
一、進程與線程 1.進程 我們電腦的應用程式,都是進程,假設我們用的電腦是單核的,cpu同時只能執行一個進程。當程式出於I/O阻塞的時候,CPU如果和程式一起等待,那就太浪費了,cpu會去執行其他的程式,此時就涉及到切換,切換前要保存上一個程式運行的狀態,才能恢復,所以就需要有個東西來記錄這個東西, ...
一、進程與線程
1.進程
我們電腦的應用程式,都是進程,假設我們用的電腦是單核的,cpu同時只能執行一個進程。當程式出於I/O阻塞的時候,CPU如果和程式一起等待,那就太浪費了,cpu會去執行其他的程式,此時就涉及到切換,切換前要保存上一個程式運行的狀態,才能恢復,所以就需要有個東西來記錄這個東西,就可以引出進程的概念了。
進程就是一個程式在一個數據集上的一次動態執行過程。進程由程式,數據集,進程式控制制塊三部分組成。程式用來描述進程哪些功能以及如何完成;數據集是程式執行過程中所使用的資源;進程式控制制塊用來保存程式運行的狀態
2.線程
一個進程中可以開多個線程,為什麼要有進程,而不做成線程呢?因為一個程式中,線程共用一套數據,如果都做成進程,每個進程獨占一塊記憶體,那這套數據就要複製好幾份給每個程式,不合理,所以有了線程。
線程又叫輕量級進程,是一個基本的cpu執行單元,也是程式執行過程中的最小單元。一個進程最少也會有一個主線程,在主線程中通過threading模塊,在開子線程
3.進程線程的關係
(1)一個線程只能屬於一個進程,而一個進程可以有多個線程,但至少有一個線程
(2)資源分配給進程,進程是程式的主體,同一進程的所有線程共用該進程的所有資源
(3)cpu分配給線程,即真正在cpu上運行的是線程
(4)線程是最小的執行單元,進程是最小的資源管理單元
4.並行和併發
並行處理是指電腦系統中能同時執行兩個或多個任務的計算方法,並行處理可同時工作於同一程式的不同方面
併發處理是同一時間段內有幾個程式都在一個cpu中處於運行狀態,但任一時刻只有一個程式在cpu上運行。
併發的重點在於有處理多個任務的能力,不一定要同時;而並行的重點在於就是有同時處理多個任務的能力。並行是併發的子集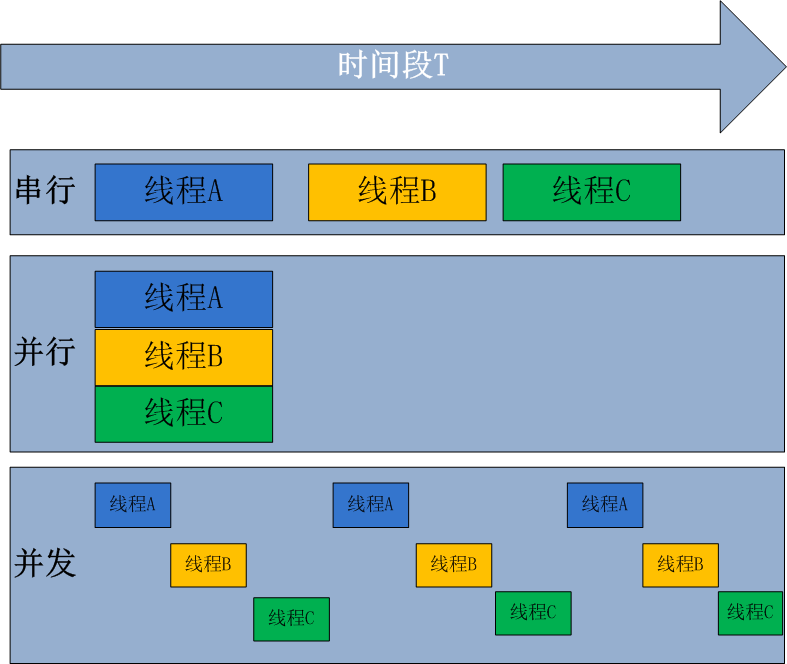
以上所說的是相對於所有語言來說的,Python的特殊之處在於Python有一把GIL鎖,這把鎖限制了同一時間內一個進程只能有一個線程能使用cpu
二、threading模塊
這個模塊的功能就是創建新的線程,有兩種創建線程的方法:
1.直接創建
import threading import time def foo(n): print('>>>>>>>>>>>>>>>%s'%n) time.sleep(3) print('tread 1') t1=threading.Thread(target=foo,args=(2,)) #arg後面一定是元組,t1就是創建的子線程對象 t1.start()#把子進程運行起來 print('ending')
上面的代碼就是在主線程中創建了一個子線程
運行結果是:先列印>>>>>>>>>>>>>2,在列印ending,然後等待3秒後列印thread 1
2.另一種方式是通過繼承類創建線程對象
import threading import time class MyThread(threading.Thread): def __init__(self): threading.Thread.__init__(self) def run(self): print('ok') time.sleep(2) print('end') t1=MyThread()#創建線程對象 t1.start()#激活線程對象 print('end again')
3.join()方法
