
1 概述 1 概述 已發佈【SqlServer系列】文章如下: 【SqlServer系列】SQLSERVER安裝教程 【SqlServer系列】資料庫三大範式 【SqlServer系列】表單查詢 【SqlServer系列】表連接 【SqlServer系列】子查詢 【SqlServer系列】開啟Sql ...
1 概述
已發佈【SqlServer系列】文章如下:
- 【SqlServer系列】SQLSERVER安裝教程
- 【SqlServer系列】資料庫三大範式
- 【SqlServer系列】表單查詢
- 【SqlServer系列】表連接
- 【SqlServer系列】子查詢
- 【SqlServer系列】開啟Sqlserver遠程訪問
本篇文章接著寫【SqlServer系列】集合運算,主要內容為:1、並集(UNION)運算、交集(INTERSECT)運算、差集(EXCEPT)運算 2、集合運算優先順序 3、避開不支持的邏輯查詢處理
1.2 關於三種運算簡要概述

1.3 本章測試樣表和SQL
業務場景
有兩張表,分別為員工表(員工ID,員工姓名,職位,學位,籍貫,電話)和銷售表(銷售ID,員工ID,員工姓名,職位,學位,銷售額)

(1)創建集合DB:WJM_CollectDemo
1 IF DB_ID('WJM_CollectDemo') IS NOT NULL
2 DROP DATABASE WJM_CollectDemo
3 GO
4 CREATE DATABASE WJM_CollectDemo
(2)創建員工表並初始化
1 USE WJM_CollecDemo
2
3 --CREATE TABLE(Employees) AND INITIAL
4 CREATE TABLE Employees
5 (
6 empID INT IDENTITY(1,1) PRIMARY KEY NOT NULL,
7 empName VARCHAR(50),
8 position VARCHAR(50),
9 degree VARCHAR(50),
10 jiGuan VARCHAR(50),
11 tel VARCHAR(50),
12 )
13
14 INSERT INTO Employees VALUES
