
本文通過示例詳細分析rsync演算法原理和rsync的工作流程,是對rsync官方技術報告和官方推薦文章的解釋。 以下是rsync系列篇: 1.rsync(一):基本命令和用法 2.rsync(二):inotify+rsync詳細說明和sersync 3.rsync演算法原理和工作流程分析 4.rsyn ...
本文通過示例詳細分析rsync演算法原理和rsync的工作流程,是對rsync官方技術報告和官方推薦文章的解釋。
以下是rsync系列篇:
2.rsync(二):inotify+rsync詳細說明和sersync
本文目錄:
rsync的核心功能是實現本地和遠程主機之間文件同步,它的優點在於增量傳輸。本文不會介紹如何使用rsync命令(見rsync基本用法),而是詳細解釋它如何實現高效的增量傳輸。
在開始分析演算法原理之前,簡單說明下rsync的增量傳輸功能。
假設待傳輸文件為A,如果目標路徑下沒有文件A,則rsync會直接傳輸文件A,如果目標路徑下已存在文件A,則發送端視情況決定是否要傳輸文件A。rsync預設使用"quick check"演算法,它會比較源文件和目標文件(如果存在)的文件大小和修改時間mtime,如果兩端文件的大小或mtime不同,則發送端會傳輸該文件,否則將忽略該文件。
如果"quick check"演算法決定了要傳輸文件A,它不會傳輸整個文件A,而是只傳源文件A和目標文件A所不同的部分,這才是真正的增量傳輸。
也就是說,rsync的增量傳輸體現在兩個方面:文件級的增量傳輸和數據塊級別的增量傳輸。文件級別的增量傳輸是指源主機上有,但目標主機上沒有將直接傳輸該文件,數據塊級別的增量傳輸是指只傳輸兩文件所不同的那一部分數據。但從本質上來說,文件級別的增量傳輸是數據塊級別增量傳輸的特殊情況。通讀本文後,很容易理解這一點。
1.1 需要解決的問題
假設主機α上有文件A,主機β上有文件B(實際上這兩文件是同名文件,此處為了區分所以命名為A和B),現在要讓B文件和A文件保持同步。
最簡單的方法是將A文件直接拷貝到β主機上。但如果文件A很大,且B和A是相似的(意味著兩文件實際內容只有少部分不同),拷貝整個文件A可能會消耗不少時間。如果可以拷貝A和B不同的那一小部分,則傳輸過程會很快。rsync增量傳輸演算法就充分利用了文件的相似性,解決了遠程增量拷貝的問題。
假設文件A的內容為"123xxabc def",文件B的內容為"123abcdefg"。A與B相比,相同的數據部分有123/abc/def,A中多出的內容為xx和一個空格,但文件B比文件A多出了數據g。最終的目標是讓B和A的內容完全相同。
如果採用rsync增量傳輸演算法,α主機將只傳輸文件A中的xx和空格數據給β主機,對於那些相同內容123/abc/def,β主機會直接從B文件中拷貝。根據這兩個來源的數據,β主機就能組建成一個文件A的副本,最後將此副本文件重命名並覆蓋掉B文件就保證了同步。
雖然看上去過程很簡單,但其中有很多細節需要去深究。例如,α主機如何知道A文件中哪些部分和B文件不同,β主機接收了α主機發送的A、B不同部分的數據,如何組建文件A的副本。
1.2 rsync增量傳輸演算法原理
假設執行的rsync命令是將A文件推到β主機上使得B文件和A文件保持同步,即主機α是源主機,是數據的發送端(sender),β是目標主機,是數據的接收端(receiver)。在保證B文件和A文件同步時,大致有以下6個過程:
(1).α主機告訴β主機文件A待傳輸。
(2).β主機收到信息後,將文件B劃分為一系列大小固定的數據塊(建議大小在500-1000位元組之間),並以chunk號碼對數據塊進行編號,同時還會記錄數據塊的起始偏移地址以及數據塊長度。顯然最後一個數據塊的大小可能更小。
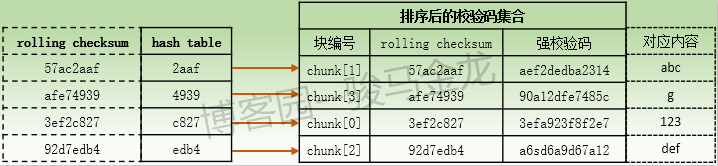
對於文件B的內容"123abcdefg"來說,假設劃分的數據塊大小為3位元組,則根據字元數劃分成了以下幾個數據塊:
count=4 n=3 rem=1 這表示劃分了4個數據塊,數據塊大小為3位元組,剩餘1位元組給了最後一個數據塊 chunk[0]:offset=0 len=3 該數據塊對應的內容為123 chunk[1]:offset=3 len=3 該數據塊對應的內容為abc chunk[2]:offset=6 len=3 該數據塊對應的內容為def chunk[3]:offset=9 len=1 該數據塊對應的內容為g
當然,實際信息中肯定是不會包括文件內容的。
(3).β主機對文件B的每個數據塊根據其內容都計算兩個校驗碼:32位的弱滾動校驗碼(rolling checksum)和128位的MD4強校驗碼(現在版本的rsync使用的已經是128位的MD5強校驗碼)。並將文件B計算出的所有rolling checksum和強校驗碼跟隨在對應數據塊chunk[N]後形成校驗碼集合,然後發送給主機α。
也就是說,校驗碼集合的內容大致如下:其中sum1為rolling checksum,sum2為強校驗碼。
chunk[0] sum1=3ef2c827 sum2=3efa923f8f2e7 chunk[1] sum1=57ac2aaf sum2=aef2dedba2314 chunk[2] sum1=92d7edb4 sum2=a6sd6a9d67a12 chunk[3] sum1=afe74939 sum2=90a12dfe7485c
需要註意,不同內容的數據塊計算出的rolling checksum是有可能相同的,但是概率非常小。
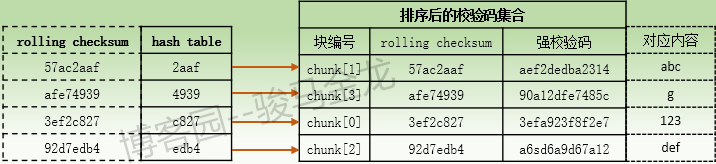
(4).當α主機接收到文件B的校驗碼集合後,α主機將對此校驗碼集合中的每個rolling checksum計算16位長度的hash值,並將每216個hash值按照hash順序放入一個hash table中,hash表中的每一個hash條目都指向校驗碼集合中它所對應的rolling checksum的chunk號碼,然後對校驗碼集合根據hash值進行排序,這樣排序後的校驗碼集合中的順序就能和hash表中的順序對應起來。