這個方法的作用是:在子線程完成運行之前,這個子線程的父線程將一直等待子線程運行完再運行
import threading import time def foo(n): print('>>>>>>>>>>>>>>>%s'%n) time.sleep(n) print('tread 1') def bar(n): print('>>>>>>>>>>>>>>>>%s'%n) time.sleep(n) print('thread 2') s=time.time() t1=threading.Thread(target=foo,args=(2,)) t1.start()#把子進程運行起來 t2=threading.Thread(target=bar,args=(5,)) t2.start() t1.join() #只是會阻擋主線程運行,跟t2沒關係 t2.join() print(time.time()-s) print('ending') ''' 運行結果: >>>>>>>>>>>>>>>2 >>>>>>>>>>>>>>>>5 tread 1 thread 2 5.001286268234253 ending '''
4.setDaemon()方法
這個方法的作用是把線程聲明為守護線程,必須在start()方法調用之前設置。
預設情況下,主線程運行完會檢查子線程是否完成,如果未完成,那麼主線程會等待子線程完成後再退出。但是如果主線程完成後不用管子線程是否運行完都退出,就要設置setDaemon(True)
import threading import time class MyThread(threading.Thread): def __init__(self): threading.Thread.__init__(self) def run(self): print('ok') time.sleep(2) print('end') t1=MyThread()#創建線程對象 t1.setDaemon(True) t1.start()#激活線程對象 print('end again') #運行結果是馬上列印ok和 end again #然後程式終止,不會列印end
主線程預設是非守護線程,子線程都是繼承的主線程,所以預設也都是非守護線程
5.其他方法
isAlive(): 返回線程是否處於活動中
getName(): 返回線程名
setName(): 設置線程名
threading.currentThread():返回當前的線程變數
threading.enumerate():返回一個包含正在運行的線程的列表
threading.activeCount():返回正在運行的線程數量
三、各種鎖
1.同步鎖(用戶鎖,互斥鎖)
先來看一個例子:
需求是有一個全局變數的值是100,我們開100個線程,每個線程執行的操作是對這個全局變數減一,最後import threading
import threading import time def sub(): global num temp=num num=temp-1 time.sleep(2) num=100 l=[]for i in range(100): t=threading.Thread(target=sub,args=()) t.start() l.append(t) for i in l: i.join() print(num)
好像一切正常,現在我們改動一下,在sub函數的temp=num,和num=temp-1 中間,加一個time.sleep(0.1),會發現出問題了,結果變成兩秒後列印99了,改成time.sleep(0.0001)呢,結果不確定了,但都是90幾,這是怎麼回事呢?
