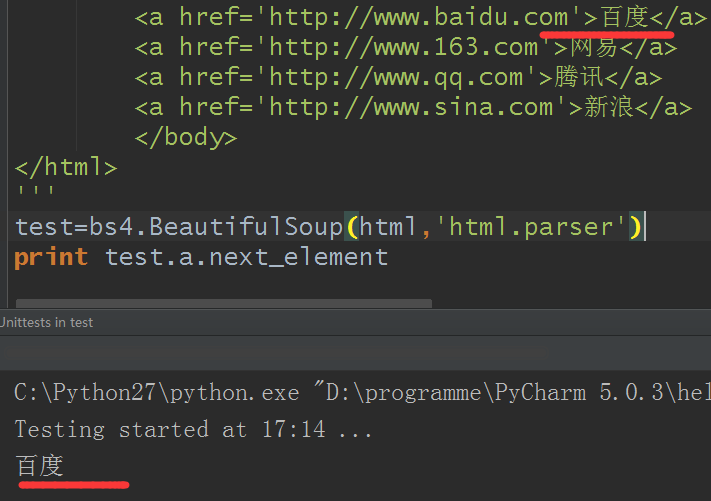
11.前後節點:與 next_sibling和previous_sibling不同,它並不是針對於兄弟節點,而是在所有節點,不分層次,誰在前就是前節點,誰在後就是後節點。使用next_element和previous_element
12.所有前後節點:向前或向後訪問文檔節點內容,返回一個生成器。使用next_elements和previous_elements 屬性
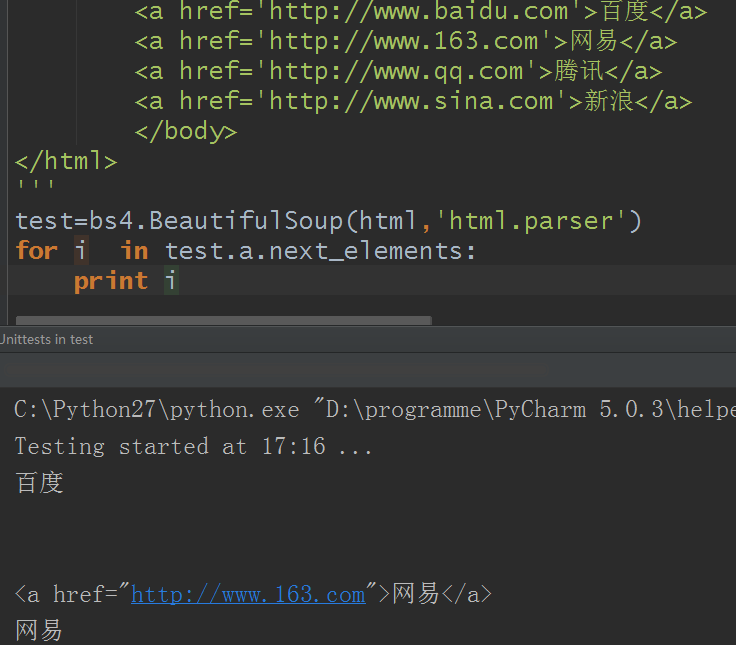
既然BeautifulSoup這麼強大,那麼也可以搜索文檔內容吧?是的
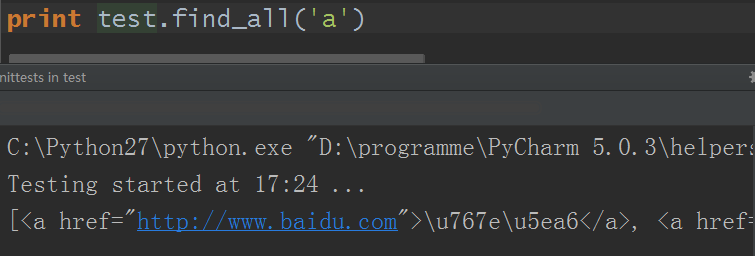
13. find_all( name , attrs , recursive , text , **kwargs ):搜索當前tag的所有tag子節點,以列表形式返回符合條件的所有tag對象,name參數即待搜索的html標簽名
name參數:
1)name參數可以是一個字元串對象,即html標簽
2)name參數可以是一個正則表達式,BeautifulSoup對象會預設使用正則表達式的match()方法匹配
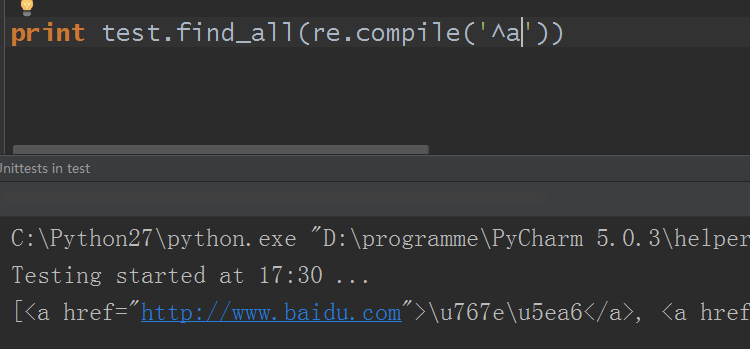
這個就厲害了對吧?
3)name參數可以是一個列表,BeautifulSoup對象會將與列表中任一元素匹配的內容返回
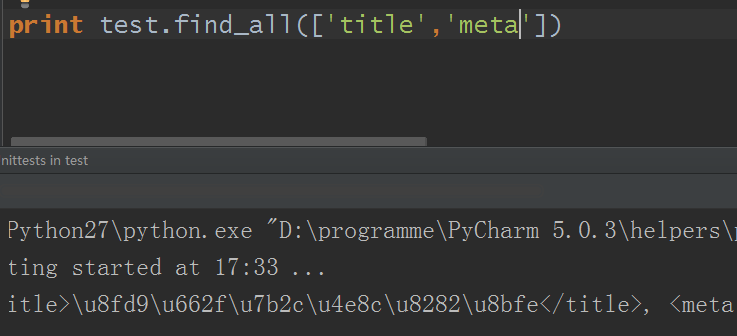