15 ('張三','銷售經理','本科','上海','021-298989'),
16 ('李四','銷售','本科','北京','010-298181'),
17 ('李明','銷售','','深圳','0755-698988'),
18 ('王華','銷售','本科','杭州','0571-593132')
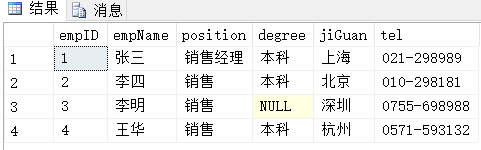
執行查詢語句
1 SELECT *
2 FROM Employees
查詢結果為:
(3)創建銷售表並初始化
1 USE WJM_CollectDemo
2
3 --CREATE TABLE(Sales) AND INITIAL
4 CREATE TABLE Sales
5 (
6 salesID INT IDENTITY(1,1) PRIMARY KEY NOT NULL,
7 empID INT,
8 empName VARCHAR(50),
9 position VARCHAR(50),
10 degree VARCHAR(50),
11 SaleCount VARCHAR(100)
12 )
13
14 INSERT INTO Sales VALUES
15 ('1','張三','銷售經理','本科','5000w'),
16 ('3','李明','銷售','','100w'),
17 ('4','王華','銷售','本科','1500w'),
18 ('','張濤','外聘銷售','碩士','2000w')
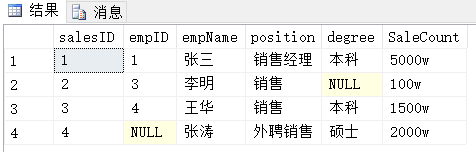
執行查詢語句
1 SELECT *
2 FROM Sales
查詢結果
2 三種基本的集合運算
2.1 並集運算(UNION)
(1)UNION ALL(不刪除重覆行)
Code:
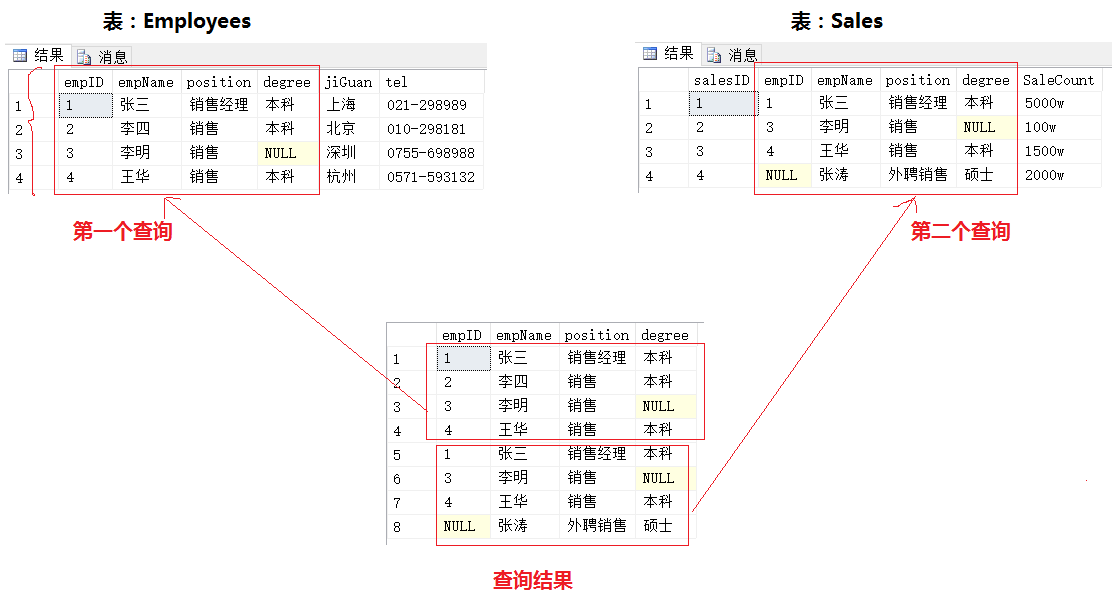
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION ALL
4 SELECT empID,empName,position,degree
5 FROM Sales
查詢結果:
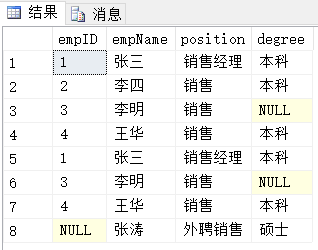
結果分析:
生成結果為:第一個查詢結果集與第二個查詢結果集簡單的組合,保留重覆行。
(2)UNION(隱式DINSTINCT,刪除重覆行)
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION
4 SELECT empID,empName,position,degree
5 FROM Sales
查詢結果:
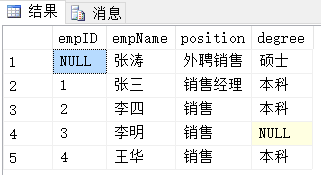
結果分析:
UNION(隱式DISTINCT)相當與把UNION ALL當作中間結果,然後在其基礎上通過DISTINCT過濾掉重覆行;
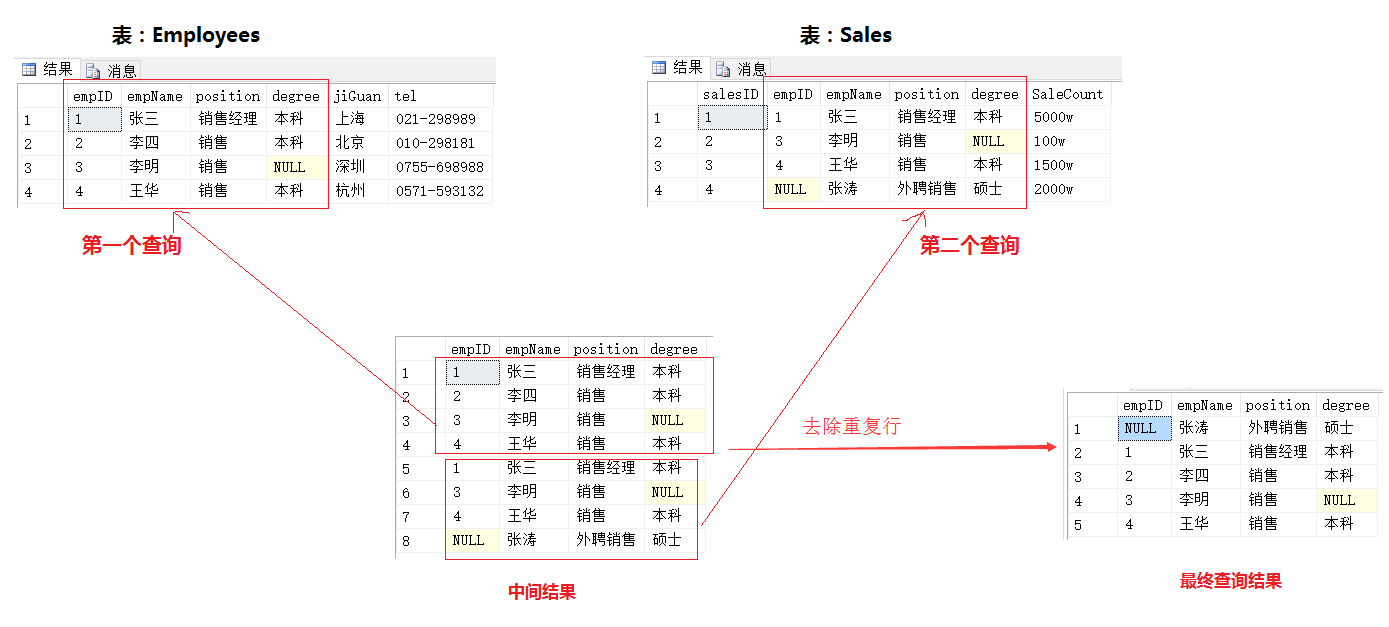
(3)小結
a.並集為兩個查詢結果集的簡單組合;
b.多集指集合中有重覆的行,單集指集合中沒有重覆行; c.UNION ALL一般為多集,UNION(UNION DISTINCT)一般為集合; d.具有對稱性,即無論哪個查詢在前面,查詢結果都是一樣的;
e.進行null值比較時,認為是相等的,而內連接,EXISTS謂詞在進行null比較結果為UNKNOWN;
2.2 交集(INTERSECT)
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 INTERSECT
4 SELECT empID,empName,position,degree
5 FROM Sales
查詢結果:

結果分析:
交集為第一個查詢結果集和第二個查詢結果集公有的部分
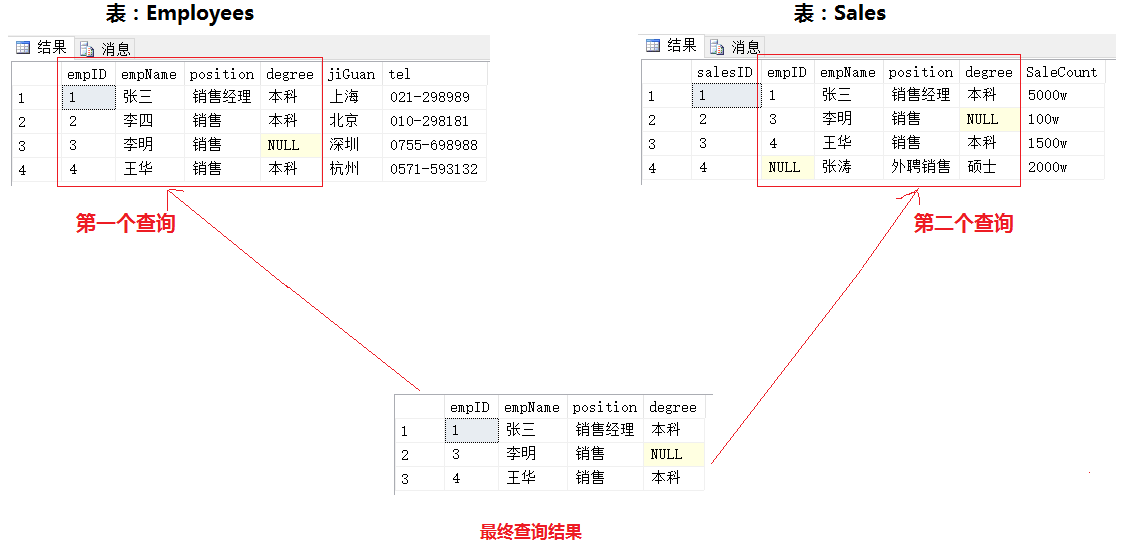
小結
a.交集為第一個查詢結果集和第二個查詢結果集公有的部分;
b.進行null值比較時,認為是相等的,而內連接,EXISTS謂詞在進行null比較結果為UNKNOWN; c.有兩種INTERSECT和INTETSECT ALL(SQL2008版本沒實現); d.具有對稱性,即無論哪個查詢在前面,查詢結果都是一樣的;
2.3 差集
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 EXCEPT