這就要說到Python里的那把GIL鎖了,我們來捋一捋:
首次定義一個全局變數num=100,然後開闢了100個子線程,但是Python的那把GIL鎖限制了同一時刻只能有一個線程使用cpu,所以這100個線程是處於搶這把鎖的狀態,誰搶到了,誰就可以運行自己的代碼。在最開始的情況下,每個線程搶到cpu,馬上執行了對全局變數減一的操作,所以不會出現問題。但是我們改動後,在全局變數減一之前,讓他睡了0.1秒,程式睡著了,cpu可不能一直等著這個線程,當這個線程處於I/O阻塞的時候,其他線程就又可以搶cpu了,所以其他線程搶到了,開始執行代碼,要知道0.1秒對於cpu的運行來說已經很長時間了,這段時間足夠讓第一個線程還沒睡醒的時候,其他線程都搶到過cpu一次了。他們拿到的num都是100,等他們醒來後,執行的操作都是100-1,所以最後結果是99.同樣的道理,如果睡的時間短一點,變成0.001,可能情況就是當第91個線程第一次搶到cpu的時候,第一個線程已經睡醒了,並修改了全局變數。所以這第91個線程拿到的全局變數就是99,然後第二個第三個線程陸續醒過來,分別修改了全局變數,所以最後結果就是一個不可知的數了。一張圖看懂這個過程
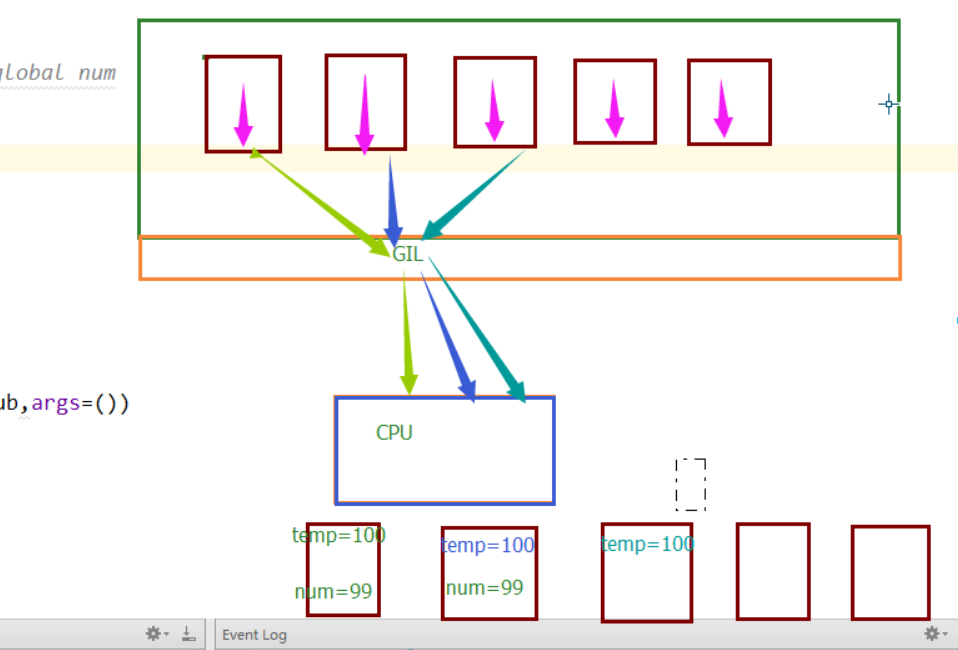
這就是線程安全問題,只要涉及到線程,都會有這個問題。解決辦法就是加鎖
我們在全局加一把鎖,用鎖把涉及到數據運算的操作鎖起來,就把這段代碼變成串列的了,上代碼:
import threading import time def sub(): global num lock.acquire()#獲取鎖 temp=num time.sleep(0.001) num=temp-1 lock.release()#釋放鎖 time.sleep(2) num=100 l=[] lock=threading.Lock() for i in range(100): t=threading.Thread(target=sub,args=()) t.start() l.append(t) for i in l: i.join() print(num)
獲取這把鎖之後,必須釋放掉才能再次被獲取。這把鎖就叫用戶鎖
2.死鎖與遞歸鎖
死鎖就是兩個及以上進程或線程在執行過程中,因相互制約造成的一種互相等待的現象,若無外力作用,他們將永遠卡在那裡。舉個例子:


1 import threading,time 2 3 class MyThread(threading.Thread): 4 def __init(self): 5 threading.Thread.__init__(self) 6 7 def run(self): 8 9 self.foo() 10 self.bar() 11 def foo(self): 12 LockA.acquire() 13 print('i am %s GET LOCKA------%s'%(self.name,time.ctime())) 14 #每個線程有個預設的名字,self.name就獲取這個名字 15 16 LockB.acquire() 17 print('i am %s GET LOCKB-----%s'%(self.name,time.ctime())) 18 19 LockB.release() 20 time.sleep(1) 21 LockA.release() 22 23 def bar(self):#與 24 LockB.acquire() 25 print('i am %s GET LOCKB------%s'%(self.name,time.ctime())) 26 #每個線程有個預設的名字,self.name就獲取這個名字 27 28 LockA.acquire() 29 print('i am %s GET LOCKA-----%s'%(self.name,time.ctime())) 30 31 LockA.release() 32 LockB.release() 33 34 LockA=threading.Lock() 35 LockB=threading.Lock() 36 37 for i in range(10): 38 t=MyThread() 39 t.start() 40 41 #運行結果: 42 i am Thread-1 GET LOCKA------Sun Jul 23 11:25:48 2017 43 i am Thread-1 GET LOCKB-----Sun Jul 23 11:25:48 2017 44 i am Thread-1 GET LOCKB------Sun Jul 23 11:25:49 2017 45 i am Thread-2 GET LOCKA------Sun Jul 23 11:25:49 2017 46 然後就卡住了死鎖示例
