
通過python 來實現這樣一個簡單的爬蟲功能,把我們想要的圖片爬取到本地。(Python版本為3.6.0) 一.獲取整個頁面數據 說明: 向getHtml()函數傳遞一個網址,就可以把整個頁面下載下來. urllib.request 模塊提供了讀取web頁面數據的介面,我們可以像讀取本地文件一樣讀 ...
通過python 來實現這樣一個簡單的爬蟲功能,把我們想要的圖片爬取到本地。(Python版本為3.6.0)
一.獲取整個頁面數據
def getHtml(url): page=urllib.request.urlopen(url) html=page.read() return html
說明:
向getHtml()函數傳遞一個網址,就可以把整個頁面下載下來.
urllib.request 模塊提供了讀取web頁面數據的介面,我們可以像讀取本地文件一樣讀取www和ftp上的數據.
二.篩選頁面中想要的數據
在百度貼吧找到了幾張漂亮的圖片,想要下載下來.使用火狐瀏覽器,在圖片位置滑鼠右鍵單單擊有查看元素選項,點進去之後就會進入開發者模式,並且定位到圖片所在的前段代碼
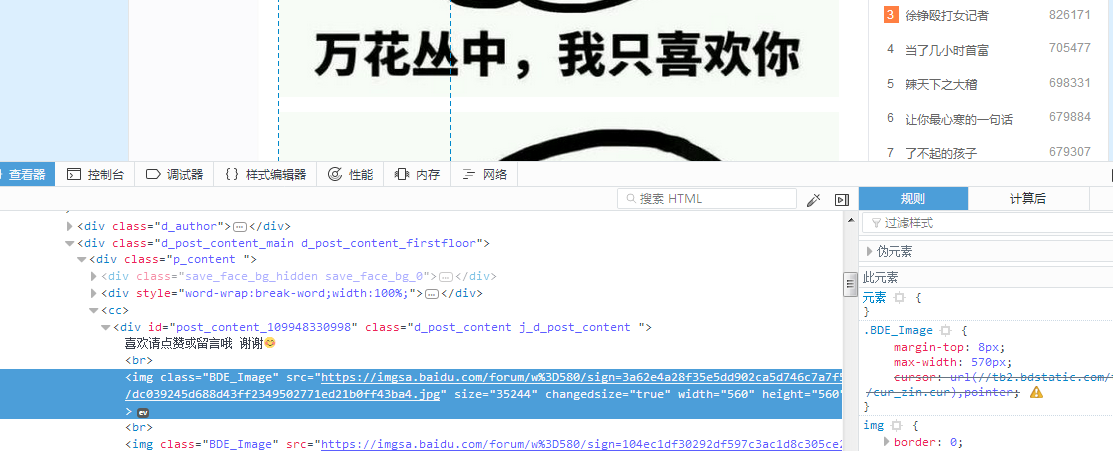
現在主要觀察圖片的正則特征,編寫正則表達式.
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
#參考正則
編寫代碼
def getImg(html): reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"' imgre = re.compile(reg) imglist = re.findall(imgre,html.decode('utf-8')) return imglist
說明:
re.compile() 可以把正則表達式編譯成一個正則表達式對象.
re.findall() 方法讀取html 中包含 imgre(正則表達式)的數據。
運行腳本將得到整個頁面中包含圖片的URL地址。
三.將頁面篩選的數據保存到本地
編寫一個保存的函數
def saveFile(x): if not os.path.isdir(path): os.makedirs(path) t = os.path.join(path,'%s.img'%x) return t
完整代碼:
''' Created on 2017年7月15日 @author: Administrator ''' import urllib.request,os import re def getHtml(url): page=urllib.request.urlopen(url) html=page.read() return html path='D:/workspace/Python1/reptile/__pycache__/img' def saveFile(x): if not os.path.isdir(path): os.makedirs(path) t = os.path.join(path,'%s.img'%x) return t html=getHtml('https://tieba.baidu.com/p/5248432620') print(html) print('\n') def getImg(htnl): reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"' imgre=re.compile(reg) imglist=re.findall(imgre,html.decode('utf-8')) x=0 for imgurl in imglist: urllib.request.urlretrieve(imgurl,saveFile(x)) print(imgurl) x+=1 if x==23: break print(x) return imglist getImg(html) print('end')
核心是用到了urllib.request.urlretrieve()方法,直接將遠程數據下載到本地
最後,有點問題還沒有完全解決,這裡也向大家請教一下.
當下載圖片超過23張時會報錯:
urllib.error.HTTPError: HTTP Error 500: Internal Server Error
不知道是什麼問題,求助.

