
緩存資料庫介紹 NoSQL(Not Only SQL),即"不僅僅是SQL",泛指非關係型的資料庫。隨著互聯網web2.0網站的興起,傳統的關係資料庫在應對web2.0網站,特別是超大規模和高併發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以剋服的問題,而非關係型的資料庫則由於... ...
緩存資料庫介紹
NoSQL(Not Only SQL),即"不僅僅是SQL",泛指非關係型的資料庫。隨著互聯網web2.0網站的興起,傳統的關係資料庫在應對web2.0網站,特別是超大規模和高併發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以剋服的問題,而非關係型的資料庫則由於其本身的特點得到了非常迅速的發展。NoSQL資料庫的產生就是為瞭解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題。
NoSQL資料庫的四大分類
有四大NoSQL類型:鍵值存儲(key-value store)、文件存儲(document store)、列導向的資料庫(Column-Oriented Database)和圖形資料庫(graph database)。每種類型都解決了傳統關係資料庫無法解決的問題。實際的實現往往是這些組合的組合。例如結合NoSQL類型,Orientdb是一個多模式的資料庫。Orientdb是圖形資料庫,每個節點都是一個文檔。
鍵值(key-value)存儲資料庫
這一類資料庫主要會使用到一個哈希表,這個表中有一個特定的鍵和一個指針指向特定的數據。Key/Value模型對於IT系統來說的優勢在於簡單、易部署。但是如果DBA只對部分值進行查詢或更新的時候,Key/Value就顯得效率低下了。代表資料庫Tokyo Cabinet/Tyrant、Redis、Voldemort、Oracle BDB。
列存儲資料庫
這部分資料庫通常是用來應對分散式存儲的海量數據。鍵任然存在,但是它們的特點是指向了多個列。這些列是由列家族來安排的。代表資料庫Cassandra、HBase、Riak。
文檔型資料庫
文檔型資料庫的靈感來自於Lotus Notes辦公軟體,而且它同第一種鍵值存儲類似。該類型的數據模型是版本化的文檔,半結構化的文檔以特定的格式存儲,比如JSON。文檔型資料庫可以看作是鍵值資料庫的升級版,允許之間嵌套鍵值。而且文檔型資料庫比鍵值資料庫的查詢效率更高。代表資料庫CouchDB、MongoDB,國內SequoiaDB。
圖形(Graph)資料庫
圖形結構的資料庫同其他行列以及剛性結構的SQL資料庫不同,它是使用靈活的圖形模型,並且能夠擴展到多台伺服器上。NoSQL資料庫沒有標準的查詢語言(SQL),因此進行資料庫查詢需要制定數據模型。許多NoSQL資料庫都有REST式的數據介面或者查詢API。代表資料庫Neo4J、InfoGrid、Infinite Graph。
因此NoSQL資料庫在以下幾種情況比較適用:1、數據模型比較簡單;2、需要靈活性更強的IT系統;3、對資料庫性能要求較高;4、不需要高度的數據一致性;5、對於給定key比較容易映射複雜值的環境。
NoSQL資料庫的四大分類對比
分類 | 代表資料庫 | 典型應用場景 | 數據模型 | 優點 | 缺點 |
鍵值(key-value) | Tokyo Cabinet/Tyrant、Redis、Voldemort、Oracle BDB | 內容緩存,主要用於處理大量數據的高訪問負載,也用於一些日子系統。 | key指向value的鍵值對,通常用hash table來實現。 | 查找速度快 | 數據無結構化,通常只被當作字元串或者二級制數據。 |
列存儲資料庫 | Cassandra、HBase、Riak | 分散式的文件系統 | 以列簇式存儲,將同一列數據存在一起 | 查找速度快,可擴展性強,更容易進行分散式擴展 | 功能相對局限性 |