所以,hash表和排序後的校驗碼集合對應關係大致如下:假設hash表中的hash值是根據首個字元按照[0-9a-f]的順序進行排序的。
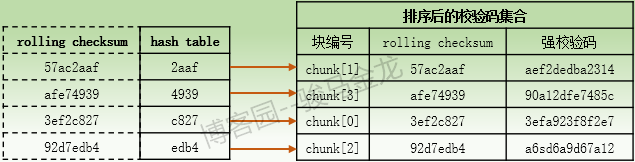
同樣需要註意,不同rolling checksum計算出的hash值也是有可能會相同的,概率也比較小,但比rolling checksum出現重覆的概率要大一些。
(5).隨後主機α將對文件A進行處理。處理的過程是從第1個位元組開始取相同大小的數據塊,並計算它的校驗碼和校驗碼集合中的校驗碼進行匹配。如果能匹配上校驗碼集合中的某個數據塊條目,則表示該數據塊和文件B中數據塊相同,它不需要傳輸,於是主機α直接跳轉到該數據塊的結尾偏移地址,從此偏移處繼續取數據塊進行匹配。如果不能匹配校驗碼集合中的數據塊條目,則表示該數據塊是非匹配數據塊,它需要傳輸給主機β,於是主機α將跳轉到下一個位元組,從此位元組處繼續取數據塊進行匹配。註意,匹配成功時跳過的是整個匹配數據塊,匹配不成功時跳過的僅是一個位元組。可以結合下一小節的示例來理解。
上面說的數據塊匹配只是一種描述,具體的匹配行為需要進行細化。rsync演算法將數據塊匹配過程分為3個層次的搜索匹配過程。
首先,主機α會對取得的數據塊根據它的內容計算出它的rolling checksum,再根據此rolling checksum計算出hash值。
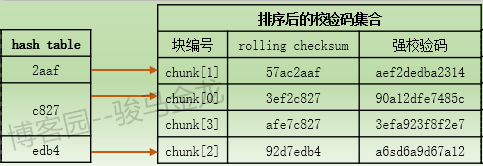
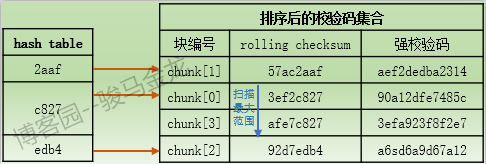
然後,將此hash值去和hash表中的hash條目進行匹配,這是第一層次的搜索匹配過程,它比較的是hash值。如果在hash表中能找到匹配項,則表示該數據塊存在潛在相同的可能性,於是進入第二層次的搜索匹配。
第二層次的搜索匹配是比較rolling checksum。由於第一層次的hash值匹配到了結果,所以將搜索校驗碼集合中與此hash值對應的rolling checksum。由於校驗碼集合是按照hash值排序過的,所以它的順序和hash表中的順序一致,也就是說只需從此hash值對應的rolling chcksum開始向下掃描即可。掃描過程中,如果A文件數據塊的rolling checksum能匹配某項,則表示該數據塊存在潛在相同的可能性,於是停止掃描,併進入第三層次的搜索匹配以作最終的確定。或者如果沒有掃描到匹配項,則說明該數據塊是非匹配塊,也將停止掃描,這說明rolling checksum不同,但根據它計算的hash值卻發生了小概率重覆事件。
第三層次的搜索匹配是比較強校驗碼。此時將對A文件的數據塊新計算一個強校驗碼(在第三層次之前,只對A文件的數據塊計算了rolling checksum和它的hash值),並將此強校驗碼與校驗碼集合中對應強校驗碼匹配,如果能匹配則說明數據塊是完全相同的,不能匹配則說明數據塊是不同的,然後開始取下一個數據塊進行處理。
之所以要額外計算hash值並放入hash表,是因為比較rolling checksum的性能不及hash值比較,且通過hash搜索的演算法性能非常高。由於hash值重覆的概率足夠小,所以對絕大多數內容不同的數據塊都能直接通過第一層次搜索的hash值比較出來,即使發生了小概率hash值重覆事件,還能迅速定位並比較更小概率重覆的rolling checksum。即使不同內容計算的rolling checksum也可能出現重覆,但它的重覆概率比hash值重覆概率更小,所以通過這兩個層次的搜索就能比較出幾乎所有不同的數據塊。假設不同內容的數據塊的rolling checksum還是出現了小概率重覆,它將進行第三層次的強校驗碼比較,它採用的是MD4(現在是MD5),這種演算法具有"雪崩效應",只要一點點不同,結果都是天翻地覆的不同,所以在現實使用過程中,完全可以假設它能做最終的比較。
數據塊大小會影響rsync演算法的性能。如果數據塊大小太小,則數據塊的數量就太多,需要計算和匹配的數據塊校驗碼就太多,性能就差,而且出現hash值重覆、rolling checksum重覆的可能性也增大;如果數據塊大小太大,則可能會出現很多數據塊都無法匹配的情況,導致這些數據塊都被傳輸,降低了增量傳輸的優勢。所以劃分合適的數據塊大小是非常重要的,預設情況下,rsync會根據文件大小自動判斷數據塊大小,但rsync命令的"-B"(或"--block-size")選項支持手動指定大小,如果手動指定,官方建議大小在500-1000位元組之間。
(6).當α主機發現是匹配數據塊時,將只發送這個匹配塊的附加信息給β主機。同時,如果兩個匹配數據塊之間有非匹配數據,則還會發送這些非匹配數據。當β主機陸陸續續收到這些數據後,會創建一個臨時文件,並通過這些數據重組這個臨時文件,使其內容和A文件相同。臨時文件重組完成後,修改該臨時文件的屬性信息(如許可權、所有者、mtime等),然後重命名該臨時文件替換掉B文件,這樣B文件就和A文件保持了同步。
1.3 通過示例分析rsync演算法
前面說了這麼多理論,可能已經看的雲里霧裡,下麵通過A和B文件的示例來詳細分析上一小節中的增量傳輸演算法原理,由於上一小節中的過程(1)-(4),已經給出了示例,所以下麵將繼續分析過程(5)和過程(6)。
先看文件B(內容為"123abcdefg")排序後的校驗碼集合以及hash表。