上面這個例子中,線程2在等待線程1釋放B鎖,線程1在等待線程2釋放A鎖,互相制約
我們在用互斥鎖的時候,一旦用的鎖多了,很容易就出現這種問題
在Python中,為瞭解決這個問題,Python提供了一個叫可重用鎖(RLock)的概念,這個鎖內部維護著一個lock和一個counter變數,counter記錄了acquire的次數,每次acquire,counter就加1,每次release,counter就減1,只有counter的值為0的時候,其他線程才能獲得資源,下麵用RLock替換Lock,在運行就不會卡住了:
1 import threading,time 2 3 class MyThread(threading.Thread): 4 def __init(self): 5 threading.Thread.__init__(self) 6 7 def run(self): 8 9 self.foo() 10 self.bar() 11 def foo(self): 12 RLock.acquire() 13 print('i am %s GET LOCKA------%s'%(self.name,time.ctime())) 14 #每個線程有個預設的名字,self.name就獲取這個名字 15 16 RLock.acquire() 17 print('i am %s GET LOCKB-----%s'%(self.name,time.ctime())) 18 19 RLock.release() 20 time.sleep(1) 21 RLock.release() 22 23 def bar(self):#與 24 RLock.acquire() 25 print('i am %s GET LOCKB------%s'%(self.name,time.ctime())) 26 #每個線程有個預設的名字,self.name就獲取這個名字 27 28 RLock.acquire() 29 print('i am %s GET LOCKA-----%s'%(self.name,time.ctime())) 30 31 RLock.release() 32 RLock.release() 33 34 LockA=threading.Lock() 35 LockB=threading.Lock() 36 37 RLock=threading.RLock() 38 for i in range(10): 39 t=MyThread() 40 t.start()遞歸鎖示例
這把鎖又叫遞歸鎖
3.Semaphore(信號量)
這也是一把鎖,可以指定有幾個線程可以同時獲得這把鎖,最多是5個(前面說的互斥鎖只能有一個線程獲得)
import threading import time semaphore=threading.Semaphore(5) def foo(): semaphore.acquire() time.sleep(2) print('ok') semaphore.release() for i in range(10): t=threading.Thread(target=foo,args=()) t.start()
運行結果是每隔兩秒就列印5個ok
4.Event對象
線程的運行是獨立的,如果線程間需要通信,或者說某個線程需要根據一個線程的狀態來執行下一步的操作,就需要用到Event對象。可以把Event對象看作是一個標誌位,預設值為假,如果一個線程等待Event對象,而此時Event對象中的標誌位為假,那麼這個線程就會一直等待,直至標誌位為真,為真以後,所有等待Event對象的線程將被喚醒
event.isSet():返回event的狀態值; event.wait():如果 event.isSet()==False將阻塞線程; event.set(): 設置event的狀態值為True,所有阻塞池的線程激活進入就緒狀態, 等待操作系統調度;設置對象的時候,預設是False的 event.clear():恢復event的狀態值為False。
用一個例子來演示Event對象的用法:
import threading,time event=threading.Event() #創建一個event對象 def foo(): print('wait.......') event.wait() #event.wait(1)#if event 對象內的標誌位為Flase,則阻塞 #wait()裡面的參數的意思是:只等待1秒,如果1秒後還沒有把標誌位改過來,就不等了,繼續執行下麵的代碼 print('connect to redis server') print('attempt to start redis sever)') time.sleep(3) event.set() for i in range(5): t=threading.Thread(target=foo,args=()) t.start() #3秒之後,主線程結束,但子線程並不是守護線程,子線程還沒結束,所以,程式並沒有結束,應該是在3秒之後,把標誌位設為true,即event.set()
5.隊列
官方文檔說隊列在多線程中保證數據安全是非常有用的
隊列可以理解為是一種數據結構,可以存儲數據,讀寫數據。就類似列表裡面加了一把鎖
5.1get和put方法
import queue #隊列里讀寫數據只有put和get兩個方法,列表的那些方法都沒有 q=queue.Queue()#創建一個隊列對象 FIFO先進先出 #q=queue.Queue(20) #這裡面可以有一個參數,設置最大存的數據量,可以理解為最大有幾個格子
#如果設置參數為20,第21次put的時候,程式就會阻塞住,直到有空位置,也就是有數據被get走 q.put(11)#放值 q.put('hello') q.put(3.14) print(q.get())#取值11 print(q.get())#取值hello print(q.get())#取值3.14 print(q.get())#阻塞,等待put一個數據
![]()
get方法中有個預設參數block=True,把這個參數改成False,取不到值的時候就會報錯queue.Empty
這樣寫就等同於寫成q.get_nowait())
5.2join和task_done方法
join是用來阻塞進程,與task_done配合使用才有意義。可以用Event對象來理解,沒次put(),join裡面的計數器加1,沒次task_done(),計數器減1,計數器為0的時候,才能進行下次put()
註意要在每個get()後面都加task_done才行
import queue import threading #隊列里只有put和get兩個方法,列表的那些方法都沒有 q=queue.Queue()# def foo():#存數據 # while True: q.put(111) q.put(222) q.put(333) q.join() print('ok')#有個join,程式就停在這裡 def bar(): print(q.get()) q.task_done() print(q.get()) q.task_done() print(q.get()) q.task_done()#要在每個get()語句後面都加上 t1=threading.Thread(target=foo,args=()) t1.start() t2=threading.Thread(target=bar,args=()) t2.start() #t1,t2誰先誰後無所謂,因為會阻塞住,等待信號
5.3 其他方法
q.qsize() 返回隊列的大小 q.empty() 如果隊列為空,返回True,反之False q.full() 如果隊列滿了,返回True,反之False q.full 與 maxsize 大小對應 5.4其他模式前面說的隊列都是先進先出(FIFO)模式,另外還有先進後出(LIFO)模式和優先順序隊列
先進後出模式創建隊列的方式是:class queue.LifoQueue(maxsize)
優先順序隊列的寫法是:class queue.Priorityueue(maxsize)
q=queue.PriorityQueue() q.put([5,100])#這個方括弧只是代表一個序列類型,元組列表都行,但是都必須所有的一樣 q.put([7,200]) q.put([3,"hello"]) q.put([4,{"name":"alex"}]) 中括弧裡面第一個位置就是優先順序 5.5 生產者消費者模型 生產者就相當於產生數據的線程,消費者就相當於取數據的線程。我們在編寫程式的時候,一定要考慮生產數據的能力和消費數據的能力是否匹配,如果不匹配,那肯定要有一方需要等待,所以引入了生產者和消費者模型。 這個模型是通過一個容器來解決生產者和消費者之間的 強耦合問題。有了這個容器,他們不用直接通信,而是通過這個容器,這個容器就是一個阻塞隊列,相當於一個緩衝區,平衡了生產者和消費者的能力。我們寫程式時用的目錄結構,不也是為瞭解耦和嗎 除瞭解決強耦合問題,生產者消費者模型還能實現併發 當生產者消費者能力不匹配的時候,就考慮加限制,類似if q.qsize()<20,這種四、多進程
