
前言 最近一直忙於和小伙伴倒騰著關於人工智慧的比賽,一直都沒有時間停下來更新更新我的博客。不過在這一個過程中,遇到了一些問題,我還是記錄了下來,等到現在比較空閑了,於是一一整理出來寫成博客。希望對於大家有幫助,如果在此有不對的地方,請大家指正,謝謝! 比賽遇到spark開啟的問題 疑惑之處 在使用百 ...
前言
最近一直忙於和小伙伴倒騰著關於人工智慧的比賽,一直都沒有時間停下來更新更新我的博客。不過在這一個過程中,遇到了一些問題,我還是記錄了下來,等到現在比較空閑了,於是一一整理出來寫成博客。希望對於大家有幫助,如果在此有不對的地方,請大家指正,謝謝!
比賽遇到spark開啟的問題
疑惑之處
在使用百度BMR的時候,出現了這樣子一個比較困惑的地方。但百度那邊幫我們初始化了集群之後,我們預設以為開啟了spark集群了,於是就想也不想就開始跑我們的代碼。可認真你就錯了,發現它只是開啟了local(即Master結點),其他的slaves結點並沒有開啟。於是我們不得不每一次都進入到Master的/opt/bmr/spark/conf/中去修改slaves文件,去把它裡面最後的那個localhost刪除,添加上slaves結點的hostname或者是IP。
原來的localhost:

改變成如下:

麻煩之處
最是麻煩的地方是,這個slaves文件,每次使用spark集群的時候都要去修改,非常不方便。在此吐槽一下百度BMR的不智能的地方。於是想,有木有好的辦法可以讓我們省去這樣的麻煩呢?
使用腳本開啟百度BMR的spark集群
觀察Hadoop文件夾下的情況
在開啟集群的時候,百度提供我們選擇Hadoop的鏡像版本,而這個Hadoop是必選的。前幾篇博文里見到配置Hadoop的時候其實需要配置其他slaves的結點的。知道這個,就有點驚喜了,因為Hadoop下的slaves文件是長這樣子的
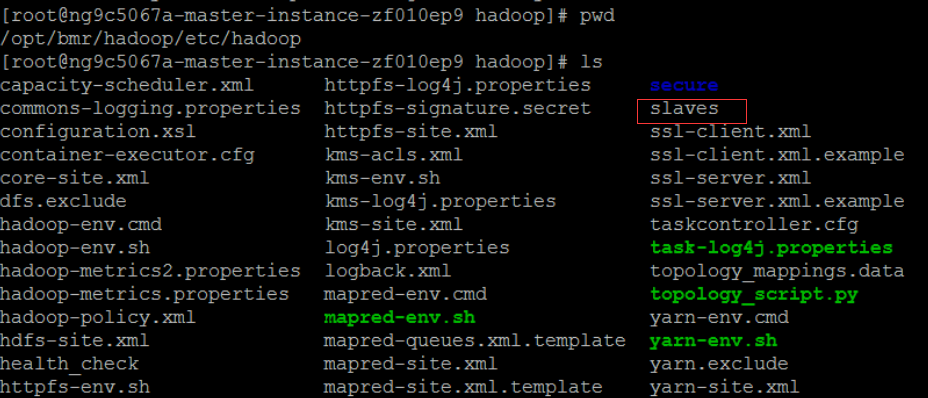

觀察spark文件夾下的情況
spark下的conf文件夾,一開始並沒有slaves,我們需要從它的slaves.template拷貝過來
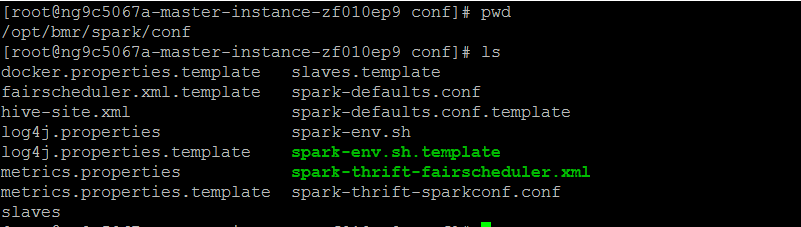
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
使用腳本,拷貝slaves的hostname到spark下的slaves
我們需要做的是,獲取Hadoop下slaves的slaves結點的hostname,進而拷貝到spark下的slaves文件的最後兩行,拷貝之前,需要把spark的slaves的最後一行localhost給刪除掉。那麼有哪個shell指令可以幫我解決這個難題了?經過詢問後臺的大佬,以及晚上查閱,發現了sed這個指令可以幫助我們解決這個問題。
sed的介紹
取自http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856901.html
[root@www ~]# sed [-nefr] [動作]
選項與參數:
-n :使用安靜(silent)模式。在一般 sed 的用法中,所有來自 STDIN 的數據一般都會被列出到終端上。但如果加上 -n 參數後,則只有經過sed 特殊處理的那一行(或者動作)才會被列出來。
-e :直接在命令列模式上進行 sed 的動作編輯;
-f :直接將 sed 的動作寫在一個文件內, -f filename 則可以運行 filename 內的 sed 動作;
-r :sed 的動作支持的是延伸型正規表示法的語法。(預設是基礎正規表示法語法)
-i :直接修改讀取的文件內容,而不是輸出到終端。
動作說明: [n1[,n2]]function
n1, n2 :不見得會存在,一般代表『選擇進行動作的行數』,舉例來說,如果我的動作是需要在 10 到 20 行之間進行的,則『 10,20[動作行為] 』
function:
a :新增, a 的後面可以接字串,而這些字串會在新的一行出現(目前的下一行)~
c :取代, c 的後面可以接字串,這些字串可以取代 n1,n2 之間的行!
d :刪除,因為是刪除啊,所以 d 後面通常不接任何咚咚;
i :插入, i 的後面可以接字串,而這些字串會在新的一行出現(目前的上一行);
p :列印,亦即將某個選擇的數據印出。通常 p 會與參數 sed -n 一起運行~
s :取代,可以直接進行取代的工作哩!通常這個 s 的動作可以搭配正規表示法!例如 1,20s/old/new/g 就是啦!使用sed寫腳本
具體用到的有:
-i #因為信息我覺得不用輸出到終端上
d #需要刪除localhost這是刪除localhost的:
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves追加slaves的hostname到spark的slaves最後
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done最後spark下的slaves文件是這樣子的

完整的代碼如下
echo "Starting dfs!"
/opt/bmr/hadoop/sbin/start-dfs.sh
echo "*******************************************************************"
echo "Starting copy!"
cp /opt/bmr/spark/conf/slaves.template /opt/bmr/spark/conf/slaves
echo "Copy finished!"
echo "Writing!"
sed -i '/localhost/d' /opt/bmr/spark/conf/slaves
for slaves_home in `cat /opt/bmr/hadoop/etc/hadoop/slaves`
do
echo $slaves_home >> /opt/bmr/spark/conf/slaves
done
echo "*******************************************************************"
echo "Starting spark!"
/opt/bmr/spark/sbin/start-all.sh
echo "*******************************************************************"
echo "Watching the threads"
jps查看到Master進程已經開啟了,就大功告成了!
結言
只要把上面的代碼保存到一個.shell文件下。給它加上可運行的許可權,然後就大功告成了。理論上,百度BMR的spark的路徑都是一致的,因而都能通用,希望能減輕大家每次配置的煩惱。
文章出自kwongtai'blog,轉載請標明出處!

