
原創文章,轉載請註明出處:http://www.cnblogs.com/weix-l/p/7521278.html; 若有錯誤,請評論指出,謝謝! 1. 聚合函數(Aggregate Function) MySQL(5.7 ) 官方文檔中給出的聚合函數列表(圖片)如下: 詳情點擊https://de ...
原創文章,轉載請註明出處:http://www.cnblogs.com/weix-l/p/7521278.html;
若有錯誤,請評論指出,謝謝!
1. 聚合函數(Aggregate Function)
MySQL(5.7 ) 官方文檔中給出的聚合函數列表(圖片)如下:
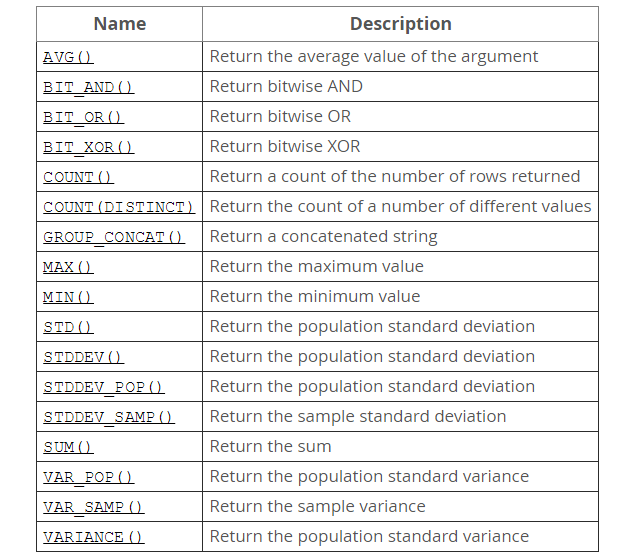
詳情點擊https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html 。
除非另有說明,否則聚合函數都會忽略空值(NULL values)。
2. 聚合函數的使用
聚合函數通常對 GROUP BY 語句進行分組後的每個分組起作用,即,如果在查詢語句中不使用 GROUP BY 對結果集分組,則聚合函數就對結果集的所有行起作用。為說明聚合函數的使用,現創建測試表 member 進行測試,member 的數據結構如下(使用 SELECT * FROM member 查詢所得):
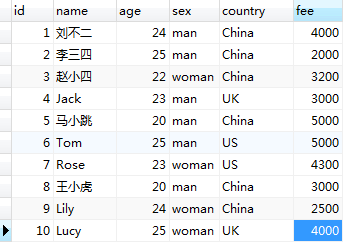
1)對結果集直接使用聚合函數
例如,使用聚合函數SUM () 計算所有會員(member) 的會費總和,則可使用:
SELECT SUM(fee) AS total_fee FROM member #計算所有會員會費總和
查詢結果為:
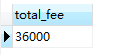
SUM 函數會對全部欄位列 fee 進行求和。當然,也可以求平均值、最大值等。
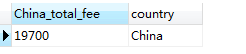
此外,也可以使用 WHERE 語句進行限定條件的聚合查詢。例如,如果要查詢 country 為 China 的會員會費之和,則為:
SELECT SUM(fee) AS China_total_fee, country FROM member WHERE country = 'China'
結果顯示如下:
2)GROUP BY 對結果集分組後使用聚合函數——組內聚合
- GROUP BY 如何分組?
——將欄位值相同的記錄歸為一組,可用COUNT(*) 統計組內成員個數;
- “組內聚合”為何意?