python 中有一把全局鎖(GIL)使得多線程無法使用多核,但是如果是多進程,這把鎖就限制不了了。如何開多個進程呢,需要導入一個multiprocessing模塊
import multiprocessing import time def foo(): print('ok') time.sleep(2) if __name__ == '__main__':#必須是這個格式 p=multiprocessing.Process(target=foo,args=()) p.start() print('ending')
雖然可以開多進程,但是一定註意不能開太多,因為進程間切換非常消耗系統資源,如果開上千個子進程,系統會崩潰的,而且進程間的通信也是個問題。所以,進程能不用就不用,能少用就少用
1.進程間的通信
進程間通信有兩種方式,隊列和管道
1.1進程間的隊列
每個進程在記憶體中都是獨立的一塊空間,不項線程那樣可以共用數據,所以只能由父進程通過傳參的方式把隊列傳給子進程
import multiprocessing import threading def foo(q): q.put([12,'hello',True]) if __name__ =='__main__': q=multiprocessing.Queue()#創建進程隊列 #創建一個子線程 p=multiprocessing.Process(target=foo,args=(q,)) #通過傳參的方式把這個隊列對象傳給父進程 p.start() print(q.get())
1.2管道
之前學過的socket其實就是管道,客戶端 的sock和服務端的conn是管道 的兩端,在進程中也是這個玩法,也要有管道的兩頭
from multiprocessing import Pipe,Process def foo(sk): sk.send('hello')#主進程發消息 print(sk.recv())#主進程收消息 sock,conn=Pipe()#創建了管道的兩頭 if __name__ == '__main__': p=Process(target=foo,args=(sock,)) p.start() print(conn.recv())#子進程接收消息 conn.send('hi son')#子進程發消息
2.進程間的數據共用
我們已經通過進程隊列和管道兩種方式實現了進程間的通信,但是還沒有實現數據共用
進程間的數據共用需要引用一個manager對象實現,使用的所有的數據類型都要通過manager點的方式去創建
from multiprocessing import Process from multiprocessing import Manager def foo(l,i): l.append(i*i) if __name__ == '__main__': manager = Manager() Mlist = manager.list([11,22,33])#創建一個共用的列表 l=[] for i in range(5): #開闢5個子進程 p = Process(target=foo, args=(Mlist,i)) p.start() l.append(p) for i in l: i.join()#join 方法是等待進程結束後再執行下一個 print(Mlist)
3.進程池
進程池的作用是維護一個最大的進程量,如果超出設置的最大值,程式就會阻塞,知道有可用的進程為止
from multiprocessing import Pool import time def foo(n): print(n) time.sleep(2) if __name__ == '__main__': pool_obj=Pool(5)#創建進程池 #通過進程池創建進程 for i in range(5): p=pool_obj.apply_async(func=foo,args=(i,)) #p是創建的池對象 # pool 的使用是先close(),在join(),記住就行了 pool_obj.close() pool_obj.join() print('ending')
