
索引是資料庫中用來提高性能的最常用的工具,本次博客就來介紹一下索引,mysql版本5.7.19。 索引概述 所有MySQL列類型都可以被索引,對相關的列使用索引是可以提高SELECT操作性能的最佳途徑。MyISAM和InnoDB存儲引擎預設是BTREE索引。其實索引就像是一個字典的目錄,你可以通過索 ...
索引是資料庫中用來提高性能的最常用的工具,本次博客就來介紹一下索引,mysql版本5.7.19。
索引概述
所有MySQL列類型都可以被索引,對相關的列使用索引是可以提高SELECT操作性能的最佳途徑。MyISAM和InnoDB存儲引擎預設是BTREE索引。其實索引就像是一個字典的目錄,你可以通過索引快速的定位到行的位置,索引會保存到額外的文件中。
索引的存儲分類和作用
索引是在MySQL的存儲引擎層中實現的,而不是在伺服器層實現的,所以每種存儲引擎的索引不一定完全相同,也不是所有的存儲引擎都支持所有的索引類型。
MySQL目前支持以下4種索引:
B-tree索引:最常見的索引類型,大部分存儲引擎都支持BTREE索引 HASH索引:只有MEMORY存儲引擎支持,使用的場景比較簡單 R-tree索引(空間索引):空間索引是MyISAM的一個特殊索引類型,主要用於地理空間數據類型,使用的較少 Full-text(全文索引):全文索引也是MyISAM的一個特殊索引類型,主要用於全文索引
三個常用引擎支持的索引:
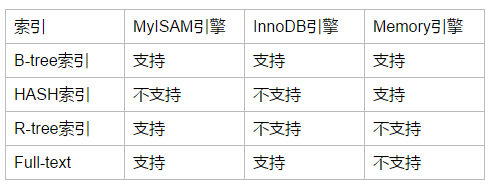
B-tree索引和HASH索引是比較常用的索引,HASH比較簡單,也只有Memory和Heap引擎支持,Hash索引適合鍵-值的查詢,且比B-Tree索引更快,但是hash索引不支持範圍的查詢,即如果Memory和heap引擎在where後面如果不使用“=”號的話,就不會使用Hash索引去查找,索引Memory和Heap只有在“=”的條件下才會使用Hash索引。
B-tree索引構造類似於二叉樹,能根據鍵值提供一行或者一個行集的快速訪問,通常只需要很少的讀操作就可以找到正確的行。B-tree的B不代表一個二叉樹,而是一個平衡樹(balanced),結構如下:
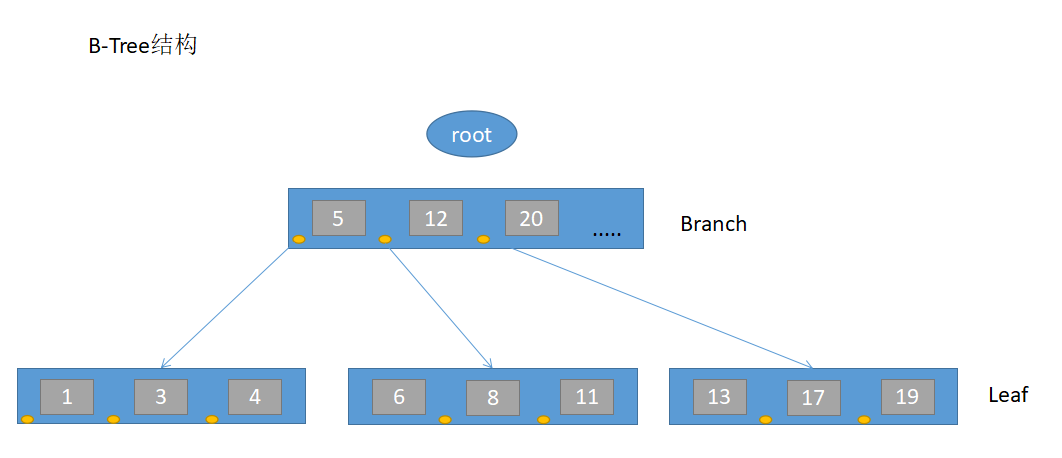
索引的存在可以加速查找,有的時候可以起到約束的作用。
索引的創建,刪除和修改
創建索引
CREATE INDEX index_name ON table(column1,column2,...columnN); --創建普通的索引 CREATE UNIQUE INDEX index_name ON table(column1,column2,...columnN); --創建唯一索引 ALTER TABLE table ADD PRIMARY KEY(column); --增加主鍵索引
刪除索引
DROP INDEX index_name ON table --刪除普通的索引 ALTER TABLE tabel DROP INDEX index_name --刪除索引 DROP UNIQUE INDEX index_name ON table --刪除唯一索引 ALTER TABLE table DROP PRIMARY KEY; --刪除主鍵索引 ALTER TABLE table MODIFY column INT,DROP PRIMARY KEY; --刪除主鍵索引
修改
對於MySQL5.7及以上版本,可以使用RENAME:
ALTER TABLE table_name RENAME INDEX old_index_name TO new_index_name;
對於MySQL5.7以前的版本,只能先刪除再增加了:
ALTER TABLE table_name DROP INDEX old_index_name; ALTER TABLE table_name ADD INDEX new_index_name(column_name);
舉例:


mysql> create index name_index on t3(name); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from t3 \G; *************************** 1. row *************************** Table: t3 Non_unique: 1 Key_name: name_index Seq_in_index: 1 Column_name: name Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: YES Index_type: BTREE Comment: Index_comment: 1 row in set (0.00 sec) mysql> mysql> mysql> alter table t3 rename index name_index to new_name_index; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from t3 \G; *************************** 1. row *************************** Table: t3 Non_unique: 1 Key_name: new_name_index Seq_in_index: 1 Column_name: name Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: YES Index_type: BTREE Comment: Index_comment: 1 row in set (0.00 sec)修改索引名稱
通過EXPLAIN分析低效SQL的執行計劃