當主機α開始處理文件A時,對於文件A的內容"123xxabc def"來說,從第一個位元組開始取大小相同的數據塊,所以取得的第一個數據塊的內容是"123",由於和文件B的chunk[0]內容完全相同,所以α主機對此數據塊計算出的rolling checksum值肯定是"3ef2e827",對應的hash值為"e827"。於是α主機將此hash值去匹配hash表,匹配過程中發現指向chunk[0]的hash值能匹配上,於是進入第二層次的rolling checksum比較,也即從此hash值指向的chunk[0]的條目處開始向下掃描。掃描過程中發現掃描的第一條信息(即chunk[0]對應的條目)的rollign checksum就能匹配上,所以掃描終止,於是進入第三層次的搜索匹配,這時α主機將對"123"這個數據塊新計算一個強校驗碼,與校驗碼集合中chunk[0]對應的強校驗碼做比較,最終發現能匹配上,於是確定了文件A中的"123"數據塊是匹配數據塊,不需要傳輸給β主機。
雖然匹配數據塊不用傳輸,但匹配的相關信息需要立即傳輸給β主機,否則β主機不知道如何重組文件A的副本。匹配塊需要傳輸的信息包括:匹配的是B文件中的chunk[0]數據塊,在文件A中偏移該數據塊的起始偏移地址為第1個位元組,長度為3位元組。
數據塊"123"的匹配信息傳輸完成後,α主機將處取第二個數據塊進行處理。本來應該是從第2個位元組開始取數據塊的,但由於數據塊"123"中3個位元組完全匹配成功,所以可以直接跳過整個數據塊"123",即從第4個位元組開始取數據塊,所以α主機取得的第2個數據塊內容為"xxa"。同樣,需要計算它的rolling checksum和hash值,並搜索匹配hash表中的hash條目,發現沒有任何一條hash值可以匹配上,於是立即確定該數據塊是非匹配數據塊。
此時α主機將繼續向前取A文件中的第三個數據塊進行處理。由於第二個數據塊沒有匹配上,所以取第三個數據塊時只跳過了一個位元組的長度,即從第5個位元組開始取,取得的數據塊內容為"xab"。經過一番計算和匹配,發現這個數據塊和第二個數據塊一樣是無法匹配的數據塊。於是繼續向前跳過一個位元組,即從第6個位元組開始取第四個數據塊,這次取得的數據塊內容為"abc",這個數據塊是匹配數據塊,所以和第一個數據塊的處理方式是一樣的,唯一不同的是第一個數據塊到第四個數據塊,中間兩個數據塊是非匹配數據塊,於是在確定第四個數據塊是匹配數據塊後,會將中間的非匹配內容(即123xxabc中間的xx)逐位元組發送給β主機。
(前文說過,hash值和rolling checksum是有小概率發生重覆,出現重覆時匹配如何進行?見本小節的尾部)
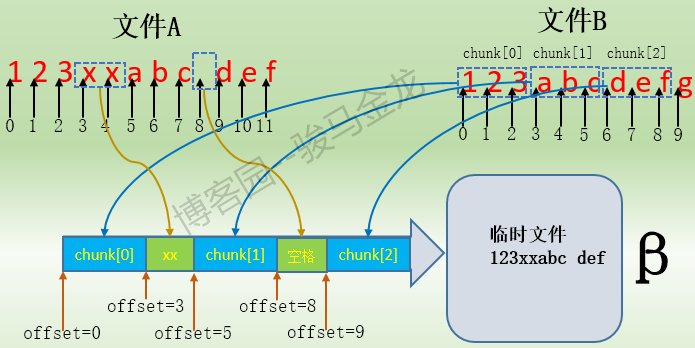
依此方式處理完A中所有數據塊,最終有3個匹配數據塊chunk[0]、chunk[1]和chunk[2],以及2段非匹配數據"xx"和" "。這樣β主機就收到了匹配數據塊的匹配信息以及逐位元組的非匹配純數據,這些數據是β主機重組文件A副本的關鍵信息。它的大致內容如下:
chunk[0] of size 3 at 0 offset=0 data receive 2 at 3 chunk[1] of size 3 at 3 offset=5 data receive 1 at 8 chunk[2] of size 3 at 6 offset=9
為了說明這段信息,首先看文件A和文件B的內容,並標出它們的偏移地址。
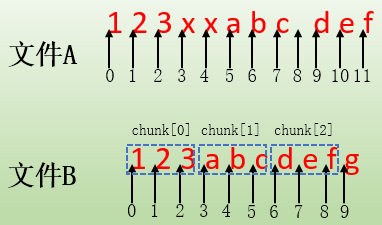
對於"chunk[0] of size 3 at 0 offset=0",這一段表示這是一個匹配數據塊,匹配的是文件B中的chunk[0],數據塊大小為3位元組,關鍵詞at表示這個匹配塊在文件B中的起始偏移地址為0,關鍵詞offset表示這個匹配塊在文件A中起始偏移地址也為0,它也可以認為是重組臨時文件中的偏移。也就是說,在β主機重組文件時,將從文件B的"at 0"偏移處拷貝長度為3位元組的chunk[0]對應的數據塊,並將這個數據塊內容寫入到臨時文件中的offset=0偏移處,這樣臨時文件中就有了第一段數據"123"。
對於"data receive 2 at 3",這一段表示這是接收的純數據信息,不是匹配數據塊。2表示接收的數據位元組數,"at 3"表示在臨時文件的起始偏移3處寫入這兩個位元組的數據。這樣臨時文件就有了包含了數據"123xx"。
對於"chunk[1] of size 3 at 3 offset=5",這一段表示是匹配數據塊,表示從文件B的起始偏移地址at=3處拷貝長度為3位元組的chunk[1]對應的數據塊,並將此數據塊內容寫入在臨時文件的起始偏移offset=5處,這樣臨時文件就有了"123xxabc"。
對於"data receive 1 at 8",這一說明接收了純數據信息,表示將接收到的1個位元組的數據寫入到臨時文件的起始偏移地址8處,所以臨時文件中就有了"123xxabc "。
最後一段"chunk[2] of size 3 at 6 offset=9",表示從文件B的起始偏移地址at=6處拷貝長度為3位元組的chunk[2]對應的數據塊,並將此數據塊內容寫入到臨時文件的起始偏移offset=9處,這樣臨時文件就包含了"123xxabc def"。到此為止,臨時文件就重組結束了,它的內容和α主機上A文件的內容是完全一致的,然後只需將此臨時文件的屬性修改一番,並重命名替換掉文件B即可,這樣就將文件B和文件A進行了同步。
整個過程如下圖:
需要註意的是,α主機不是搜索完所有數據塊之後才將相關數據發送給β主機的,而是每搜索出一個匹配數據塊,就會立即將匹配塊的相關信息以及當前匹配塊和上一個匹配塊中間的非匹配數據發送給β主機,並開始處理下一個數據塊,當β主機每收到一段數據後會立即將將其重組到臨時文件中。因此,α主機和β主機都儘量做到了不浪費任何資源。
1.3.1 hash值和rolling checksum重覆時的匹配過程
在上面的示例分析中,沒有涉及hash值重覆和rolling checksum重覆的情況,但它們有可能會重覆,雖然重覆後的匹配過程是一樣的,但可能不那麼容易理解。
還是看B文件排序後的校驗碼集合。