4 SELECT empID,empName,position,degree
5 FROM Sales
查詢結果:
![]()
結果分析:
差集運算對兩個輸入查詢的結果集進行操作,返回出現在第一個結果集,但不出現在第二個結果集中的所有行
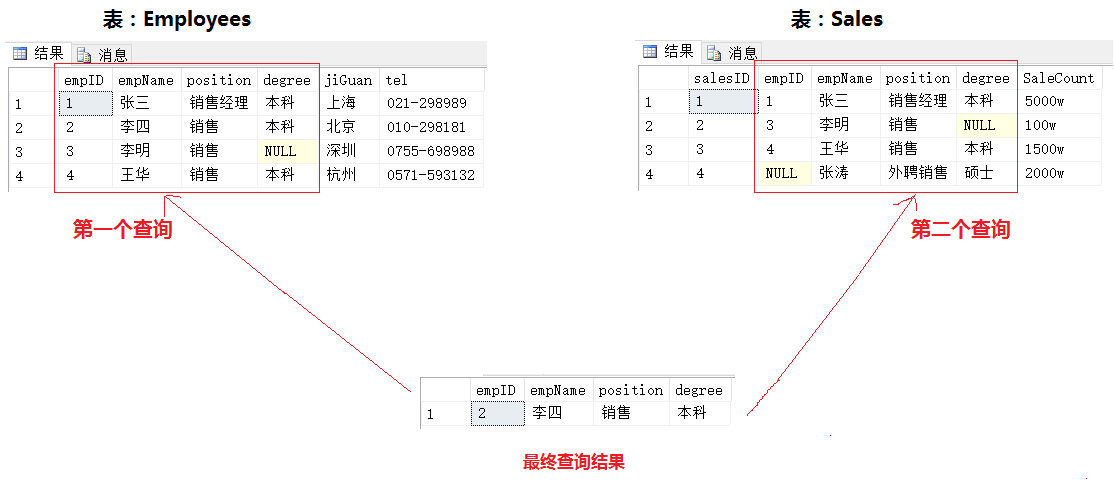
小結:
a. EXCEPT運算對兩個輸入查詢的結果集進行操作,返回出現在第一個結果集,但不出現在第二個結果集中的所有行; b.不具有對稱性;
c.有兩種EXCEPT和EXCEPT ALL(SQL2008版本沒實現);
3 集合運算的優先順序
SQL定義了集合運算之間的優先順序。INTERSECT優先順序比UNION和EXCEPT高,UNION和EXCEPT優先順序一樣。執行順序為從左到右執行。
CODE:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION
4 SELECT empID,empName,position,degree
5 FROM Sales
6 INTERSECT
7 SELECT empID,empName,position,degree
8 FROM Employees
查詢結果:
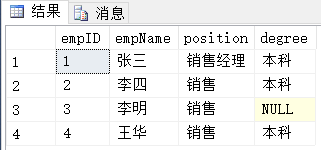
結果分析:

小結:
a.INTERSECT優先順序最高,UNION和EXCEPT優先順序一樣;
b.按照從左=>右的執行順序執行;
4 避開不支持的查詢處理
略(高級部分講解)
5 參考文獻
【01】Microsoft SqlServer 2008技術內幕:T-SQL 語言基礎
【02】Microsoft SqlServer 2008技術內幕:T-SQL 查詢
6 版權
- 感謝您的閱讀,若有不足之處,歡迎指教,共同學習、共同進步。
- 博主網址:http://www.cnblogs.com/wangjiming/。
- 極少部分文章利用讀書、參考、引用、抄襲、複製和粘貼等多種方式整合而成的,大部分為原創。
- 如您喜歡,麻煩推薦一下;如您有新想法,歡迎提出,郵箱:[email protected]。
- 可以轉載該博客,但必須著名博客來源。