4)name參數可以是Bool函數的True,True即代表可以匹配任何值(即所有值)
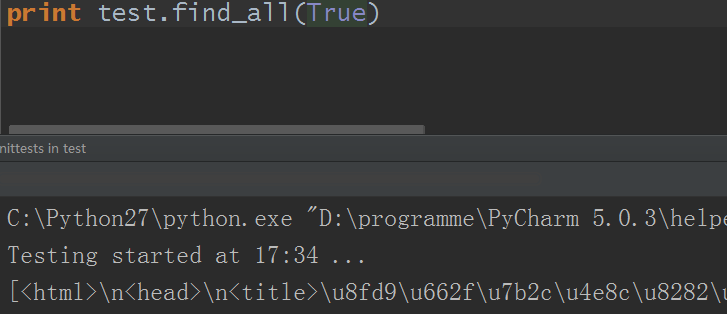
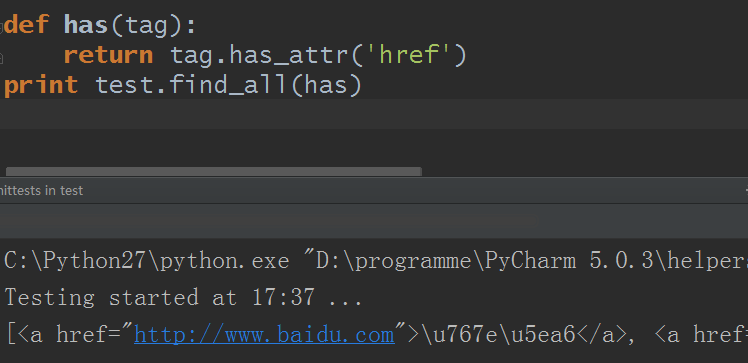
5)name參數可以是一個函數/方法
自定義了一個has方法,只返回擁有href屬性的標簽
keyword參數
- 如果一個指定名字的參數不是搜索內置的參數名,搜索時會把該參數當作指定名字tag的屬性來搜索
- 如果包含一個名字為id的參數,BeautifulSoup對象會搜索每個tag的”id”屬性
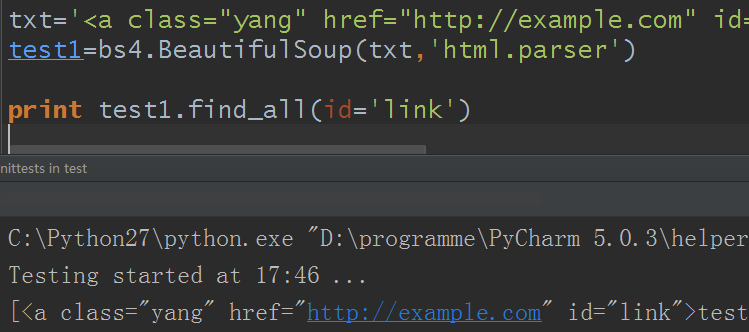
1)如果參數是id:
由於前面的html標簽里沒有適合的標簽,所以這裡新設一個例子
txt='<a class="yang" href="http://example.com" id="link">test</a>'
test1=bs4.BeautifulSoup(txt,'html.parser')
print test1.find_all(id='link')
結果:
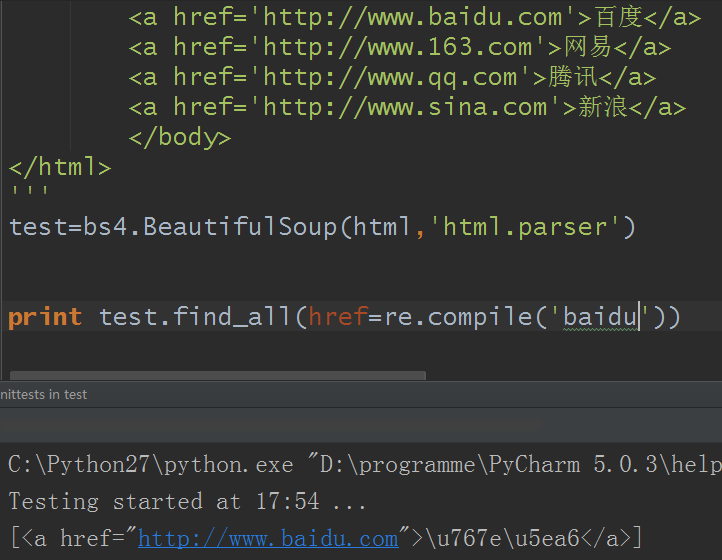
2)如果參數是href:
還是原來的例子
當然你可以使用多個指定名字的參數可以同時過濾tag的多個屬性。略過
註意:
- 當關鍵詞是class時,由於class也是python的關鍵詞語句,當作關鍵詞使用時,使用【class_】就行
- 當遇到特殊情況不能被搜索時,可以使用attrs參數定義一個字典參數來搜索包含特殊屬性的tag