當文件A處理數據塊時,假設處理的是第2個數據塊,它是非匹配數據塊,對此數據塊會計算rolling checksum和hash值。假設此數據塊的hash值從hash表中匹配成功,例如匹配到了上圖中"4939"這個值,於是會將此第二個數據塊的rolling checksum與hash值"4939"所指向的chunk[3]的rolling checksum作比較,hash值重覆且rolling checksum重覆的可能性幾乎趨近於0,所以就能確定此數據塊是非匹配數據塊。
考慮一種極端情況,假如文件B比較大,劃分的數據塊數量也比較多,那麼B文件自身包含的數據塊的rolling checksum就有可能會出現重覆事件,且hash值也可能會出現重覆事件。
例如chunk[0]和chunk[3]的rolling checksum不同,但根據rolling checksum計算的hash值卻相同,此時hash表和校驗碼集合的對應關係大致如下:
如果文件A中正好有數據塊的hash值能匹配到"c827",於是準備比較rolling checksum,此時將從hash值"c827"指向的chunk[0]向下掃描校驗碼集合。當掃描過程中發現數據塊的rolling checksum正好能匹配到某個rolling checksum,如chunk[0]或chunk[3]對應的rolling checksum,則掃描終止,併進入第三層次的搜索匹配。如果向下掃描的過程中發現直到chunk[2]都沒有找到能匹配的rolling checksum,則掃描終止,因為chunk[2]的hash值和數據塊的hash值已經不同,最終確定該數據塊是非匹配數據塊,於是α主機繼續向前處理下一個數據塊。
假如文件B中數據塊的rolling checksum出現了重覆(這隻說明一件事,你太幸運),將只能通過強校驗碼來匹配。
1.4 rsync工作流程分析
上面已經把rsync增量傳輸的核心分析過了,下麵將分析rsync對增量傳輸演算法的實現方式以及rsync傳輸的整個過程。在這之前,有必要先解釋下rsync傳輸過程中涉及的client/server、sender、receiver、generator等相關概念。
1.4.1 幾個進程和術語
rsync有3種工作方式。一是本地傳輸方式,二是使用遠程shell連接方式,三是使用網路套接字連接rsync daemon模式。
使用遠程shell如ssh連接方式時,本地敲下rsync命令後,將請求和遠程主機建立遠程shell連接如ssh連接,連接建立成功後,在遠程主機上將fork遠程shell進程調用遠程rsync程式,並將rsync所需的選項通過遠程shell命令如ssh傳遞給遠程rsync。這樣兩端就都啟動了rsync,之後它們將通過管道的方式(即使它們之間是本地和遠程的關係)進行通信。
使用網路套接字連接rsync daemon時,當通過網路套接字和遠程已運行好的rsync建立連接時,rsync daemon進程會創建一個子進程來響應該連接並負責後續該連接的所有通信。這樣兩端也都啟動了連接所需的rsync,此後通信方式是通過網路套接字來完成的。
本地傳輸其實是一種特殊的工作方式,首先rsync命令執行時,會有一個rsync進程,然後根據此進程fork另一個rsync進程作為連接的對端,連接建立之後,後續所有的通信將採用管道的方式。
無論使用何種連接方式,發起連接的一端被稱為client,也即執行rsync命令的一段,連接的另一端稱為server端。註意,server端不代表rsync daemon端。server端在rsync中是一個通用術語,是相對client端而言的,只要不是client端,都屬於server端,它可以是本地端,也可以是遠程shell的對端,還可以是遠程rsync daemon端,這和大多數daemon類服務的server端不同。
rsync的client和server端的概念存活周期很短,當client端和server端都啟動好rsync進程並建立好了rsync連接(管道、網路套接字)後,將使用sender端和receiver端來代替client端和server端的概念。sender端為文件發送端,receiver端為文件接收端。
當兩端的rsync連接建立後,sender端的rsync進程稱為sender進程,該進程負責sender端所有的工作。receiver端的rsync進程稱為receiver進程,負責接收sender端發送的數據,以及完成文件重組的工作。receiver端還有一個核心進程——generator進程,該進程負責在receiver端執行"--delete"動作、比較文件大小和mtime以決定文件是否跳過、對每個文件劃分數據塊、計算校驗碼以及生成校驗碼集合,然後將校驗碼集合發送給sender端。
rsync的整個傳輸過程由這3個進程完成,它們是高度流水線化的,generator進程的輸出結果作為sender端的輸入,sender端的輸出結果作為recevier端的輸入。即:
generator進程-->sender進程-->receiver進程
雖然這3個進程是流水線式的,但不意味著它們存在數據等待的延遲,它們是完全獨立、並行工作的。generator計算出一個文件的校驗碼集合發送給sender,會立即計算下一個文件的校驗碼集合,而sender進程一收到generator的校驗碼集合會立即開始處理該文件,處理文件時每遇到一個匹配塊都會立即將這部分相關數據發送給receiver進程,然後立即處理下一個數據塊,而receiver進程收到sender發送的數據後,會立即開始重組工作。也就是說,只要進程被創建了,這3個進程之間是不會互相等待的。
另外,流水線方式也不意味著進程之間不會通信,只是說rsync傳輸過程的主要工作流程是流水線式的。例如receiver進程收到文件列表後就將文件列表交給generator進程。
1.4.2 rsync整個工作流程
假設在α主機上執行rsync命令,將一大堆文件推送到β主機上。
