
為什麼這樣的 JSON會解析失敗? 為什麼界面上韓文顯示亂碼? ASCII和ANSI有什麼區別? 帶著這些問題查看了網上的很多資料,整理出了下麵的文章。本文只是從程式員的角度說一說自己對字元編碼的理解,所以有點地方淺嘗輒止,說的並不深入。 1. ASCII及其擴展 1.1 什麼是ASCII字元集 字 ...
為什麼這樣的
{"data":"颸颸"}JSON會解析失敗?
為什麼界面上韓文顯示亂碼?
ASCII和ANSI有什麼區別?
帶著這些問題查看了網上的很多資料,整理出了下麵的文章。本文只是從程式員的角度說一說自己對字元編碼的理解,所以有點地方淺嘗輒止,說的並不深入。
1. ASCII及其擴展
1.1 什麼是ASCII字元集
字元集就是一系列用於顯示的字元的集合。ASCII字元集由美國國家標準協會(American National Standard Institute)於1968年制定一個字元映射集合。
ASCII使用7位二進位位來表示一個字元,總共可以表示128個字元(即2^7,二進位000 0000 ~ 111 1111 十進位0~127)。
ASCII字元集中每個數字對應一個唯一的字元,如下表:
| ASCII值 | 控制字元 | ASCII值 | 控制字 | ASCII值 | 控制字 | ASCII值 | 控制字 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
因為其對應關係非常簡單,不需要特殊的編碼規則,所以嚴格來講ASCII不能算字元編碼,因為它沒有規定編碼規則。我們只是習慣將ASCII字元集稱之為ASCII碼、ASCII編碼。
1.2 ASCII的擴展
1.2.1 最高位擴展 - ISO/IEC 8859
ASCII字元集是美國人發明的,這些字元完全是為其量身定製的。但隨著電腦技術的發展和普及,傳到了歐洲(如法國、德國)各國。由於歐洲很多國家中使用的字元除了ASCII表中的128個字元之外,還有一些各國特有的字元,於是歐洲人民發現ASCII字元集表達不了他們所要表達的東西呀。怎麼辦了?他們發現ASCII只使用了一個位元組(8位)之中的低7位,於是歐洲各國開始各顯神通,打起了那1個最高位(第0位)的主意,將最高位利用了起來,這樣又多了128個字元,從而滿足了歐洲人民的需要。
但因為每個國家的需求不一樣,各國都設計了不同的方案。為了結束這種混亂的局面,國際標準化組織(ISO)及國際電工委員會(IEC)聯合制定了一系列8位字元集的標準,統稱為ISO 8859(全稱ISO/IEC 8859)。註意,這是一系列字元集的統稱。如ISO/IEC 8859-1(也就是常聽到的Latin-1)支持西歐語言,ISO/IEC 8859-4(Latin-4)支持北歐語言等。
完整列表如下(摘自百度百科):
ISO/IEC 8859-1 (Latin-1) - 西歐語言
ISO/IEC 8859-2 (Latin-2) - 中歐語言
ISO/IEC 8859-3 (Latin-3) - 南歐語言,世界語也可用此字元集顯示。
ISO/IEC 8859-4 (Latin-4) - 北歐語言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫語言
ISO/IEC 8859-6 (Arabic) - 阿拉伯語
ISO/IEC 8859-7 (Greek) - 希臘語
ISO/IEC 8859-8 (Hebrew) - 希伯來語(視覺順序)
ISO 8859-8-I - 希伯來語(邏輯順序)