進程池中有以下幾個方法:
1.apply:從進程池裡取一個進程並執行 2.apply_async:apply的非同步版本 3.terminate:立刻關閉線程池 4.join:主進程等待所有子進程執行完畢,必須在close或terminate之後 5.close:等待所有進程結束後,才關閉線程池
五、協程
協程在手,天下我有,說走就走。知道了協程,前面說的進程線程就都忘記吧
協程可以開很多很多,沒有上限,切換之間的消耗可以忽略不計
1.yield
先來回想一下yield這個詞,熟悉不,對,就是生成器那用的那個。yield是個挺神奇的東西,這是Python的一個特點。
一般的函數,是遇到return就停止,然後返回return 後面的值,預設是None,yield和return很像,但是遇到yield不會立刻停止,而是暫停住,直到遇到next(),(for迴圈的原理也是next())才會繼續執行。yield 前面還可以跟一個變數,通過send()函數給yield傳值,把值保存在yield前邊的變數中
import time def consumer():#有yield,是一個生成器 r="" while True: n=yield r#程式暫停,等待next()信號 # if not n: # return print('consumer <--%s..'%n) time.sleep(1) r='200 ok' def producer(c): next(c)#激活生成器c n=0 while n<5: n=n+1 print('produer-->%s..'%n) cr = c.send(n)#向生成器發送數據 print('consumer return :',cr)
c.close() #生產過程結束,關閉生成器 if __name__ == '__main__': c=consumer() producer(c)
看上面的例子,整個過程沒有鎖的出現,還能保證數據安全,更要命的是還可以控制順序,優雅的實現了併發,甩多線程幾條街
線程叫微進程,而協程又叫微線程。協程擁有自己的寄存器上下文和棧,因此能保留上一次調用的狀態。
2.greenlet模塊
這個模塊封裝了yield,使得程式切換非常方便,但是沒法實現傳值的功能
from greenlet import greenlet def foo(): print('ok1') gr2.switch() print('ok3') gr2.switch() def bar(): print('ok2') gr1.switch() print('ok4') gr1=greenlet(foo) gr2=greenlet(bar) gr1.switch()#啟動
3.gevent模塊
在greenlet模塊的基礎上,開發出了更牛的模塊gevent
gevent為Python提供了更完善的協程支持,其基本原理是:
當一個greenlet遇到IO操作時,就會自動切換到其他的greenlet,等IO操作完成,再切換回來,這樣就保證了總有greenlet在運行,而不是等待
import requests import gevent import time def foo(url): response=requests.get(url) response_str=response.text print('get data %s'%len(response_str)) s=time.time() gevent.joinall([gevent.spawn(foo,"https://itk.org/"), gevent.spawn(foo, "https://www.github.com/"), gevent.spawn(foo, "https://zhihu.com/"),]) # foo("https://itk.org/") # foo("https://www.github.com/") # foo("https://zhihu.com/") print(time.time()-s)
4.協程的優缺點:
優點:
上下文切換消耗小
方便切換控制流,簡化編程模型
高併發,高擴展性,低成本
缺點:
無法利用多核
進行阻塞操作時會阻塞掉整個程式
六、IO模型
我們下麵會比較四種IO模型
1.blocking IO
2.nonblocking IO
3.IO multiplexing
4.asynchronous IO