——以分組為單位,對組內每個成員使用聚合函數進行統計,即聚合函數是關於分組成員的函數。
試想,如果要從測試表中查詢每個國家的會費總和呢?每個國家的會費,即先將所有結果集按 country 欄位進行分組,country 值相同的行歸為一組,然後以組為單位進行求和,這樣查詢的結果記錄數等於分組欄位不同值的個數。總共有來自三個國家(China, US, UK)的會員,所以分組聚合查詢的結果記錄數為3:
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country #查詢每個國家的會費之和
該查詢語句會計算每個國家的會費之和,然後展示按每個國家分組的查詢結果:
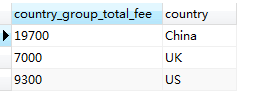
標準SQL( standard SQL) 和 MySQL 都提供 HAVING 語句對使用 GROUP BY 分組之後的結果進行條件篩選並產生新的結果集。例如,對於前述 1)中查詢中國會員會費總和的問題,可以使用HAVING 語句:
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country HAVING country = 'China' #使用HAVING語句查詢中國會員會費總和
結果和上面一樣:
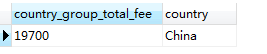
這種方法與前述 1)中直接使用WHERE進行限定相比有些畫蛇添足,為什麼呢?因為 country 在此是分組欄位(group column),對分組欄位使用 HAVING 再次進行限定則就顯得分組毫無意義,因為這時完全可以通過使用 WHERE 進行篩選後直接求和實現。那麼,能使用非聚合列(nonaggregated column) 為限定條件嗎?答案是,不僅沒有意義,而且不允許。非聚合列指的是沒有用聚合函數而是要查詢的表本身的欄位,因為使用 GROUP BY 分組查詢後的聚合結果列中根本就不包含非聚合欄位列,所以在解析SQL語句時根本找不到這個欄位。比如,當你想獲取每個國家性別為 man 的會員的會費之和時可能嘗試在上面這個語句中使用 HAVING 對 sex 進行限定,像下麵這樣:
SELECT SUM(fee) AS country_group_total_fee FROM member m GROUP BY country HAVING m.sex = 'man' #錯誤:嘗試使用HAVING 語句對非聚合欄位進行限定
執行後會報錯 Err 1054:
[Err] 1054 - Unknown column 'm.sex' in 'having clause',提示未知的列m.sex,即使此處使用別名進行說明也不行。那麼如何實現查詢每個國家性別為 man 的會員的會費之和呢?當然還是使用WHERE 語句在 GROUP BY 進行分組之前就進行限定:
SELECT SUM(fee) AS country_group_total_fee, country FROM member WHERE sex = 'man' GROUP BY country #在分組之前使用 WHERE 進行條件篩選
產生下麵結果:
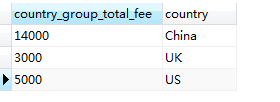
所以,HAVING 不能對分組本身起作用,但可以對分組後的結果進行查詢限定,而限定的條件只能為聚合列(aggregated column),聚合列指的是在 SELECT 列 (SELECT list)中使用聚合函數產生的列,例如,此處的SUM(fee) 就是聚合列。在HAVING 中對聚合列進行限定,可以獲取滿足一定條件的聚合列結果。例如,在上面獲取每個國家會員費用之和後再限定查詢哪些會員費用之和超過10000,則可以使用下麵的SQL 語句:
SELECT SUM(fee) country FROM member GROUP BY country HAVING SUM(fee) > 10000 #查詢會員費總和超過10000 的國家
其結果就只剩下中國了:)
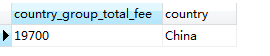
這是在標準SQL語句中的語法。在MySQL中擴展了HAVING 的用法,使其可以接受聚合列的別名作為限定條件,例如上面的要求使用別名的查詢語句為:
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country HAVING country_group_total_fee > 10000 #在HAVING 中使用別名
其結果仍為:

3)GROUP BY 按多個分組欄位分組後使用聚合函數——細分組內聚合