1.首先client和server建立rsync通信的連接,遠程shell連接方式建立的是管道,連接rsync daemon時建立的是網路套接字。
2.rsync連接建立後,sender端的sender進程根據rsync命令行中給出的源文件收集待同步文件,將這些文件放入文件列表(file list)中並傳輸給β主機。在創建文件列表的過程中,有幾點需要說明:
(1).創建文件列表時,會先按照目錄進行排序,然後對排序後的文件列表中的文件進行編號,以後將直接使用文件編號來引用文件。
(2).文件列表中還包含文件的一些屬性信息,包括:許可權mode,文件大小len,所有者和所屬組uid/gid,最近修改時間mtime等,當然,有些信息是需要指定選項後才附帶的,例如不指定"-o"和"-g"選項將不包含uid/gid,指定"--checksum"公還將包含文件級的checksum值。
(3).發送文件列表時不是收集完成後一次性發送的,而是按照順序收集一個目錄就發送一個目錄,同理receiver接收時也是一個目錄一個目錄接收的,且接收到的文件列表是已經排過序的。
(4).如果rsync命令中指定了exclude或hide規則,則被這些規則篩選出的文件會在文件列表中標記為hide(exclude規則的本質也是hide)。帶有hide標誌的文件對receiver是不可見的,所以receiver端會認為sender端沒有這些被hide的文件。
3.receiver端從一開始接收到文件列表中的內容後,立即根據receiver進程fork出generator進程。generator進程將根據文件列表掃描本地目錄樹,如果目標路徑下文件已存在,則此文件稱為basis file。
generator的工作總體上分為3步:
(1).如果rsync命令中指定了"--delete"選項,則首先在β主機上執行刪除動作,刪除源路徑下沒有,但目標路徑下有的文件。
(2).然後根據file list中的文件順序,逐個與本地對應文件的文件大小和mtime做比較。如果發現本地文件的大小或mtime與file list中的相同,則表示該文件不需要傳輸,將直接跳過該文件。
(3).如果發現本地文件的大小或mtime不同,則表示該文件是需要傳輸的文件,generator將立即對此文件劃分數據塊並編號,並對每個數據塊計算弱滾動校驗碼(rolling checksum)和強校驗碼,並將這些校驗碼跟隨數據塊編號組合在一起形成校驗碼集合,然後將此文件的編號和校驗碼集合一起發送給sender端。發送完畢後開始處理file list中的下一個文件。
需要註意,α主機上有而β主機上沒有的文件,generator會將文件列表中的此文件的校驗碼設置為空發送給sender。如果指定了"--whole-file"選項,則generator會將file list中的所有文件的校驗碼都設置為空,這樣將使得rsync強制採用全量傳輸功能,而不再使用增量傳輸功能。
從下麵的步驟4開始,這些步驟在前文分析rsync演算法原理時已經給出了非常詳細的解釋,所以此處僅概括性地描述,如有不解之處,請翻到前文查看相關內容。
4.sender進程收到generator發送的數據,會讀取文件編號和校驗碼集合。然後根據校驗碼集合中的弱滾動校驗碼(rolling checksum)計算hash值,並將hash值放入hash表中,且對校驗碼集合按照hash值進行排序,這樣校驗碼集合和hash表的順序就能完全相同。
5.sender進程對校驗碼集合排序完成後,根據讀取到的文件編號處理本地對應的文件。處理的目的是找出能匹配的數據塊(即內容完全相同的數據塊)以及非匹配的數據。每當找到匹配的數據塊時,都將立即發送一些匹配信息給receiver進程。當發送完文件的所有數據後,sender進程還將對此文件生成一個文件級的whole-file校驗碼給receiver。
6.receiver進程接收到sender發送的指令和數據後,立即在目標路徑下創建一個臨時文件,並按照接收到的數據和指令重組該臨時文件,目的是使該文件和α主機上的文件完全一致。重組過程中,能匹配的數據塊將從basis file中copy並寫入到臨時文件,非匹配的數據則是接收自sender端。
7.臨時文件重組完成後,將對此臨時文件生成文件級的校驗碼,並與sender端發送的whole-file校驗碼比較,如果能匹配成功則表示此臨時文件和源文件是完全相同的,也就表示臨時文件重組成功,如果校驗碼匹配失敗,則表示重組過程中可能出錯,將完全從頭開始處理此源文件。
8.當臨時文件重組成功後,receiver進程將修改該臨時文件的屬性信息,包括許可權、所有者、所屬組、mtime等。最後將此文件重命名並覆蓋掉目標路徑下已存在的文件(即basis file)。至此,文件同步完成。
1.5 根據執行過程分析rsync工作流程
為了更直觀地感受上文所解釋的rsync演算法原理和工作流程,下麵將給出兩個rsync執行過程的示例,並分析工作流程,一個是全量傳輸的示例,一個是增量傳輸的示例。
要查看rsync的執行過程,執行在rsync命令行中加上"-vvvv"選項即可。
1.5.1 全量傳輸執行過程分析
要執行的命令為:
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp
目的是將/etc/cron.d目錄、/var/log/anaconda目錄和/etc/issue文件傳輸到172.16.10.5主機上的/tmp目錄下,由於/tmp目錄下不存在這些文件,所以整個過程是全量傳輸的過程。但其本質仍然是採用增量傳輸的演算法,只不過generator發送的校驗碼集合全為空而已。
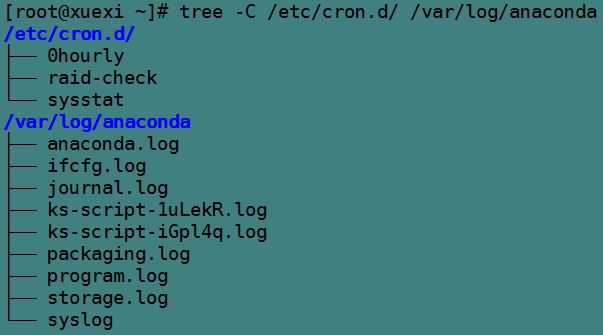
以下是/etc/cron.d目錄和/var/log/anaconda目錄的層次結構。
以下是執行過程。
