
如果說大數據中分散式收集日誌用的是什麼,你完全可以回答Flume!(面試小心問到哦) 首先說一個複製本伺服器文件到目標伺服器上,需要目標伺服器的ip和密碼: 命令: scp filename ip:目標路徑 一 概述 Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚 ...
如果說大數據中分散式收集日誌用的是什麼,你完全可以回答Flume!(面試小心問到哦)
首先說一個複製本伺服器文件到目標伺服器上,需要目標伺服器的ip和密碼:
命令: scp filename ip:目標路徑
一 概述
Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統,Flume支持在日誌系統中定製各類數據發送方,用於收集數據;同時,Flume提供對數據進行簡單處理,並寫到各種數據接受方(可定製)的能力。
Flume提供對數據進行簡單處理,並寫到各種數據接受方(可定製)的能力 Flume提供了從console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日誌系統,支持TCP和UDP等2種模式),exec(命令執行)等數據源上收集數據的能力。
當前Flume有兩個版本Flume 0.9X版本的統稱Flume-og,Flume1.X版本的統稱Flume-ng。由於Flume-ng經過重大重構,與Flume-og有很大不同,使用時請註意區分。
Flume-og採用了多Master的方式。為了保證配置數據的一致性,Flume引入了ZooKeeper,用於保存配置數據,ZooKeeper本身可保證配置數據的一致性和高可用,另外,在配置數據發生變化時,ZooKeeper可以通知Flume Master節點。Flume Master間使用gossip協議同步數據。
Flume-ng最明顯的改動就是取消了集中管理配置的 Master 和 Zookeeper,變為一個純粹的傳輸工具。Flume-ng另一個主要的不同點是讀入數據和寫出數據現在由不同的工作線程處理(稱為 Runner)。 在 Flume-og 中,讀入線程同樣做寫出工作(除了故障重試)。如果寫出慢的話(不是完全失敗),它將阻塞 Flume 接收數據的能力。這種非同步的設計使讀入線程可以順暢的工作而無需關註下游的任何問題。
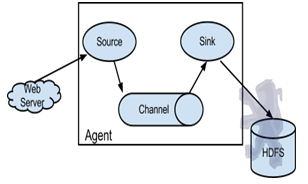
Flume以agent為最小的獨立運行單位。一個agent就是一個JVM。單agent由Source、Sink和Channel三大組件構成。
二 啟動Flume集群
1‘ 首先,啟動Hadoop集群(詳情見前博客)。
2’ 其次,(剩下的所有步驟只需要在master上操作就可以了)安裝並配置Flume任務,內容如下:
將Flume 安裝包解壓到/usr/cstor目錄,並將flume目錄所屬用戶改成root:root。
tar -zxvf flume-1.5.2.tar.gz -c /usr/cstor
chown -R root:root /usr/cstor/flume
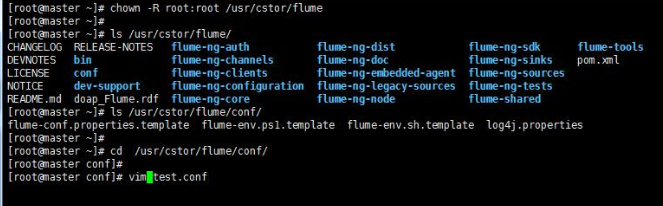
3‘ 進入解壓目錄下,在conf目錄下新建test.conf文件並添加以下配置內容:
1 #定義agent中各組件名稱 2 agent1.sources=source1 3 agent1.sinks=sink1 4 agent1.channels=channel1 5 # source1組件的配置參數 6 agent1.sources.source1.type=exec 7 #此處的文件/home/source.log需要手動生成,見後續說明 8 agent1.sources.source1.command=tail -n +0 -F /home/source.log 9 # channel1的配置參數 10 agent1.channels.channel1.type=memory 11 agent1.channels.channel1.capacity=1000 12 agent1.channels.channel1.transactionCapactiy=100 13 # sink1的配置參數 14 agent1.sinks.sink1.type=hdfs 15 agent1.sinks.sink1.hdfs.path=hdfs://master:8020/flume/data 16 agent1.sinks.sink1.hdfs.fileType=DataStream 17 #時間類型 18 agent1.sinks.sink1.hdfs.useLocalTimeStamp=true 19 agent1.sinks.sink1.hdfs.writeFormat=TEXT 20 #文件首碼 21 agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d-%H-%M 22 #60秒滾動生成一個文件 23 agent1.sinks.sink1.hdfs.rollInterval=60 24 #HDFS塊副本數 25 agent1.sinks.sink1.hdfs.minBlockReplicas=1 26 #不根據文件大小滾動文件 27 agent1.sinks.sink1.hdfs.rollSize=0 28 #不根據消息條數滾動文件 29 agent1.sinks.sink1.hdfs.rollCount=0 30 #不根據多長時間未收到消息滾動文件 31 agent1.sinks.sink1.hdfs.idleTimeout=0 32 # 將source和sink 綁定到channel 33 agent1.sources.source1.channels=channel1 34 agent1.sinks.sink1.channel=channel1
4' 然後,在HDFS上創建/flume/data目錄:
cd /usr/cstor/hadoop/bin
./hdfs dfs -mkdir /flume
./hdfs dfs -mkdir /flume/data
5' 最後,進入Flume安裝的bin目錄下
cd /usr/cstor/flume/bin
6' 啟動Flume,開始收集日誌信息。
./flume-ng agent --conf conf --conf-file /usr/cstor/flume/conf/test.conf --name agent1 -Dflume.root.logger=DEBUG,console
!!!>>運行此命令有時候會出現一個許可權問題,此時需要用命令 chmod o+x flume-ng
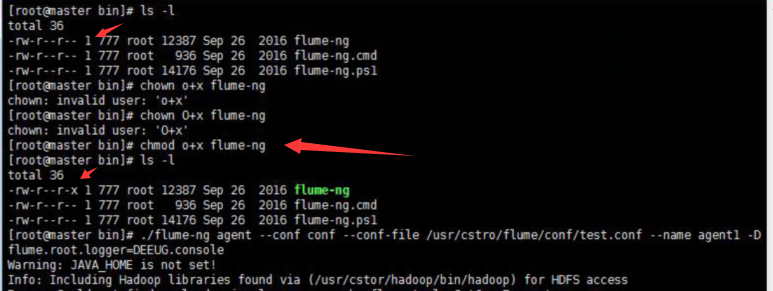
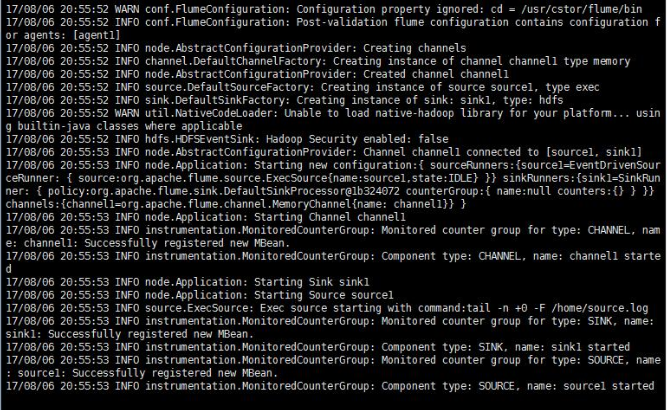
如果正常運行,最後悔顯示 started,如圖:
三 收集日誌
1’ 啟動成功之後需要手動生成消息源即配置文件中的/home/source.log,使用如下命令去不斷的寫入文字到/home/source.log中:

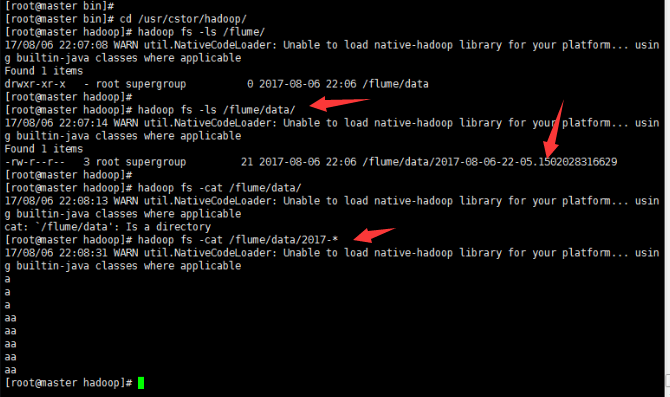
2' 到此就可以去查看生成結果:
小結:
這隻是配置Flume,然後簡單的讀寫日誌。想要深入下去,還要收集更複雜,更龐大的日誌。