文檔型資料庫 | CouchDB、MongoDB | web應用(與key-value類似,value是結構化的,不同的是資料庫能夠瞭解value的內容) | key-value對應的鍵值對,value為結構化數據 | 數據結構要求不嚴格,表結構可變,不需要像關係資料庫一樣需要預先定義表結構 | 查詢性能不高,而且缺乏統一的查詢語法 |
圖形(Graph)資料庫 | Neo4J、InfoGrid、Infinite Graph | 社交網路、推薦系統等。專註於構建關係圖譜 | 圖結構 | 利用圖結構相關演算法。比如最短路徑定址,N度關係查找等。 | 很多時候需要對整個圖做計算才能得出需要的信息,而且這種結構不太好做分散式的集群方案。 |
Redis
介紹
redis是業界主流的key-value nosql資料庫之一。與Memcached類似,它支持存儲的value類型相對更多,包括string(字元串)、list(鏈表)、set(集合)、zset(sorted set有序集合)和hash(哈希類型)。這些數據類型都支持push/pop、add/remove及取交集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支持各種不同方式的排序。與memcached一樣,為了保證效率,數據都是緩存在記憶體中。區別是redis會周期性的把更新的數據寫入磁碟或者把修改操作寫入追加的記錄文件,並且在此基礎上實現了master-slave(主從)同步。
Redis優點
異常快速:Redis是非常快的,每秒可以執行大約110000設置操作,81000個/秒的讀取操作。
支持豐富的數據類型:Redis支持最大多數開發人員已經知道數據類型,如列表、集合、可排序集合、哈希等。這使得在應用中很容易解決各種問題,因為我們知道哪些問題處理使用哪些數據類型更好解決。
操作都是原子的:所有Redis的操作都是原子,從而確保當兩個客戶同時訪問Redis伺服器得到的是更新後的值(最新值)。
MultiUtility工具:Redis是一個多功能實用工具,可以在緩存、消息傳遞隊列中使用(Redis原生支持發佈/訂閱),在應用程式中web應用程式會話,網站網頁點擊數等任何短暫的數據。
Redis缺點
持久化:Redis直接將數據存儲到記憶體中,要將數據保存到磁碟上,Redis可以使用兩種方式實現持久化過程。定時快照(snapshot),每隔一段時間將整個資料庫寫到磁碟上,每次均是寫全部數據,代價非常高。基於語句追加(aof),只追蹤變化的數據,但是追加的log可能過大,同時所有的操作均重新執行一遍,回覆速度慢。
占用記憶體過高。
修改配置文件,進行重啟,將硬碟中的數據載入進記憶體,時間比較久。這個過程中redis不能提供服務。
Redis不具備自動容錯和恢復功能,主機從機的宕機都會導致前端部分讀寫請求失敗,需要等待機器重啟或者手動切換前端的IP才能恢復。
主機宕機,宕機前有部分數據未能及時同步到從機,切換IP後還會引入數據不一致的問題,降低了系統的可用性。
Redis較難支持線上擴容,在集群容量達到上限時線上擴容會變得很複雜。為了避免這一問題,運維人員在系統上線時必須確保有足夠的空間,這對資源造成了很大的浪費。
安裝Redis環境
redis官網:https://redis.io/
下載源碼,解壓後編譯源碼
- wget http://download.redis.io/releases/redis-3.0.6.tar.gz
- tar xzf redis-3.0.6.tar.gz
- cd redis-3.0.6
- make
編譯完成後,進入redis-3.0.6目錄。將redis.conf中的daemonize配置為yes(以守護進程方式運行)。
進入src目錄啟動redis,指定配置文件位置,並後臺運行。
- redis-server /root/redis-3.0.6/redis.conf &
查看是否啟動
- lsof -i:6379
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- redis-ser 1612 root 4u IPv6 13114 0t0 TCP *:6379 (LISTEN)