ISO/IEC 8859-9 (Latin-5 或 Turkish) - 它把Latin-1的冰島語字母換走,加入土耳其語字母。
ISO/IEC 8859-10 (Latin-6 或 Nordic) - 北日耳曼語支,用來代替Latin-4。
ISO/IEC 8859-11 (Thai) - 泰語,從泰國的 TIS620 標準字集演化而來。
ISO/IEC 8859-13 (Latin-7 或 Baltic Rim) - 波羅的語族
ISO/IEC 8859-14 (Latin-8 或 Celtic) - 凱爾特語族
ISO/IEC 8859-15 (Latin-9) - 西歐語言,加入Latin-1欠缺的芬蘭語字母和大寫法語重音字母,以及歐元符號。
ISO/IEC 8859-16 (Latin-10) - 東南歐語言。主要供羅馬尼亞語使用,並加入歐元符號。
我們在資料庫中常見到的Latin-1、2、5、7其實就是上面提到的針對特定語言的ASCII擴展字元集。
1.2.2 多位元組擴展 - GB系列
前面講到了,歐洲各國有效利用閑置的最高位,對ASCII字元集進行了擴展。可是歐洲人民沒有想到的是(當然他們也不用想這麼多),在大洋彼岸有著一個擁有五千年曆史的偉大民族,她擁有著成千上萬的漢字,1個位元組顯然不夠表達如此深厚的文化底蘊。
於是當電腦引入到中國之初,國家技術監督局就設計了GB系列編碼方案(GB=guo biao)。
GB編碼方案使用2個位元組來表達一個漢字。同時為了相容ASCII編碼,規定各個位元組的最高位(首位)必須為1,從而避免了和最高位為0的ASCII字元集的衝突。
GB系列字元集經歷下麵的幾個發展過程:
GB2312
GB13000
GBK
GB18030
每一次迭代,支持的字元數量都會增加,而且每一次迭代都會保留之前版本支持的編碼,所以做到了向上相容。
1.2.3 全形與半形
因為漢字在顯示器上的顯示寬度要比英文字元的寬度要寬一倍,在一起排版顯示時不太美觀。所以GB編碼不僅僅加入了漢字字元,而且包括了ASCII字元集中本來就有的數字、標點符號、字母等字元。這些被編入GB編碼的數字、標點、字母在顯示器上的顯示寬度比ASCII字元集中的寬度寬一倍,所以前者稱為全形字元,後者稱為半形字元。
2. ANSI
2.1 ANSI與代碼頁
前面說到了世界各國針對ASCII的擴展方案(如歐洲的ISO/IEC 8859,中國的GB系列等),這些ASCII擴展編碼方案的特點是:他們都相容ASCII編碼,但他們彼此之間是不相容的。微軟將這些編碼方案統稱為ANSI編碼。故ANSI並不是特指某一種編碼方案,只有知道了在哪個國家,哪個語言環境下,它表示具體的編碼方案。
在windows操作系統上,預設使用ANSI來保存文件。那麼操作系統是如何知道ANSI到底應該表示哪種編碼了,是GBK,還是ASCII,或者還是EUC-KR了? windows通過一個叫"Code Page"(翻譯為中文就叫代碼頁)的東西來判斷系統的預設編碼。
可以使用命令chcp來查看系統預設的代碼頁:
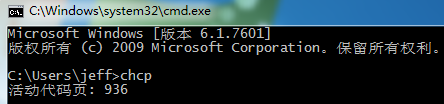
簡體中文操作系統預設的代碼頁是936,它表示ANSI使用的是GBK編碼。
2.2 更改預設代碼頁
2.2.1 chcp命令
可以使用chcp命令來更改預設代碼頁,如chcp 437 將預設代碼頁更改為437(美國)。
2.2.2 控制面板
在“控制面板”-->“區域和語言”--> “更改系統區域設置”中更改系統預設的代碼頁。
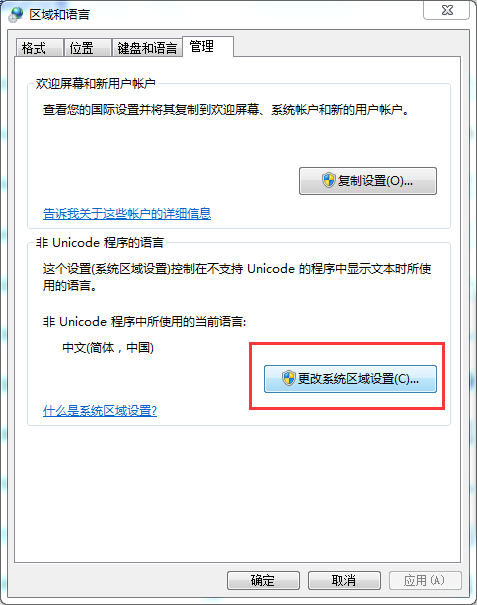