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp # 使用ssh(ssh為預設的遠程shell)執行遠程rsync命令建立連接 cmd=<NULL> machine=172.16.10.5 user=longshuai path=/tmp cmd[0]=ssh cmd[1]=-l cmd[2]=longshuai cmd[3]=172.16.10.5 cmd[4]=rsync cmd[5]=--server cmd[6]=-vvvvlogDtpre.iLsf cmd[7]=. cmd[8]=/tmp opening connection using: ssh -l longshuai 172.16.10.5 rsync --server -vvvvlogDtpre.iLsf . /tmp note: iconv_open("UTF-8", "UTF-8") succeeded. longshuai@172.16.10.5's password: # 雙方互相發送協議版本號,並協商使用兩者較低版本 (Server) Protocol versions: remote=30, negotiated=30 (Client) Protocol versions: remote=30, negotiated=30 ######### sender端生成文件列表併發送給receiver端 ############# sending incremental file list [sender] make_file(cron.d,*,0) # 第一個要傳輸的文件目錄:cron.d文件,註意,此處cron.d是待傳輸的文件,而不認為是目錄 [sender] make_file(anaconda,*,0) # 第二個要傳輸的文件目錄:anaconda文件 [sender] make_file(issue,*,0) # 第三個要傳輸的文件目錄:issue文件 # 指明從文件列表的第1項開始,並確定這次要傳輸給receiver的項共有3個 [sender] flist start=1, used=3, low=0, high=2 # 為這3項生成列表信息,包括此文件id,所在目錄,許可權模式,長度,uid/gid,最後還有一個修飾符 [sender] i=1 /etc issue mode=0100644 len=23 uid=0 gid=0 flags=5 [sender] i=2 /var/log anaconda/ mode=040755 len=4096 uid=0 gid=0 flas=5 [sender] i=3 /etc cron.d/ mode=040755 len=51 uid=0 gid=0 flags=5 send_file_list done file list sent # 唯一需要註意的是文件所在目錄,例如/var/log anaconda/,但實際在命令行中指定的是/var/log/anaconda。 # 此處信息中log和anaconda使用空格分開了,這個空格非常關鍵。空格左邊的表示隱含目錄(見man rsync的"-R"選項), # 右邊的是待傳輸的整個文件或目錄,預設情況下將會在receiver端生成anaconda/目錄,但左邊隱含目錄則不會創建。 # 但可以通過指定特殊選項(如"-R"),讓rsync也能在receiver端同時創建隱含目錄,以便創建整個目錄層次結構。 # 舉個例子,如果A主機的/a目錄下有b、c等眾多子目錄,並且b目錄中有d文件,現在只想傳輸/a/b/d並保留/a/b的目錄層次結構, # 那麼可以通過特殊選項讓此處的文件所在目錄變為"/ a/",關於具體的實現方法,見"rsync -R選項示例"。 ############ sender端發送文件屬性信息 ##################### # 由於前面的文件列表中有兩個條目是目錄,因此還要為目錄中的每個文件生成屬性信息併發送給receiver端 send_files starting [sender] make_file(anaconda/anaconda.log,*,2) [sender] make_file(anaconda/syslog,*,2) [sender] make_file(anaconda/program.log,*,2) [sender] make_file(anaconda/packaging.log,*,2) [sender] make_file(anaconda/storage.log,*,2) [sender] make_file(anaconda/ifcfg.log,*,2) [sender] make_file(anaconda/ks-script-1uLekR.log,*,2) [sender] make_file(anaconda/ks-script-iGpl4q.log,*,2) [sender] make_file(anaconda/journal.log,*,2) [sender] flist start=5, used=9, low=0, high=8 [sender] i=5 /var/log anaconda/anaconda.log mode=0100600 len=6668 uid=0 gid=0 flags=0 [sender] i=6 /var/log anaconda/ifcfg.log mode=0100600 len=3826 uid=0 gid=0 flags=0 [sender] i=7 /var/log anaconda/journal.log mode=0100600 len=1102699 uid=0 gid=0 flags=0 [sender] i=8 /var/log anaconda/ks-script-1uLekR.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=9 /var/log anaconda/ks-script-iGpl4q.