現在有表如下:
mysql> show create table t1 \G; *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(20) DEFAULT NULL, `email` char(100) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> select count(*) from t1; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (1.25 sec)
id列為主鍵索引,都說索引可以加速查找,那麼來測試一下他是否可以加速查找:
mysql> select * from t1 where id=8888; +------+----------+-----------------+ | id | name | email | +------+----------+-----------------+ | 8888 | test8888 | test8888@qq.com | +------+----------+-----------------+ 1 row in set (0.00 sec) mysql> select * from t1 where name='test8888'; +------+----------+-----------------+ | id | name | email | +------+----------+-----------------+ | 8888 | test8888 | test8888@qq.com | +------+----------+-----------------+ 1 row in set (1.24 sec)
通過以上例子完全可以看出索引的存在可以加速行數據的查找。
這裡可以通過explain命令來分析SQL的執行計劃:
mysql> explain select * from t1 where id=8888; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
各個欄位的意思:
id:數字越大越先執行,當數字相同的時候,就從上往下執行,如果為null就表示是一個結果集,不需要使用它來進行查詢 select_type:常見的如下 simple:簡單表,即不使用表連接或者子查詢,有連接查詢時,外層的查詢為simple,有且只有一個; primary:需要union操作或者含有子查詢的select,位於最外層的單位查詢的select_type即為primary,有且只有一個; union:UNiON中的第二個或者後面的查詢語句; subquery:除了from字句中包含的子查詢外,其他地方出現的子查詢都可能是subquery; 除以上之外還有:dependent union,union result,dependent subquery,derived。 table:顯示查詢表名,如果使用的是別名,那麼這裡就是別名; type:表示MySQL在表中找到所需行的方式,或者叫訪問類型,常見的如下: +-----+--------+-------+------+--------+---------------+-------+ | ALL | index | range | ref | eq_ref | const,system | NULL | +-----+--------+-------+------+--------+---------------+-------+ 從左至右,性能由最差到最好。 possible_keys:表示查詢時可能使用的索引; key:表示實際使用的索引; partitions:顯示SQL所需要訪問的分區名字; key_len:使用到所以欄位的長度; rows:預估掃描行的數量; ref:如果是使用的常數等值查詢,這裡會顯示const; filtered:表示存儲引擎返回的數據在server層過濾後,剩下多少滿足查詢的記錄數量的比例,註意是百分比; extra:常見的如下: distinct:在select部分使用了distinc關鍵字; no tables used:不帶from字句的查詢; using filesort:排序時無法使用到索引時; using index:查詢時不需要回表查詢,直接通過索引就可以獲取查詢的數據; using temporary:表示使用了臨時表存儲中間結果; using where: 5.6之前:存儲引擎只能根據限制條件掃描數據並返回,然後再回表進行過濾返回真正的查詢的數據; 5.6之後:支持ICP特性,把條件限制都下推到存儲引擎層來完成,這樣就能降低不必要的IO訪問。 filtered:explain各欄位的意思
最左首碼匹配
創建索引如下:
mysql> create index index1 on t1(name,email,type); Query OK, 0 rows affected (17.45 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc t1; +-------+-----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(20) | YES | MUL | NULL | | | email | char(100) | YES | | NULL | | | type | int(11) | YES | | NULL | | | dep | int(11) | YES | | NULL | | +-------+-----------+------+-----+---------+----------------+ 5 rows in set (0.00 sec)
那麼最左首碼匹配是什麼意思呢?
