
目錄 · 概況 · 原理 · API · DStream · WordCount示例 · Input DStream · Transformation Operation · Output Operation · 緩存與持久化 · Checkpoint · 性能調優 · 降低批次處理時間 · 設置合 ...
目錄
· 概況
· 原理
· API
· DStream
· 緩存與持久化
· 性能調優
· 降低批次處理時間
· 記憶體調優
概況
1. Spark Streaming支持實時數據流的可擴展(scalable)、高吞吐(high-throughput)、容錯(fault-tolerant)的流處理(stream processing)。
2. 架構圖

3. 特性
a) 可線性伸縮至超過數百個節點;
b) 實現亞秒級延遲處理;
c) 可與Spark批處理和互動式處理無縫集成;
d) 提供簡單的API實現複雜演算法;
e) 更多的流方式支持,包括Kafka、Flume、Kinesis、Twitter、ZeroMQ等。
原理
Spark在接收到實時輸入數據流後,將數據劃分成批次(divides the data into batches),然後轉給Spark Engine處理,按批次生成最後的結果流(generate the final stream of results in batches)。

API
DStream
1. DStream(Discretized Stream,離散流)是Spark Stream提供的高級抽象連續數據流。
2. 組成:一個DStream可看作一個RDDs序列。
3. 核心思想:將計算作為一系列較小時間間隔的、狀態無關的、確定批次的任務,每個時間間隔內接收的輸入數據被可靠存儲在集群中,作為一個輸入數據集。
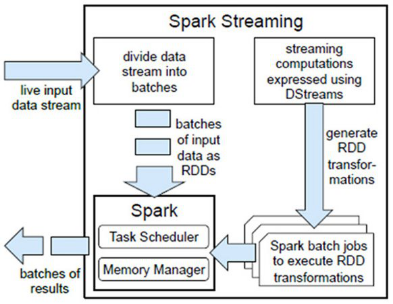
4. 特性:一個高層次的函數式編程API、強一致性以及高校的故障恢復。
5. 應用程式模板
a) 模板1
1 import org.apache.spark.SparkConf 2 import org.apache.spark.SparkContext 3 import org.apache.spark.streaming.Seconds 4 import org.apache.spark.streaming.StreamingContext 5 6 object Test { 7 def main(args: Array[String]): Unit = { 8 val conf = new SparkConf().setAppName("Test") 9 val sc = new SparkContext(conf) 10 val ssc = new StreamingContext(sc, Seconds(1)) 11 12 // ... 13 } 14 }
b) 模板2
1 import org.apache.spark.SparkConf 2 import org.apache.spark.streaming.Seconds 3 import org.apache.spark.streaming.StreamingContext 4 5 object Test { 6 def main(args: Array[String]): Unit = { 7 val conf = new SparkConf().setAppName("Test") 8 val ssc = new StreamingContext(conf, Seconds(1)) 9 10 // ... 11 } 12 }
WordCount示例
1 import org.apache.spark.SparkConf 2 import org.apache.spark.storage.StorageLevel 3 import org.apache.spark.streaming.Seconds 4 import org.apache.spark.streaming.StreamingContext 5 import org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctions 6 7 object Test { 8 def main(args: Array[String]): Unit = { 9 val conf = new SparkConf().setAppName("Test") 10 val ssc = new StreamingContext(conf, Seconds(1)) 11 12 val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER) 13 val wordCounts = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) 14 wordCounts.print 15 16 ssc.start 17 ssc.awaitTermination 18 } 19 }
Input DStream
1. Input DStream是一種從流式數據源獲取原始數據流的DStream,分為基本輸入源(文件系統、Socket、Akka Actor、自定義數據源)和高級輸入源(Kafka、Flume等)。
2. Receiver
a) 每個Input DStream(文件流除外)都會對應一個單一的Receiver對象,負責從數據源接收數據並存入Spark記憶體進行處理。應用程式中可創建多個Input DStream並行接收多個數據流。
b) 每個Receiver是一個長期運行在Worker或者Executor上的Task,所以會占用該應用程式的一個核(core)。如果分配給Spark Streaming應用程式的核數小於或等於Input DStream個數(即Receiver個數),則只能接收數據,卻沒有能力全部處理(文件流除外,因為無需Receiver)。
3. Spark Streaming已封裝各種數據源,需要時參考官方文檔。
Transformation Operation
1. 常用Transformation
|
名稱 |
說明 |
|
map(func) |
Return a new DStream by passing each element of the source DStream through a function func. |
|
flatMap(func) |
Similar to map, but each input item can be mapped to 0 or more output items. |
|
filter(func) |
Return a new DStream by selecting only the records of the source DStream on which func returns true. |
|
repartition(numPartitions) |
Changes the level of parallelism in this DStream by creating more or fewer partitions. |
|
union(otherStream) |
Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
|
count() |
Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
|
reduce(func) |
Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. |