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=10 /var/log anaconda/packaging.log mode=0100600 len=160420 uid=0 gid=0 flags=0 [sender] i=11 /var/log anaconda/program.log mode=0100600 len=27906 uid=0 gid=0 flags=0 [sender] i=12 /var/log anaconda/storage.log mode=0100600 len=78001 uid=0 gid=0 flags=0 [sender] i=13 /var/log anaconda/syslog mode=0100600 len=197961 uid=0 gid=0 flags=0 [sender] make_file(cron.d/0hourly,*,2) [sender] make_file(cron.d/sysstat,*,2) [sender] make_file(cron.d/raid-check,*,2) [sender] flist start=15, used=3, low=0, high=2 [sender] i=15 /etc cron.d/0hourly mode=0100644 len=128 uid=0 gid=0 flags=0 [sender] i=16 /etc cron.d/raid-check mode=0100644 len=108 uid=0 gid=0 flags=0 [sender] i=17 /etc cron.d/sysstat mode=0100600 len=235 uid=0 gid=0 flags=0 # 從上述結果中發現,沒有i=4和i=14的文件信息,因為它們是目錄anaconda和cron.d的文件信息 # 還發現沒有發送/etc/issue文件的信息,因為issue自身是普通文件而非目錄,因此在發送目錄前就發送了 ############# 文件列表所有內容發送完畢 #################### ############### server端相關活動內容 ################ # 首先在server端啟動rsync進程 server_recv(2) starting pid=13309 # 接收client第一次傳輸的數據,此次傳輸server端收到3條數據,它們是傳輸中根目錄下的文件或目錄 received 3 names [receiver] flist start=1, used=3, low=0, high=2 [receiver] i=1 1 issue mode=0100644 len=23 gid=(0) flags=400 [receiver] i=2 1 anaconda/ mode=040755 len=4096 gid=(0) flags=405 [receiver] i=3 1 cron.d/ mode=040755 len=51 gid=(0) flags=405 recv_file_list done # 第一次接收數據完成 ############ 在receiver端啟動generator進程 ######## get_local_name count=3 /tmp # 獲取本地路徑名 generator starting pid=13309 # 啟動generator進程 delta-transmission enabled # 啟用增量傳輸演算法 ############ generator進程設置完畢 ################ ############# 首先處理接收到的普通文件 ############## recv_generator(issue,1) # generator收到receiver進程通知的文件id=1的文件issue send_files(1, /etc/issue) count=0 n=0 rem=0 # 此項為目標主機上的文件issue分割的數據塊信息,count表示數量,n表示數據塊的固定大小, # rem是remain的意思,表示剩餘的數據長度,也即最後一個數據塊的大小, # 此處因為目標端不存在issue文件,因此全部設置為0 send_files mapped /etc/issue of size 23 # sender端映射/etc/issue,使得sender可以獲取到該文件的相關內容 calling match_sums /etc/issue # sender端調用校驗碼匹配功能 issue sending file_sum # 匹配結束後,再發送文件級的checksum給receiver端 false_alarms=0 hash_hits=0 matches=0 # 輸出數據塊匹配的相關統計信息 sender finished /etc/issue # 文件/etc/issue發送完畢,因為目標上不存在issue文件,所以整個過程非常簡單,直接傳輸issue中的全部數據即可 ############## 開始處理目錄格式的文件列表 ############# # 首先接收到兩個id=2和id=3的文件 recv_generator(anaconda,2) recv_generator(cron.d,3) # 然後開始從文件列表的目錄中獲取其中的文件信息 recv_files(3) starting # 先獲取的是dir 0的目錄中的文件信息 [receiver] receiving flist for dir 0 [generator] receiving flist for dir 0 received 9 names # 表示從該目錄中收到了9條文件信息 [generator] flist start=5, used=9, low=0, high=8 # 文件的id號從5開始,總共有9個條目 [generator] i=5 2 anaconda/anaconda.log mode=0100600 len=6668 gid=(0) flags=400 [generator] i=6 2 anaconda/ifcfg.log mode=0100600 len=3826 gid=(0) flags=400 [generator] i=7 2 anaconda/journal.log mode=0100600 len=1102699 gid=(0) flags=400 [generator] i=8 2 anaconda/ks-script-1uLekR.