這裡創建了一個名為index1的索引,包含三列,從左至右為:name,email,type,最左首碼匹配的意思就是,查詢的時候條件必須包含name列才會使用索引去查找,否則就會全文去查詢。
舉例:
mysql> explain select * from t1 where name='test8888' and email='[email protected]' and type=1; +----+-------------+-------+------------+------+---------------+--------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | index1 | index1 | 367 | const,const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+--------+---------+-------------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> mysql> explain select * from t1 where name='test8888' and email='[email protected]'; +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | index1 | index1 | 362 | const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t1 where name='test8888' and type=1; +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | ref | index1 | index1 | 61 | const | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t1 where name='test8888'; +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | index1 | index1 | 61 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t1 where email='[email protected]' and type=1; --當不包含name的時候,就不會使用索引查找 +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 990448 | 1.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t1 where email='[email protected]'; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 990448 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t1 where email='[email protected]' and name='test8888'; --name不必在條件語句的最左邊 +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | index1 | index1 | 362 | const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+--------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)最左首碼匹配例子 這裡引出一個小概念: 組合索引和索引合併
組合索引:比如之前例子中create index index1 on t1(name,email,type),index1就是一個組合索引; 索引合併:索引合併,拿上一個例子來看,創建了一個索引包含了3個列,這個叫組合索引,如果我們針對每一個列創建一個索引,在使用查詢語句的時候使用多個索引,即把多個單列索引合併使用,這就叫索引的合併。
那麼它們的效率如何呢?
如果在查詢語句經常使用的是多個列一起查詢,建議使用組合索引,如果經常只查單個列,建議使用索引合併這種形式,針對單個列創建索引。
還有一個名稱是覆蓋索引,意思是在索引文件中直接獲取數據。
正確的命中索引
資料庫中添加了索引的確會使查詢的速度提高,但是也要避免以下情況,即使建立了索引也不會生效,如上面介紹到的不使用最左匹配也是一種:
like '%xx':以%開頭的LIKE查詢不能夠使用索引; 使用函數:比如select * from tb1 where reverse(name) = 'test8888'; or:當or條件中有未建立索引的列才失效; 類型不一致:如果列是字元串類型,傳入條件是必須用引號引起來; !=:使用不等於的時候,特殊情況:如果是主鍵還是會走索引; 範圍查詢:如果是主鍵或者索引是整數類型,則還是會走索引; order by:當根據索引排序的時候,選擇的映射如果不是索引,則不走索引,特殊情況,如果對主鍵排序,則還是走索引; 最左首碼匹配。可能不會命中索引的情況
其他還需要註意的:
避免使用select * count(1)或count(列) 代替 count(*) 創建表時儘量時 char 代替 varchar 表的欄位順序固定長度的欄位優先 組合索引代替多個單列索引(經常使用多個條件查詢時) 儘量使用短索引 使用連接(JOIN)來代替子查詢(Sub-Queries) 連表時註意條件類型需一致 索引散列值(重覆少)不適合建索引,例:性別不適合避免事項
show status命令
show status可以瞭解各種SQL的執行頻率。
下麵的命令顯示當前session中所有的統計參數的值:
mysql> show status like 'com_%'; --如果想查看全局的,可以在status前面加上global +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | Com_admin_commands | 0 | | Com_assign_to_keycache | 0 | | Com_alter_db | 0 | | Com_alter_db_upgrade | 0 | | Com_alter_event | 0 | | Com_alter_function | 0 | | Com_alter_instance | 0 | | Com_alter_procedure | 0 | | Com_alter_server | 0 | | Com_alter_table | 5 | | Com_alter_tablespace | 0 | | Com_alter_user | 0 | | Com_analyze | 0 | | Com_begin | 0 | | Com_binlog | 0 | | Com_call_procedure | 0 | | Com_change_db | 1 | | Com_change_master | 0 | | Com_change_repl_filter | 0 | | Com_check | 0 |


