
一:概述 當我們設計一個系統時,需要考慮到系統的運行一段時間後,表裡數據量大約有多少,如果在初期,就能估算到某幾張表數據量非常龐大時(比如聊天消息表),就要把表創建好,這篇文章從創建表,增加數據,以及欄位擴展,這幾個方面來給出建議。 二:創建表 假如現在我們需要創建IM項目中的聊天消息表,這個表數據 ...
一:概述
當我們設計一個系統時,需要考慮到系統的運行一段時間後,表裡數據量大約有多少,如果在初期,就能估算到某幾張表數據量非常龐大時(比如聊天消息表),就要把表創建好,這篇文章從創建表,增加數據,以及欄位擴展,這幾個方面來給出建議。
二:創建表
假如現在我們需要創建IM項目中的聊天消息表,這個表數據量大,讀操作遠超過寫操作,我們都知道,mysql常用的資料庫引擎主要有innodb,myisam,這兩個資料庫引擎主要區別是,innodb支持事務,支持外鍵,鎖是行級鎖(行級鎖只是針對主鍵,非主鍵也會鎖全表),myisam不支持事務,不支持外鍵約束,鎖是表級鎖,從性能角度分析,myisam要比innodb更好一些,所以在資料庫引擎上,我選擇myisam,另外在消息發送用戶id和消息接收用戶id上加索引。
1:數據類型的選擇
由於考慮到數據量非常大,所以在欄位數據類型選擇時,能用數字的就不要用字元串,當然時間類型也要用bigint來代替,不建議使用text類型,在varchar欄位上建議創建預設值,比如:default '' ,因為where 使用 is null是全表掃描,數字類型也需要加預設值,比如 num int default 0,如果不加預設值,並且執行insert 語句,也沒有對該欄位賦值,哪麽執行update xxx set num = num +1 時,你會發現sql不報錯,然後num的值卻沒更新到,另外需要在作為條件查詢的欄位加索引.
2:表分區
在大數據面前,除了數據類型和性能有很大關係之外,我們還可以使用表分區,分表和分庫目前還用不上,表分區概念
2.1 表分區概念
range分區:基於屬於一個給定連續區間的列值,把多行分配給分區。
list分區:和range分區類似,區別是list分區是基於列值匹配一個離散值集合中的某個值來進行選擇。
hash分區:基於用戶定義的表達式的返回值來進行選擇的分區,該表達式使用將要插入到表中的這些行的列值進行計算。
KEY分區:類似於按HASH分區,區別在於KEY分區只支持計算一列或多列,且MySQL伺服器提供其自身的哈希函數。必須有一列或多列包含>整數值。
可以使用SHOW VARIABLES LIKE '%partition%';來確定mysql支持的分區類型.
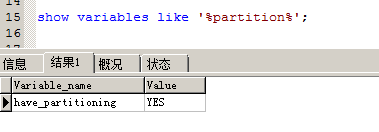
現在我使用range分區,分區欄位是pk,完整sql語句如下
CREATE TABLE chatmsg( cid bigint primary key, cMsgSendUserId bigint, cMsgReceiverUserId bigint, cTime bigint, cContent varchar(2000) not null default '', cExt varchar(5000) ) ENGINE=MYISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin PARTITION BY RANGE (cid) ( PARTITION p0 VALUES LESS THAN (1000000), PARTITION p1 VALUES LESS THAN (5000000), PARTITION p2 VALUES LESS THAN (1000000), PARTITION p3 VALUES LESS THAN MAXVALUE ) ; create index senduserid_index on chatmsg(cMsgSendUserId); create index receiverid_index on chatmsg(cMsgReceiverUserId); create index ctime_index on chatmsg(ctime);
三:添加聊天記錄。
從建表語句中看到,我們並沒有使用外鍵,所以就需要手動檢查外鍵約束的完整性。
select count(1) from user where uid = 消息發送者id union all select count(1) from user where uid = 消息接收者id
當上面的語句返回結果等於2時,才能執行添加語句。優化查詢語句,可以參考我的這一篇文章:百萬數據量優化方案
四:擴展欄位
假如現在表已經產生了5千萬條數據,產品經理過來說,小王,聊天記錄需要加一個已讀或未讀的狀態,如果此時在正式使用環境去alter tableadd column,可以想像這個操作有多耗時,有可能資料庫直接崩潰都說不定,數據量大了,進行alter tableadd column操作資料庫真崩潰過,不是危言聳聽,還記得在建表的時候,我們創建了一個cExt欄位,這個欄位我們記錄一個json 字元串,其實正確做法還要加一個版本號,這裡我就沒有加版本號。表裡面的數據如下:
select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 100 and cMsgReceiverUserId = 200 union ALL select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 200 and cMsgReceiverUserId = 100
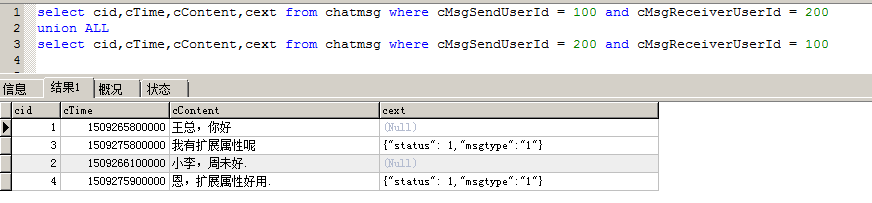
這個方法能解決大部分擴展欄位,查詢出cext後,然後把該值轉換為對像就可以。如果新增的欄位,需要出現在where中,就需要根據實際情況進行分析了。
cext擴展欄位優點:
(1)可以隨時動態擴展屬性
(2)新舊兩種數據可以同時存在
(3)遷移數據方便,寫個小程式將舊版本ext的改為新版本的ext,並修改version
cext擴展欄位不足:
(1)cext里的欄位無法建立索引
(2)cext里的key值有大量冗餘,建議key短一些
五:其它
比如項目初期,產品經理說,小王,我選擇任意兩個用戶,查詢這兩個人的聊天記錄,需要返回這兩個用戶的昵稱,產品經理選擇兩個用戶,我們得到了這兩個用戶的id,如果直接chat表join user表,性能同樣不好,這種情況我們可以考慮使用空間換時間,比如在聊天表中直接創建接收者和發送者的昵稱。這個方法表達的意思是,大數據表儘量不要join,性能是不好的,要用其它辦法來解決這個問題。當然在正式項目中,具體情況還需要具體分析。
我也會補充一些想法,如果文中有描述錯誤的地方,希望指出來,謝謝,歡迎大家發表自己的想法,大家共同進步。