|
countByValue() |
When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
|
reduceByKey(func, [numTasks]) |
When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
|
join(otherStream, [numTasks]) |
When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
|
cogroup(otherStream, [numTasks]) |
When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
|
transform(func) |
Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
|
updateStateByKey(func) |
Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
2. updateStateByKey(func)
a) updateStateByKey可對DStream中的數據按key做reduce,然後對各批次數據累加。
b) WordCount的updateStateByKey版本
1 import org.apache.spark.SparkConf 2 import org.apache.spark.storage.StorageLevel 3 import org.apache.spark.streaming.Seconds 4 import org.apache.spark.streaming.StreamingContext 5 import org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctions 6 7 object Test { 8 def main(args: Array[String]): Unit = { 9 val conf = new SparkConf().setAppName("Test") 10 val ssc = new StreamingContext(conf, Seconds(1)) 11 12 // updateStateByKey前需設置checkpoint 13 ssc.checkpoint("/spark/checkpoint") 14 15 val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER) 16 val addFunc = (currValues: Seq[Int], prevValueState: Option[Int]) => { 17 // 當前批次單詞的總數 18 val currCount = currValues.sum 19 // 已累加的值 20 val prevCount = prevValueState.getOrElse(0) 21 // 返回累加後的結果,是一個Option[Int]類型 22 Some(currCount + prevCount) 23 } 24 val wordCounts = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey[Int](addFunc) 25 wordCounts.print 26 27 ssc.start 28 ssc.awaitTermination 29 } 30 }
3. transform(func)
a) 通過對原DStream的每個RDD應用轉換函數,創建一個新的DStream。
b) 官方文檔代碼舉例
1 val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information 2 3 val cleanedDStream = wordCounts.transform(rdd => { 4 rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning 5 ... 6 })
4. Window operations
a) 視窗操作:基於window對數據transformation(個人認為與Storm的tick相似,但功能更強大)。
b) 參數:視窗長度(window length)和滑動時間間隔(slide interval)必須是源DStream批次間隔的倍數。
c) 舉例說明:視窗長度為3,滑動時間間隔為2;上一行是原始DStream,下一行是視窗化的DStream。

d) 常見window operation
|
名稱 |
說明 |
|
window(windowLength, slideInterval) |
Return a new DStream which is computed based on windowed batches of the source DStream. |
|
countByWindow(windowLength, slideInterval) |
Return a sliding window count of elements in the stream. |
|
reduceByWindow(func, windowLength, slideInterval) |
Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative so that it can be computed correctly in parallel. |
|
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) |
When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
|
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) |
A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
|
countByValueAndWindow(windowLength, slideInterval, [numTasks]) |
When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
e) 官方文檔代碼舉例
1 // window operations前需設置checkpoint 2 ssc.checkpoint("/spark/checkpoint") 3 4 // Reduce last 30 seconds of data, every 10 seconds 5 val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
5. join(otherStream, [numTasks])
a) 連接數據流
b) 官方文檔代碼舉例1
1 val stream1: DStream[String, String] = ... 2 val stream2: DStream[String, String] = ... 3 val joinedStream = stream1.join(stream2)
c) 官方文檔代碼舉例2
1 val windowedStream1 = stream1.window(Seconds(20)) 2 val windowedStream2 = stream2.window(Minutes(1)) 3 val joinedStream = windowedStream1.join(windowedStream2)
