1.hadoop2.x 概述 hadoop2中NameNode可以有多個(目前只支持2個)。每一個都有相同的職能。一個是active狀態的,一個是standby狀態的。當集群運行時,只有active狀態的NameNode是正常工作的,standby狀態的NameNode是處於待命狀態的,時刻同步ac ...
1.hadoop2.x 概述
hadoop2中NameNode可以有多個(目前只支持2個)。每一個都有相同的職能。一個是active狀態的,一個是standby狀態的。當集群運行時,只有active狀態的NameNode是正常工作的,standby狀態的NameNode是處於待命狀態的,時刻同步active狀態NameNode的數據。一旦active狀態的NameNode不能工作,standby狀態的NameNode就可以轉變為active狀態的,就可以繼續工作了。
2個NameNode的數據其實是實時共用的。新HDFS採用了一種共用機制,Quorum Journal Node(JournalNode)集群或者Network File System(NFS)進行共用。NFS是操作系統層面的,JournalNode是hadoop層面的,我們這裡使用JournalNode集群進行數據共用(這也是主流的做法)。JournalNode的架構圖如下:
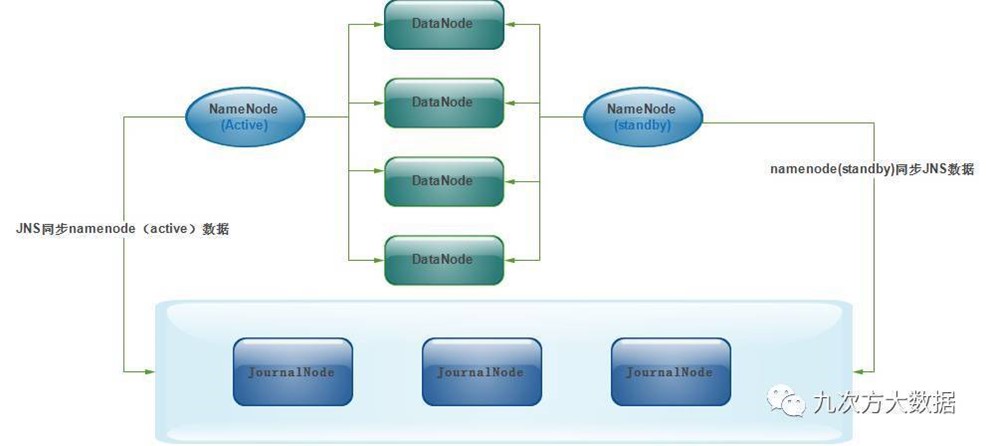
兩個NameNode為了數據同步,會通過一組稱作JournalNodes的獨立進程進行相互通信。當active狀態的NameNode的命名空間有任何修改時,會告知大部分的JournalNodes進程。standby狀態的NameNode有能力讀取JNs中的變更信息,並且一直監控edit log的變化,把變化應用於自己的命名空間。standby可以確保在集群出錯時,命名空間狀態已經完全同步了。
對於HA集群而言,確保同一時刻只有一個NameNode處於active狀態是至關重要的。否則,兩個NameNode的數據狀態就會產生分歧,可能丟失數據,或者產生錯誤的結果。為了保證這點,這就需要利用使用ZooKeeper了。首先HDFS集群中的兩個NameNode都在ZooKeeper中註冊,當active狀態的NameNode出故障時,ZooKeeper能檢測到這種情況,它就會自動把standby狀態的NameNode切換為active狀態。來自 <http://www.jianshu.com/p/a1d3028f3e27>
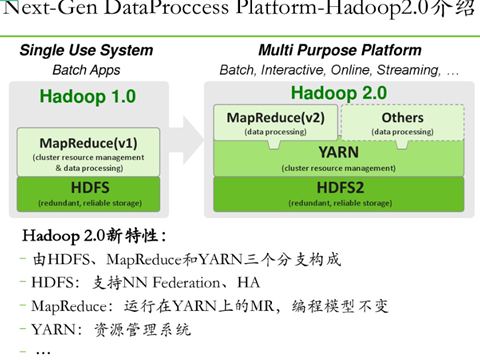