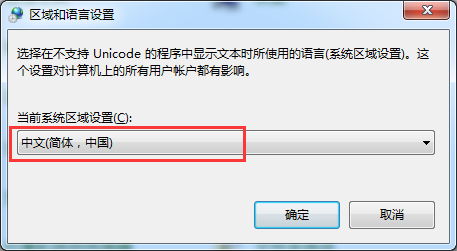
2.2.3 代碼修改
也可以通過代碼更改預設的代碼頁:
char *setlocale(
int category,
const char *locale
);3. Unicode
3.1 Unicode產生背景
各個國家使用不同的編碼規則,雖然他們都是相容ASCII的,但它們相互卻是不相容的。
試想法國人Jack寫了一封名為"love_you.txt"的信,傳給了他的德國朋友Rose,Rose想要在windows系統上打開這個文件,她需要知道德國使用的字元編碼是Latin-1,然後還要確保她的電腦上安裝了該編碼,才能順利的打開這個文件。
如果上面這些還能忍受,那麼隨著網路的發展,你從互聯網上獲取的文件,你很有可能不知道它來自哪個國家,使用的哪種編碼。這也就是Email剛誕生時常常出現亂碼的原因,發信人和收信人使用的編碼可能是不一樣的。
於是The Unicode Standard(統一碼標準)橫空出世,它由The Unicode Consortium於1991年發佈,我們習慣稱它為Unicode字元集。Unicode字元集只是一個字元集合,它不包含任何編碼規則和方案。Unicode字元集的目標是涵蓋人類使用的所有字元,併為每個字元分配唯一的字元編號。
3.2 字元集與字元編碼的區別
從ASCII、GB2312、GBK、GB18030、Big5(繁體中文)、Latin-1等採用的方案來看,它們都只是定義了單個字元與二進位數據的映射關係,一個字元在一個方案中只會存在一種表示方式,所以我們說GB2312是字元集還是字元編碼方式都無所謂了。但是Unicode不一樣,Unicode作為一個字元集可以採用多種編碼方式,如UTF-8, UTF-16, UTF-32等。所以自Unicode出現之後,字元集與字元編碼需要明確區分開來。
3.3 UTF-16編碼的缺點
Unicode字元集的字元編碼方式一開始規定用兩個位元組(即16位)來統一表示所有的字元,即UTF-16編碼。對於ASCII字元保持不變,只是將原來的7位擴展到了16位,其高9位永遠是0。如字元'A':
ASCII: 100 0001
UTF-16: 0000 0000 0100 0001可以看到對於ASCII字元,UTF-16的存儲空間擴大了一倍,UTF-16並不是完全相容ASCII字元集。這對於那些ASCII字元集已經滿足需求的西方國家來說完全是沒必要的,而且ASCII字元經過UTF-16編碼之後高位元組始終是0,導致很多C語言函數(如strcpy,strlen)會將此位元組視為字元串的結束符'\0',從而出現錯誤的計算結果。
因此,UTF-16一開始推出的時候就遭到很多西方國家的抵制,影響了Unicode的推行。於是後來又設計了UTF-8編碼方式,才解決了這些問題。
3.4. Unicode字元集常用編碼方式:UTF-8
UTF-8編碼的最小單位由8位(1個位元組)組成,UTF-8使用一個至四個位元組來表示Unicode字元。
UTF-8是完美相容ASCII字元集的。對於0~127(0x00~0x7F)的ASCII字元直接存儲為1個位元組(最高位同樣為0)。因為UTF-8需要使用多個位元組來表示一個Unicode字元,所以UTF-8的編碼規則還保證0~127(0x00~0x7F)不會出現在UTF-8編碼的任何非ASCII字元的任何一個位元組中。
通俗的說,就是在採用UTF-8編碼的串中,看到了0~127(0x00~0x7F)的字元,不要懷疑,那就是ASCII字元。