Output Operation
|
名稱 |
說明 |
|
print() |
Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. |
|
saveAsTextFiles(prefix, [suffix]) |
Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
|
saveAsObjectFiles(prefix, [suffix]) |
Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
|
saveAsHadoopFiles(prefix, [suffix]) |
Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
|
foreachRDD(func) |
The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
緩存與持久化
1. 通過persist()將DStream中每個RDD存儲在記憶體。
2. Window operations會自動持久化在記憶體,無需顯示調用persist()。
3. 通過網路接收的數據流(如Kafka、Flume、Socket、ZeroMQ、RocketMQ等)執行persist()時,預設在兩個節點上持久化序列化後的數據,實現容錯。
Checkpoint
1. 用途:Spark基於容錯存儲系統(如HDFS、S3)進行故障恢復。
2. 分類
a) 元數據檢查點:保存流式計算信息用於Driver運行節點的故障恢復,包括創建應用程式的配置、應用程式定義的DStream operations、已入隊但未完成的批次。
b) 數據檢查點:保存生成的RDD。由於stateful transformation需要合併多個批次的數據,即生成的RDD依賴於前幾個批次RDD的數據(dependency chain),為縮短dependency chain從而減少故障恢復時間,需將中間RDD定期保存至可靠存儲(如HDFS)。
3. 使用時機:
a) Stateful transformation:updateStateByKey()以及window operations。
b) 需要Driver故障恢復的應用程式。
4. 使用方法
a) Stateful transformation
streamingContext.checkpoint(checkpointDirectory)
b) 需要Driver故障恢復的應用程式(以WordCount舉例):如果checkpoint目錄存在,則根據checkpoint數據創建新StreamingContext;否則(如首次運行)新建StreamingContext。
1 import org.apache.spark.SparkConf 2 import org.apache.spark.storage.StorageLevel 3 import org.apache.spark.streaming.Seconds 4 import org.apache.spark.streaming.StreamingContext 5 import org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctions 6 7 object Test { 8 def main(args: Array[String]): Unit = { 9 val checkpointDir = "/spark/checkpoint" 10 def createContextFunc(): StreamingContext = { 11 val conf = new SparkConf().setAppName("Test") 12 val ssc = new StreamingContext(conf, Seconds(1)) 13 ssc.checkpoint(checkpointDir) 14 ssc 15 } 16 val ssc = StreamingContext.getOrCreate(checkpointDir, createContextFunc _) 17 18 val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER) 19 val wordCounts = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) 20 wordCounts.print 21 22 ssc.start 23 ssc.awaitTermination 24 } 25 }
5. checkpoint時間間隔
a) 方法
dstream.checkpoint(checkpointInterval)
b) 原則:一般設置為滑動時間間隔的5-10倍。
c) 分析:checkpoint會增加存儲開銷、增加批次處理時間。當批次間隔較小(如1秒)時,checkpoint可能會減小operation吞吐量;反之,checkpoint時間間隔較大會導致lineage和task數量增長。
性能調優
降低批次處理時間
1. 數據接收並行度
a) 增加DStream:接收網路數據(如Kafka、Flume、Socket等)時會對數據反序列化再存儲在Spark,由於一個DStream只有Receiver對象,如果成為瓶頸可考慮增加DStream。
1 val numStreams = 5 2 val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) } 3 val unifiedStream = streamingContext.union(kafkaStreams) 4 unifiedStream.print()
b) 設置“spark.streaming.blockInterval”參數:接收的數據被存儲在Spark記憶體前,會被合併成block,而block數量決定了Task數量;舉例,當批次時間間隔為2秒且block時間間隔為200毫秒時,Task數量約為10;如果Task數量過低,則浪費了CPU資源;推薦的最小block時間間隔為50毫秒。
c) 顯式對Input DStream重新分區:在進行更深層次處理前,先對輸入數據重新分區。
inputStream.repartition(<number of partitions>)
2. 數據處理並行度:reduceByKey、reduceByKeyAndWindow等operation可通過設置“spark.default.parallelism”參數或顯式設置並行度方法參數控制。
3. 數據序列化:可配置更高效的Kryo序列化。
設置合理批次時間間隔
1. 原則:處理數據的速度應大於或等於數據輸入的速度,即批次處理時間大於或等於批次時間間隔。
2. 方法:
a) 先設置批次時間間隔為5-10秒以降低數據輸入速度;
b) 再通過查看log4j日誌中的“Total delay”,逐步調整批次時間間隔,保證“Total delay”小於批次時間間隔。
記憶體調優
1. 持久化級別:開啟壓縮,設置參數“spark.rdd.compress”。
2. GC策略:在Driver和Executor上開啟CMS。
作者:netoxi
出處:http://www.cnblogs.com/netoxi
本文版權歸作者和博客園共有,歡迎轉載,未經同意須保留此段聲明,且在文章頁面明顯位置給出原文連接。歡迎指正與交流。