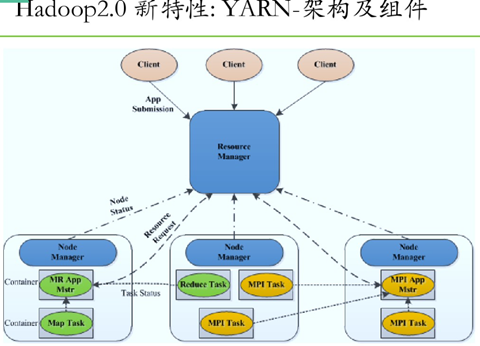
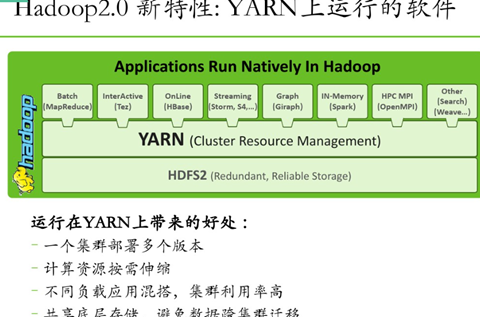
Hadoop安裝分為三種方式,分別為單機、偽分散式、完全分散式,安裝過程不難,在此主要詳細敘述完全分散式的安裝配置過程,畢竟生產環境都使用的完全分散式,前兩者作為學習和研究使用。按照下述步驟一步一步配置一定可以正確的安裝Hadoop分散式集群環境。
2、搭建
2.1 網路環境
|
No. |
Host Name |
IP Address |
Node Type |
User Name |
|
1 |
Maser |
192.168.1.106 |
Name Node |
hadoop/root |
|
2 |
Slave1 |
192.168.1.107 |
Data Node |
hadoop/root |
|
3 |
Slave2 |
192.168.1.108 |
Data Node |
hadoop/root |
2.2、軟硬體環境
Centos7.3
Java-1.8.0-openjdk
Hadoop 2.8.1
2.3、環境搭建
All nodes are disabled SELinux and firewalld
All nodes can ping with each other
All nodes have same hadoop directory structure and a same user account
Create a hadoop user, home directory is /home/hadoop, add into root group.
hadoop directory is /usr/local/hadoop, directory owner is hadoop
Master node and slave node can SSH with no password publick key authentication
All nodes have same /etc/hosts, add master node and slave node record line
SSH採用了公鑰加密。過程如下:
(1)遠程主機收到用戶的登錄請求,把自己的公鑰發給用戶。
(2)用戶使用這個公鑰,將登錄密碼加密後,發送回來。
(3)遠程主機用自己的私鑰,解密登錄密碼,如果密碼正確,就同意用戶登錄。
3、安裝配置java
3.1、安裝Java
安裝JDK以及配置環境變數,需要以"root"的身份進行
# yum search jdk
# yum -y install java-1.8.0-openjdk*
3.2、配置java環境
新建配置文件etc/profile/java.sh
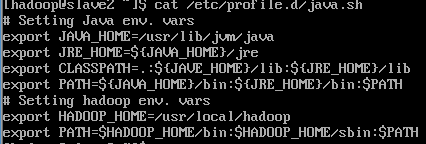
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
3.3、驗證
# java -version
# javac -version