不過以上情況基本少見,略過
text參數:可以搜索文檔中的字元串內容,與name參數的可選值一樣,可以是字元串 , 正則表達式 , 列表, True
略過
limit參數:如果文檔很大那麼搜索會很慢,而我們並不需要全部結果,使用limit參數限制返回結果的數量,效果與SQL中的limit關鍵字類似,當搜索到的結果數量達到limit的限制時,就停止搜索返回結果。
limit參數在很多地方都有用到
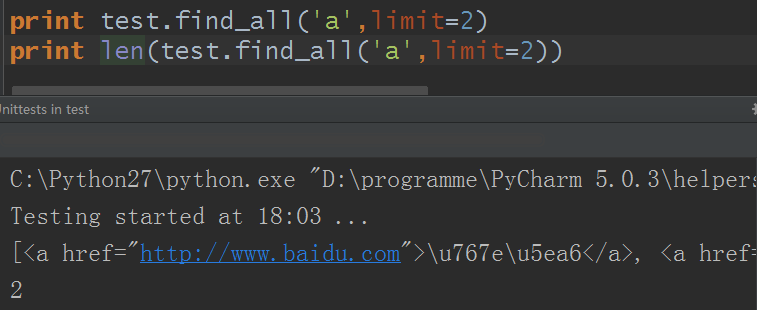
本來html代碼里有四個a標簽,設置limit參數後只得到兩個值
recursive參數:recursive值預設為True,即BeautifulSoup對象會預設檢索當前tag的所有子孫節點,如果只想搜索tag的直接子節點,可以使用參數recursive=False
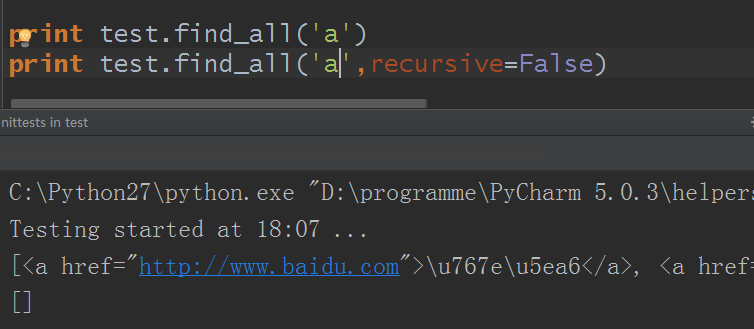
使用與不使用的差別
14.還有以下這些方法,使用基本和find_all類似,所以直接略過:
find( name,attrs, recursive, text, **kwargs ): 類似find_all(),不過find() 方法直接返回結果
find_parents()和find_parent()
find_all() 和 find()只搜索當前節點的所有子節點,孫子節點等。find_parents() 和 find_parent() 用來搜索當前節點的父輩節點,搜索方法與普通tag的搜索方法相同,搜索文檔搜索文檔包含的內容
find_next_siblings()和find_next_sibling()
這2個方法通過next_siblings 屬性對當 tag 的所有後面解析的兄弟 tag 節點進行迭代, find_next_siblings() 方法返回所有符合條件的後面的兄弟節點,find_next_sibling() 只返回符合條件的後面的第一個tag節點
find_previous_siblings()和find_previous_sibling()
這2個方法通過previous_siblings 屬性對當前 tag 的前面解析的兄弟 tag 節點進行迭代, find_previous_siblings() 方法返回所有符合條件的前面的兄弟節點, find_previous_sibling() 方法返回第一個符合條件的前面的兄弟節點
find_all_next()和find_next()
這2個方法通過next_elements 屬性對當前 tag 的之後的 tag 和字元串進行迭代, find_all_next() 方法返回所有符合條件的節點, find_next() 方法返回第一個符合條件的節點
find_all_previous() 和 find_previous()
這2個方法通過previous_elements 屬性對當前節點前面的 tag 和字元串進行迭代, find_all_previous() 方法返回所有符合條件的節點, find_previous()方法返回第一個符合條件的節點
那有朋友說,假如html代碼里有css樣式表等使用符號【#】的又怎麼處理呢?