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=9 2 anaconda/ks-script-iGpl4q.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=10 2 anaconda/packaging.log mode=0100600 len=160420 gid=(0) flags=400 [generator] i=11 2 anaconda/program.log mode=0100600 len=27906 gid=(0) flags=400 [generator] i=12 2 anaconda/storage.log mode=0100600 len=78001 gid=(0) flags=400 [generator] i=13 2 anaconda/syslog mode=0100600 len=197961 gid=(0) flags=400 recv_file_list done # dir 0目錄中的文件信息接收完畢 [receiver] receiving flist for dir 1 # 然後獲取的是dir 1的目錄中的文件信息 [generator] receiving flist for dir 1 received 3 names [generator] flist start=15, used=3, low=0, high=2 [generator] i=15 2 cron.d/0hourly mode=0100644 len=128 gid=(0) flags=400 [generator] i=16 2 cron.d/raid-check mode=0100644 len=108 gid=(0) flags=400 [generator] i=17 2 cron.d/sysstat mode=0100600 len=235 gid=(0) flags=400 recv_file_list done # dir 1目錄中的文件信息接收完畢 ################# 開始傳輸目錄dir 0及其內文件 ############# recv_generator(anaconda,4) # generator接收目錄anaconda信息,它的id=4,是否還記得上文sender未發送過id=4和 # id=14的目錄信息?只有先接收該目錄,才能繼續接收該目錄中的文件 send_files(4, /var/log/anaconda) # 因為anaconda是要在receiver端創建的目錄,所以sender端先發送該目錄文件 anaconda/ # anaconda目錄發送成功 set modtime of anaconda to (1494476557) Thu May 11 12:22:37 2017 # 然後再設置目錄anaconda的mtime(即modify time) # receiver端的anaconda目錄已經建立,現在開始傳輸anaconda中的文件 # 以下的第一個anaconda目錄中的第一個文件處理過程 recv_generator(anaconda/anaconda.log,5) # generator進程接收id=5的anaconda/anaconda.log文件 send_files(5, /var/log/anaconda/anaconda.log) count=0 n=0 rem=0 # 計算該文件數據塊相關信息 send_files mapped /var/log/anaconda/anaconda.log of size 6668 # sender端映射anaconda.log文件 calling match_sums /var/log/anaconda/anaconda.log # 調用校驗碼匹配功能 anaconda/anaconda.log sending file_sum # 數據塊匹配結束後,再發送文件級別的checksum給receiver端 false_alarms=0 hash_hits=0 matches=0 # 輸出匹配過程中的統計信息 sender finished /var/log/anaconda/anaconda.log # anaconda.log文件傳輸完成 recv_generator(anaconda/ifcfg.log,6) # 開始處理anaconda中的第二個文件 send_files(6, /var/log/anaconda/ifcfg.log) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/ifcfg.log of size 3826 calling match_sums /var/log/anaconda/ifcfg.log anaconda/ifcfg.log sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/ifcfg.log # 第二個文件傳輸