- redis-ser 1612 root 5u IPv4 13116 0t0 TCP *:6379 (LISTEN)
運行redis客戶端redis-cli。
- redis-cli
- 127.0.0.1:6379> ping
- PONG
- 127.0.0.1:6379>
至這說明已經成功安裝了redis。
Redis API使用
連接方式
操作模式
Redis-py提供兩個類Redis和StrictRedis用於實現Redis的命令,StrictRedis用於實現大部分官方的命令,並使用官方的語法和命令,Redis是StrictRedis的子類,用於向後相容舊版本的redis-py。
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redis
- # 連接池
- pool = redis.ConnectionPool(host='192.168.31.128',port=6379)
- r = redis.Redis(connection_pool=pool)
- r.set('foo','golden')
- print(r.get('foo'))
連接池
redis-py使用connection pool來管理對一個redis server的所有連接,避免每次建立、釋放連接的開銷。預設每個Redis實例都會維護一個自己的連接池。可以直接建立一個連接池,然後作為參數Redis,這樣就可以實現多個Redis實例共用一個連接池。
基本操作
String操作
Redis中的String在記憶體中按照一個name對應一個value來存儲。
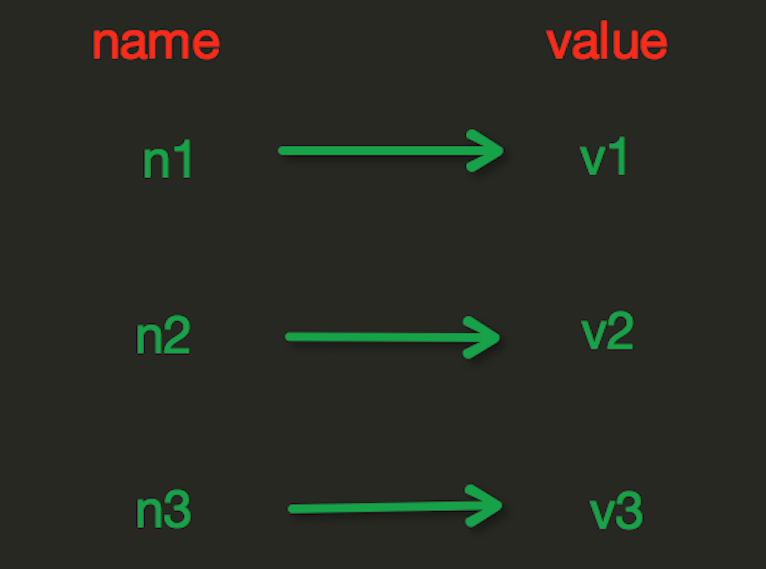
set(name,value,ex=None,px=None,nx=False,xx=False)
在Redis中設置值,預設不存在則創建,存在則修改。
ex過期時間(秒);px過期時間(毫秒);nx如果設置為True,則只有name不存在時,當前set操作才執行;xx如果設置為True,則只有name存在時,當前set操作才執行。
setnx(name,value)
設置值,只有name不存在時,執行設置操作(添加)。
psetex(name,time_ms,value)
time_ms過期時間(毫秒)
mset(*args,**kwargs)
批量設置值mset(k1='v1',k2='v2')或mget({'k1':'v1','k2':'v2'})。
get(name)
獲取值。
mget(keys,*args)
批量獲取值,mget('name1','name2')或r.mget(['name1','name2']。
getset(name,value)
設置新增並獲取原來的值。
getrange(key,start,end)
獲取子序列(根據位元組獲取,非字元)。一個漢字3個位元組。
setrange(name,offset,value)
修改字元串內容,從指定字元串索引開始向後替換(新值太長時,則向後添加)。
setbit(name,offset,value)
對name對應值的二進位表示的位進行操作。offset位的索引將值變換成二進位後再進行索引,value值只能是1或0。例如setbit('name',6,1)表示將字元串name用二進位表示後,將第六位設置為1。
getbit(name,offset)
獲取name對應的值的二進位表示中的某位的值。
bitcount(key,start=None,end=None)
獲取name對應的值的二進位表示中1的個數。
strlen(name)
獲取name對應值的位元組長度(一個漢字3個位元組)。
incr(self,name,amount=1)
自增name對應的值,當name不存在時,則創建name=amount,否則就自增,自增數必須是整數。
incrbyfloat(self,name,amount=1.0)
自增name對應的值,當name不存在時,則創建name=amount,否則就自增,自增數浮點型。