4、 安裝配置hadoop
4.1 安裝
# cd /usr/local/src
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.1/hadoop-2.8.1.tar.gz
# tar -vxzf hadoop-2.8.1
# mv hadoop-2.8.1 ../hadoop
# chown -R hadoop:hadoop hadoop
4.2 配置 hadoop 環境
/etc/profile.d/java
4.3.2 創建hadoop子目錄
# cd /usr/local/hadoop
# mkdir tmp hdfs
# cd hdfs
# mkdir name tmp data
4.3 hadoop 配置文件
進入到$HADOOP_HOME/etc/hadoop目錄修改配置文件,配置項可參考文檔http://hadoop.apache.org/docs/r2.8.0/
4.3.1 hadoop-env.sh
驗證
4.3.2 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<final>true</final>
<!--(備註:請先在 /usr/hadoop 目錄下建立 tmp 文件夾) -->
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<!-- hdfs://Master.Hadoop:22-->
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
4.3.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.3.4 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.3.5 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master.Hadoop:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master.Hadoop:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master.Hadoop:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master.Hadoop:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master.Hadoop:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.3.6 /usr/local/hadoop/etc/hadoop/masters 文件
/usr/local/hadoop/etc/hadoop/slaves
4.4 Slave node 上java/hadoop安裝與配置
4.4.1 java/openjdk安裝同master node
在master node上
scp /etc/profile.d/java.sh slave1:/etc/profile.d
scp /etc/profile.d/java.sh slave2:/etc/profile.d
4.4.2 Hadoop安裝
在master node上
scp -r /usr/local/hadoop slave1:/usr/local
scp -r /usr/local/hadoop slave1:/usr/local
4.4.3 改變許可權
chown -R hadoop:hadoop /usr/lib/jvm/java-1.8.0-openjdk-*
chown -R hadoop:hadoop /usr/local/hadoop
5、測試、驗證
5.1
$ hadoop namenode -format
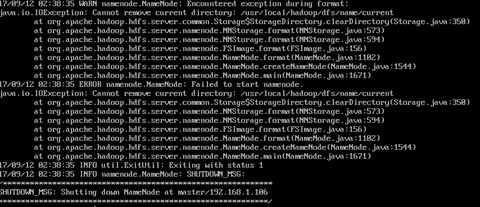
$ start-all .sh
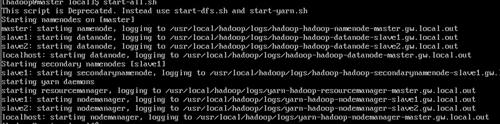
$ ps -ef |grep hadoop

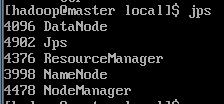
$ jps
master (master)

slave1 (Secondary master)

slave2
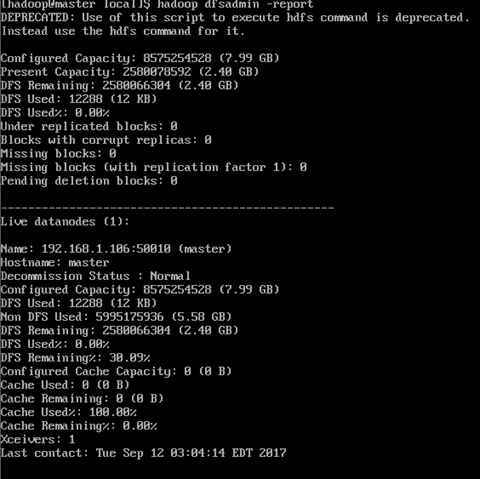
5.2 通過網頁查看集群
在本地訪問HDFS WebUI: http://8088:50070
YARN WebUI: http://master:8088
5.3 向hadoop集群系統提交第一個mapreduce任務(wordcount)
5.3.1 cd /home/hadoop
$ cat >>test.txt<<EOF
Hello World
Hello World
Hello World
Hello World
5.3.2 進入本地hadoop目錄(/usr/local/hadoop)
$ hdfs dfs -mkdir -p /data/input在虛擬分散式文件系統上創建一個測試目錄/data/input
$ hdfs dfs -put test.txt /data/input 將當前目錄下的README.txt 文件複製到虛擬分散式文件系統中
$ hdfs dfs-ls /data/input 查看文件系統中是否存在我們所複製的文件

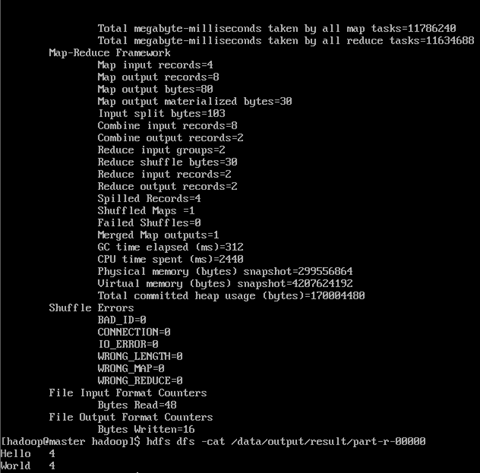
5.3.3 運行如下命令向hadoop提交單詞統計任務
進入jar文件目錄,執行下麵的指令。
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar \
wordcount \
/data/input /data/output/result
查看result,結果在result下麵的part-r-00000中