
1. hbase簡介 1.1. 什麼是hbase HBASE是一個高可靠性、高性能、面向列、可伸縮的分散式存儲系統,利用HBASE技術可在廉價PC Server上搭建起大規模結構化存儲集群。 HBASE的目標是存儲並處理大型的數據,更具體來說是僅需使用普通的硬體配置,就能夠處理由成千上萬的行和列所組 ...
1. hbase簡介
1.1. 什麼是hbase
HBASE是一個高可靠性、高性能、面向列、可伸縮的分散式存儲系統,利用HBASE技術可在廉價PC Server上搭建起大規模結構化存儲集群。
HBASE的目標是存儲並處理大型的數據,更具體來說是僅需使用普通的硬體配置,就能夠處理由成千上萬的行和列所組成的大型數據。
HBASE是Google Bigtable的開源實現,但是也有很多不同之處。比如:Google Bigtable利用GFS作為其文件存儲系統,HBASE利用Hadoop HDFS作為其文件存儲系統;Google運行MAPREDUCE來處理Bigtable中的海量數據,HBASE同樣利用Hadoop MapReduce來處理HBASE中的海量數據;Google Bigtable利用Chubby作為協同服務,HBASE利用Zookeeper作為對應。
1.2. 與傳統資料庫的對比
1、傳統資料庫遇到的問題:
1)數據量很大的時候無法存儲
2)沒有很好的備份機制
3)數據達到一定數量開始緩慢,很大的話基本無法支撐
2、HBASE優勢:
1)線性擴展,隨著數據量增多可以通過節點擴展進行支撐
2)數據存儲在hdfs上,備份機制健全
3)通過zookeeper協調查找數據,訪問速度塊。
1.3. hbase集群中的角色
1、一個或者多個主節點,Hmaster
2、多個從節點,HregionServer
2. hbase原理
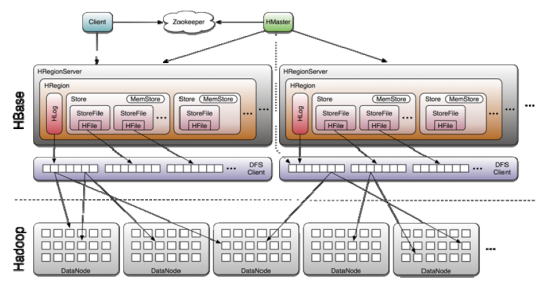
2.1.1. 寫流程
1、 client向hregionserver發送寫請求。
2、 hregionserver將數據寫到hlog(write ahead log)。為了數據的持久化和恢復。
3、 hregionserver將數據寫到記憶體(memstore)
4、 反饋client寫成功。
2.1.2. 數據flush過程
1、 當memstore數據達到閾值(預設是64M),將數據刷到硬碟,將記憶體中的數據刪除,同時刪除Hlog中的歷史數據。
2、 並將數據存儲到hdfs中。
3、 在hlog中做標記點。
2.1.3. 數據合併過程
1、 當數據塊達到4塊,hmaster將數據塊載入到本地,進行合併
2、 當合併的數據超過256M,進行拆分,將拆分後的region分配給不同的hregionserver管理
3、 當hregionser宕機後,將hregionserver上的hlog拆分,然後分配給不同的hregionserver載入,修改.META.
4、 註意:hlog會同步到hdfs
2.1.4. hbase的讀流程
1、 通過zookeeper和-ROOT- .META.表定位hregionserver。
2、 數據從記憶體和硬碟合併後返回給client
3、 數據塊會緩存
2.1.5. hmaster的職責
1、管理用戶對Table的增、刪、改、查操作;
2、記錄region在哪台Hregion server上
3、在Region Split後,負責新Region的分配;
4、新機器加入時,管理HRegion Server的負載均衡,調整Region分佈
5、在HRegion Server宕機後,負責失效HRegion Server 上的Regions遷移。
2.1.6. hregionserver的職責
HRegion Server主要負責響應用戶I/O請求,向HDFS文件系統中讀寫數據,是HBASE中最核心的模塊。
HRegion Server管理了很多table的分區,也就是region。
2.1.7. client職責
HBASE Client使用HBASE的RPC機制與HMaster和RegionServer進行通信
管理類操作:Client與HMaster進行RPC;
數據讀寫類操作:Client與HRegionServer進行RPC。