decr(self,name,amount=1)
自減name對應的值,當name不存在時,則創建name=amount,否則就自減,自減數整數。
append(key,value)
在key對應的值後面追加內容value。
Hash操作
Hash表現形式上有些像python中的dict,可以存儲一組關聯性較強的數據,redis中的Hash在記憶體中的存儲格式如下圖。
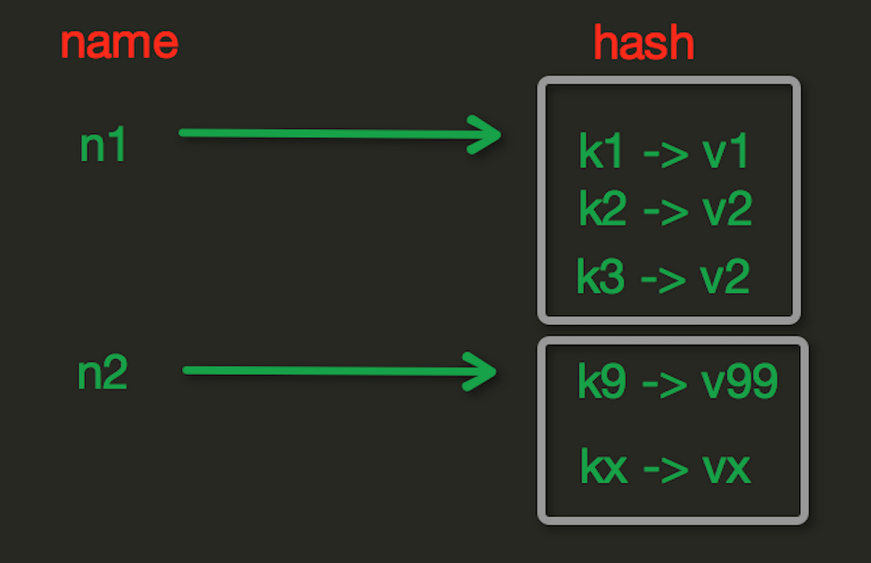
hset(name,key,value)
name對應的hash中設置一個鍵值對,不存在則創建,否則修改。
hmset(name,mapping)
在name對應的hash中批量設置鍵值對。
hgetall(name)
獲取name對應hash的所有鍵值。
hlen(name)
獲取name對應的hash中鍵值對的個數。
hkeys(name)
獲取name對應的hash中所有的key值。
hvals(name)
獲取name對應的hash中所有的value值。
hexists(name,key)
檢查name對應的hash是否存在當前傳入的key。
hdel(name,*keys)
將name對應的hash中指定key的鍵值對刪除。
hincrby(name,key,amount=1)
自增name對應的hash中的指定key的值,不存在則創建key=amount。amount自增數(整數)。
hincrbyfloat(name,key,amount=1.0)
自增name對應的hash中的指定key的值,不存在則創建key=amount。amount自增數(浮點數)。
hscan_iter(name,match=None,count=None)
利用yield封裝hscan創建生成器,實現分批去redis中獲取數據。
List
Redis中的List在記憶體中安裝一個name對應一個List來存儲。如下圖所示。
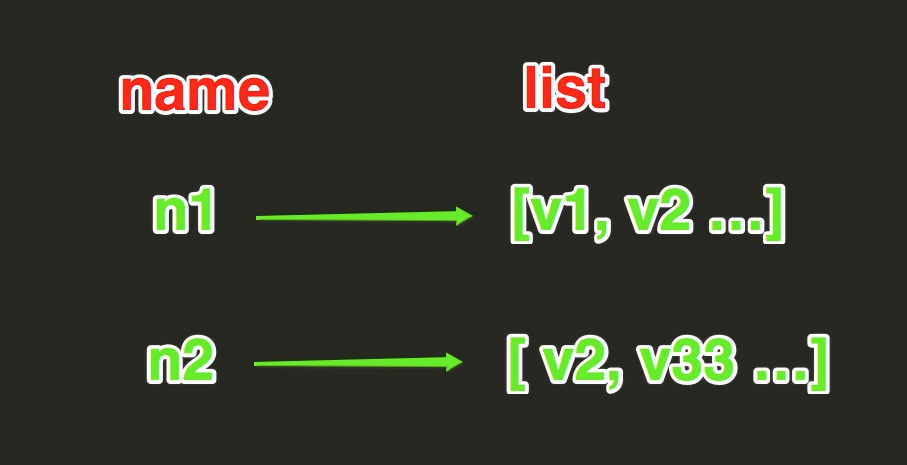
lpush(name,values)
在name對應的list中添加元素,每個新的元素都添加到列表的最左邊。如r.lpush('test',11,22,33),保持順序為33,22,11。rpush(name,values)表示從右向左操作。
lpushx(name,value)
在name對應的list中添加元素,只有name已經存在時,值添加到列表的最左邊。rpushx(name,value)表示從右向左操作。
llen(name)
name對應的list元素的個數。
linsert(name,where,refvalue,value)
在name對應的列表的某一個值前或後插入一個新值。where:BEFORE或AFTER;refvalue:標桿值,即在它前後插入數據;value:要插入的數據。
r.lset(name,index,value)
對name對應的list中的某一個索引位置重新賦值。index:list的索引位置。
r.lrem(name,num,value)
在name對應的list中刪除指定的值。value:要刪除的值;num>0:從表頭開始向表尾搜索,移除與value相等的元素,刪除數量為num個;num<0:從表尾開始向表頭搜索,移除與value相等的元素,刪除數量為num個;num=0:移除表中所有與value相等的值。
lpop(name)
在name對應的列表的左側獲取第一個元素併在列表中移除,返回第一個元素。
lindex(name,index)
在name對應的列表中根據索引獲取列表元素。
lrange(name,start,end)
在name對應的列表分片獲取數據。
ltrim(name,start,end)
在name對應的列表中移除沒有在start-end索引之間的值。
rpoplpush(src,dst)
從一個列表取出最右邊的元素,同時將其添加至另一個列表的最左邊。src:要取數據的列表的name;dst:要添加數據的列表的name。
blpop(keys,timeout)