如果使用一個分組欄位分組後的聚合結果記錄數等於該分組欄位不同值的個數,那麼,使用多個分組欄位以後呢?例如,在上面的查詢的基礎上,如果想要查詢每個國家男、女分別的會費總和時,可以使用下麵的語句:
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex FROM member GROUP BY country,sex #查詢每個國家男、女會員的總和會費
結果如下:
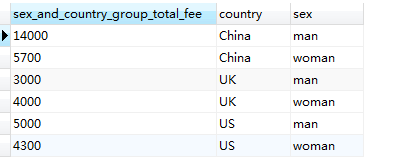
從上面的結果可以看出來,“中國的男性會員出的總會費最多,而英國的男性會員的總會費最少”。總共三個國家,如果只按國家(country) 進行分組,只有三條記錄,如果再按性別 (sex) 分,則會在分組後的每個組(也即每一行、每一條記錄)里按性別的不同再進行細分,因為性別值只有兩種,所以每個國家的分組又被分成兩小組,則三個國家總共就有6小組(6 = 3 × 2),這樣最終也就會有6條記錄,如上圖示。
為瞭解每個細分小組的個數,在SELECT 查詢列的最後加上計算分組個數的聚合函數 COUNT(*):
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex, COUNT(*) AS row_num FROM member GROUP BY country, sex #多分組欄位分組,並統計每組個數
結果如下:
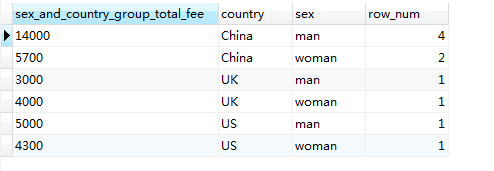
上面的結果預設按靠近GROUP BY 的順序進行排序,但如果要指定排序一句,則可使用ORDER BY ,例如,對上面的結果按 sex 排序:
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex, count(*) AS row_num FROM member GROUP BY country, sex ORDER BY sex #將分組結果按sex 排序
結果如下:
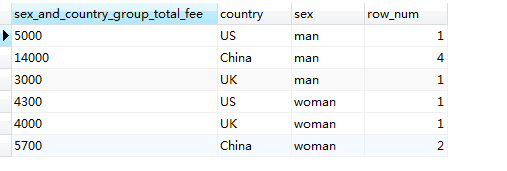
如果用其他欄位對結果再進行細分呢?原理與上述兩個欄位進行分組時一樣的,知識分組的深度越多,很明顯結果的記錄行數也越多,但不管怎樣,你會發現每一條分組後的結果都是不一樣的,這正是分組結果的特征,因為ORDER BY 本身就具有聚合功能,每個聚合列的結果是通過分組歸類的結果,所以只有一條記錄。
那麼,如果用表的 主鍵 或 非空唯一性欄位 進行分組,結果會怎樣呢?比如,在本測試表中,id 是其主鍵,name 是非空的具有唯一性約束的欄位,下麵分別是以 id 和 name 進行分組的MySQL 語句和結果:
SELECT SUM(fee) AS sex_and_country_group_total_fee, id, COUNT(*) AS row_num FROM member GROUP BY id #以主鍵id進行分組
結果如下:
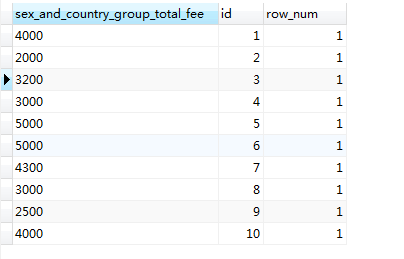
SELECT SUM(fee) AS sex_and_country_group_total_fee, name, COUNT(*) AS row_num FROM member GROUP BY name #以非空唯一性約束欄位進行分組
結果如下:
很顯然,這兩種分組的結果中聚合函數結果列是一樣的,每組的結果記錄行數也一樣,而且都為1,這說明按主鍵或非空唯一性約束欄位進行分組其結果相同,且結果就是表的全部每一行記錄。這樣做可能沒有太大意義,但有助於理解 GROUP BY 分組的原理。
3. 總結
1) 可直接對某個欄位使用聚合函數,也可用 WHERE 語句篩選後對某個欄位使用聚合函數;
2) 聚合函數通常作用於使用 GROUP BY 分組後的分組成員,用於統計每個分組的數據;
3) 不能對沒有使用 GROUP BY 分組的聚合函數使用 HAVING 進行限定;
4) 可對使用 GROUP BY 分組查詢後的結果使用 HAVING 進行限定,其限定條件最好為聚合函數列(本身或其他聚合函數);
5) 可在使用 GROUP BY 分組前使用 WHERE 對結果進行篩選,在分組後使用 HAVING 對聚合函數列進行限定;
6) 可使用 ORDER BY 對結果按照某個欄位(任意欄位或列,使用 GROUP BY 分組時也可使用聚合函數列)進行排序;
7) 當按照主鍵或非空唯一性約束欄位進行分組時,其結果為整個表的全部記錄。
4. 參考文獻
[1]. MySQL 官方文檔 URL: https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html