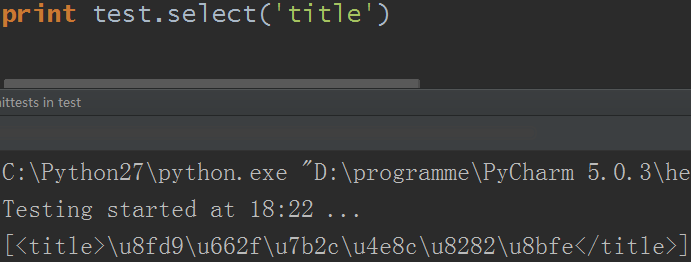
15.select()方法
可以對css樣式表查詢,返回列表對象
1)通過標簽名查找
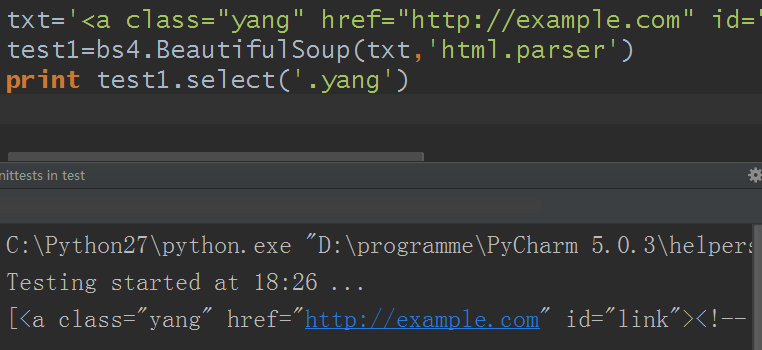
2)通過class類名查找
那個常用例子並沒有class的,所以另設一個例子
txt='<a class="yang" href="http://example.com" id="link"><!-- test --></a>'
test1=bs4.BeautifulSoup(txt,'html.parser')
print test1.select('.yang')
結果:
3)通過 id 名查找
與通過class查找一樣:
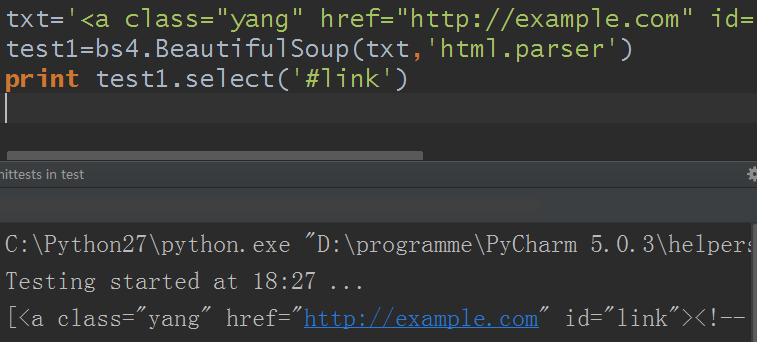
txt='<a class="yang" href="http://example.com" id="link"><!-- test --></a>'
test1=bs4.BeautifulSoup(txt,'html.parser')
print test1.select('#link')
結果:
4)組合查找
組合使用標簽名與類名、id名進行查找,和單獨查找原理一樣,註意不在同一節點的空格隔開,同一節點的不加空格。詳細的略過
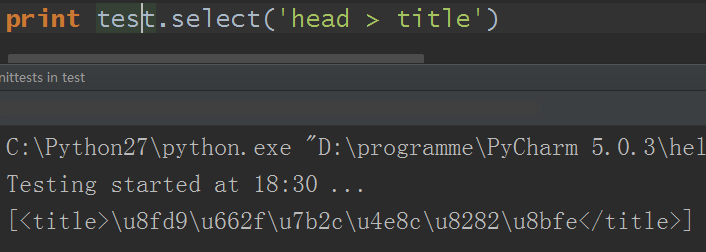
5)子標簽查找
原來的例子:
6)屬性查找
可以加入屬性元素,屬性需要用中括弧括起來,註意屬性和標簽屬於同一節點,所以中間不能加空格,否則會無法匹配到
屬性查找同樣可以與上面的查找方式組合,不在同一節點的空格隔開,同一節點的不加空格
註意:
- select()返回的既然是列表,那麼可以運用所有符合列表的方法,自己去發現了
- 利用select()可以達到同find_all效果相同
內容比較多,其實官方的文檔都還有些,不過那些基本不怎麼用了,所以就這些吧,只有查找提取的方法,這已經完完全全的夠用了