將多個列表排列,按照從左到右去pop對應列表的元素。timeout:超時時間,當元素所有列表的元素獲取完之後,阻塞等待列表內有數據的時間(秒),0表示永遠阻塞。
brpoplpush(src,dst,timeout=0)
從一個列表的右側移除一個元素並將其添加到另一個列表的左側。
set
Redis的set是string類型的無序集合。集合成員是唯一的,這就意味著集合中不能出現重覆的數據。
sadd(name,values)
name對應的集合中添加元素。
scard(name)
獲取name對應的集合中元素個數。
sdiff(keys,*args)
在第一個name對應的集合中且不在其他name對應的集合元素的集合。
sdiffstore(dest,keys,*args)
獲取第一個name對應的集合中且不在其他name對應的集合元素,再將其新加入到dest對應的集合中。
sinter(keys,*args)
獲取多個name對應集合的並集。
sinterstore(dest,keys,*args)
獲取多個name對應集合的並集,再將其加入到dest對應的集合中。
sismember(name,value)
檢查value是否是name對應的集合的成員。
smembers(name)
獲取name對應的集合的所有成員。
smove(src,dst,value)
將某個成員從一個集合中移動到另一個集合。
spop(name)
從集合的右側(尾部)移除一個成員,並將其返回。
srandmember(name,numbers)
從name對應的集合中隨機獲取numbers個元素。
srem(name,values)
在name對應的集合中刪除某些值。
sunion(keys,*args)
獲取多個name對應的集合的並集。
sunionstore(dest,keys,*args)
獲取多個name對應的集合的並集,並將結果保存到dest對應的集合中。
有序集合,在集合的基礎上為每個元素排序,元素的排序需要根據另一個值來進行比較,所以,對於有序集合每一個元素有兩個值,即值和分數,分數用來做排序。
zadd(name,*args,**kwargs)
在name對應的有序集合中添加元素。
zcard(name)
獲取name對應的有序集合元素的數量。
zcount(name,min,max)
獲取name對應的有序集合中分數在min和max之間的個數。
zincrby(name,value,amount)
對指定成員的分數加上增量value。
r.zrange(name,start,end,desc=False,score_cast_func=float)
按照索引範圍獲取name對應的有序集合的元素。
start:有序集合索引起始位置(非分數)。
end:有序集合索引結束位置(非分數)。
desc:排序規則,預設按照分數從小到大排序。
withscores:是否獲取元素的分數,預設只獲取元素的值。
score_cast_func:對分數進行數據轉換的函數。
zrevrange(name,start,end,withscores=False,score_cast_func=float)
從大到小排序。
zrangebyscore(name,min,max,start=None,num=None,withscores=False,score_cast_func=float)
按照分數範圍獲取name對應的有序集合的元素。
zrevrangebyscore(name,max,min,start=None,num=None,withscores=False,score_cast_func=float)
從大到小排序。
zrank(name,value)
獲取某個值在name對應的有序集合中的排行
zrevrank(name,value)
從大到小排序。
zrem(name,values)
刪除name對應的有序集合中值是values的成員。
zremrangebyrank(name,min,max)
根據排行範圍刪除。
zremrangebyscore(name,min,max)
根據分數範圍刪除。
zscore(name,value)
獲取name對應有序集合中value對應的分數。
zinterstore(dest,keys,aggregate=None)
獲取兩個有序集合的交集,如果遇到相同值不同分數則按照aggregate進行操作,aggregate的值為SUM、MIN、MAX。
其他操作
delete(*names)
根據name刪除redis中的任意數據類型。
exists(name)
檢測redis的name是否存在。
keys(pattern='*')
根據key匹配獲取redis的name。
expire(name,time)
為某個redis的某個name設置超時時間。
rename(src,dst)
對redis的name重命名。
move(name,db)
將redis的某個值移動到指定的db下。
randomkey()
隨機獲取一個redis的name(不刪除)。
type(name)
獲取name對應值的類型。
管道
redis-py預設在執行每次請求都會創建(連接池申請連接)和斷開(歸還連接池)一次連接操作。如果想要在一次請求中指定多個命令,則可以使用pipline實現一次請求指定多個命令,並且預設情況下一次pipline是原子性操作。(原子性操作是指不會被線程調度機制打斷的操作,這種操作一旦開始就一直運行到結束,中間不會有任何context switch(切換到另一個線程))
發佈訂閱
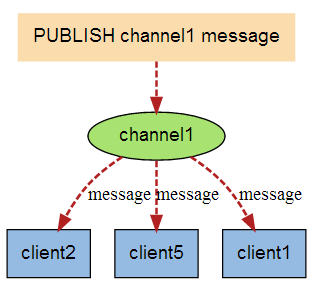
Redis發佈訂閱(pub/sub)是一種消息通信模式,發送者(pub)發送消息,訂閱者(sub)接收消息。Redis客戶端可以訂閱任意數量的頻道。下圖展示了頻道channel1,以及訂閱這個頻道的三個客戶端client1、client2和client5之間的關係。
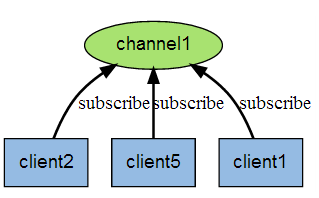
當有新消息通過publish命令發送給頻道channel1時,這個消息就會被髮送給訂閱它的三個客戶端。
RedisHelper_basic
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redis
- class RedisHelper(object):
- """
- RedisHelper
- """
- def __init__(self):
- self.__conn = redis.Redis(host='192.168.31.128')
- self.chan_sub = 'channel1'
- self.chan_pub = 'channel1'
- def public(self,msg):
- self.__conn.publish(self.chan_pub,msg)
- return True
- def subscribe(self):
- pub = self.__conn.pubsub()
- pub.subscribe(self.chan_sub)
- pub.parse_response()
- return pub
發佈者
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redisHelper_basic
- obj = redisHelper_basic.RedisHelper()
- obj.public('hello')
訂閱者
- __author__ = 'Golden'
- #!/usr/bin/env python3
- # -*- coding:utf-8 -*-
- import redisHelper_basic
- obj = redisHelper_basic.RedisHelper()
- redis_sub = obj.subscribe()
- while True:
- msg = redis_sub.parse_response()
- print(msg)
結果
- [b'message', b'channel1', b'hello']