我們以網路傳輸數據的IO為例,它會涉及到兩個系統對象,一個是調用這個IO 的線程或者進程,另一個是系統內核,而當讀取數據的時候,又會經歷兩個階段:
等待數據準備
將數據從內核態拷貝到用戶態的進程中(因為網路的數據傳輸是靠物理設備實現的,物理設備是硬體,只能有操作系統的內核態才能處理,但是讀數據是程式使用的,所以需要這一步的切換)
1.blocking IO(阻塞IO)
典型的read操作如下圖
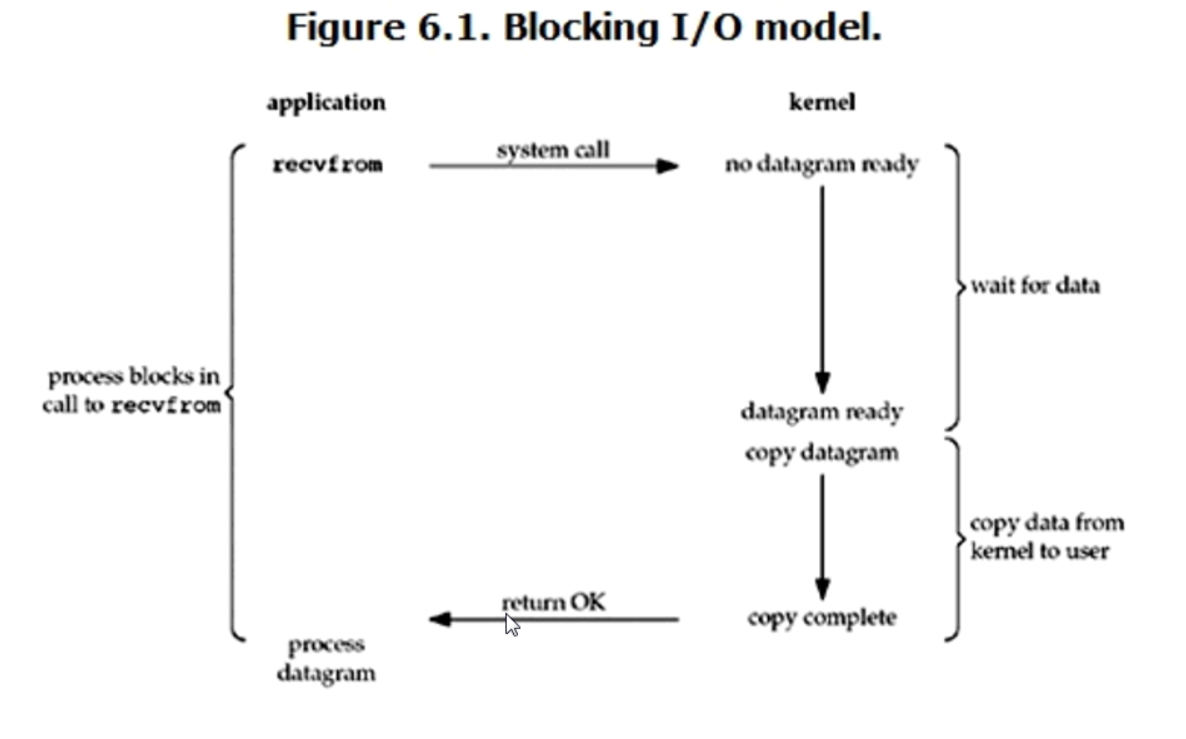
linux下,預設情況的socket都是blocking,回想我們之前用的socket,sock和conn是兩個連接,服務端同時只能監聽一個連接,所以如果服務端在等待客戶端發送消息的時候,其他連接是不能連接到服務端的。
在這種模式下,等待數據和複製數據都需要等待,所以是全程阻塞的
2.nonlocking IO (非阻塞IO)
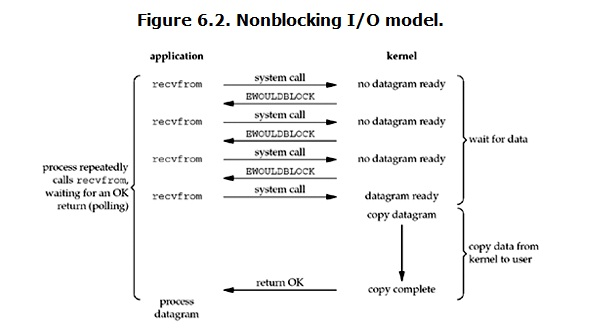
在服務端建立連接之後,加上這個命令,就變成了非阻塞IO模式
這種模式,有數據就取,沒有就報錯,可以加一個異常捕捉。在等待數據的時候不阻塞,但是在copy數據的時候還是會阻塞,
優點是可以把等待連接的這段時間利用上,但是缺點也很明顯:有很多次系統調用,消耗很大;而且當程式去做別的事的時候,數據到了,雖然不會丟失,但是程式收到的數據也不具有實時性
3.IO multiplexing(IO多路復用)

這個比較常用,我們以前用的accept(),有兩個作用:
1.監聽,等待連接
2.建立連接
現在我們用select來替代accept的第一個作用,select的優點在於可以監聽很多對象,無論哪個對象活動,都能做出反應,並將活動的對象收集到一個列表
import socket import select sock=socket.socket() sock.bind(('127.0.0.1',8080)) sock.listen(5) inp=[sock,] while True: r=select.select(inp,[],[]) print('r',r[0]) for obj in r[0]: if obj == sock: conn,addr=obj.accept()
但是建立連接的功能還是accept做,有了這個,我們就可以用併發的方式實現tcp的聊天了
1 # 服務端 2 import socket 3 import time 4 import select 5 6 sock=socket.socket() 7 sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 8 sock.bind(('127.0.0.1',8080)) 9 sock.listen(5) 10 11 inp=[sock,]#監聽套接字對象的列表 12 13 while True: 14 r=select.select(inp,[],[]) 15 print('r',r[0]) 16 for obj in r[0]: 17 if obj == sock: 18 conn,addr=obj.accept() 19 inp.append(conn) 20 else: 21 data=obj.recv(1024) 22 print(data.decode('utf8')) 23 response=input('>>>>:') 24 obj.send(response.encode('utf8'))View Code
只有在建立連接的時候,sock才是活動的,列表中才會有這個對象,如果是在建立連接之後,收發消息的過程中,活動對象就不是sock,而是conn了,所以在實際操作中要判斷列表中的對象是不是sock
在這個模型中,等待數據與copy數據的過程都是阻塞的,所以也叫全程阻塞,與阻塞IO模型相比,這個模型優勢在於處理多個連接
IO 多路復用除了select,還有兩種方式,poll 和 epoll
在windows下只支持select,而在linux中,這三個都有。epoll是最好的,select唯一的優點是多平臺都可以用,但是缺點也很明顯,就是效率很差。poll是epoll和select的中間過渡,與select相比,poll可以監聽的數量沒有限制。epoll沒有最大連接上限,另外監聽機制也完全發生變化,select的機制是輪詢(每個數據都檢查一遍,即使找到有變化的也會繼續檢查),epoll的機制是用回調函數,哪個對象有變化,那個就調用這個回調函數
4. Asynchronous IO (非同步IO)
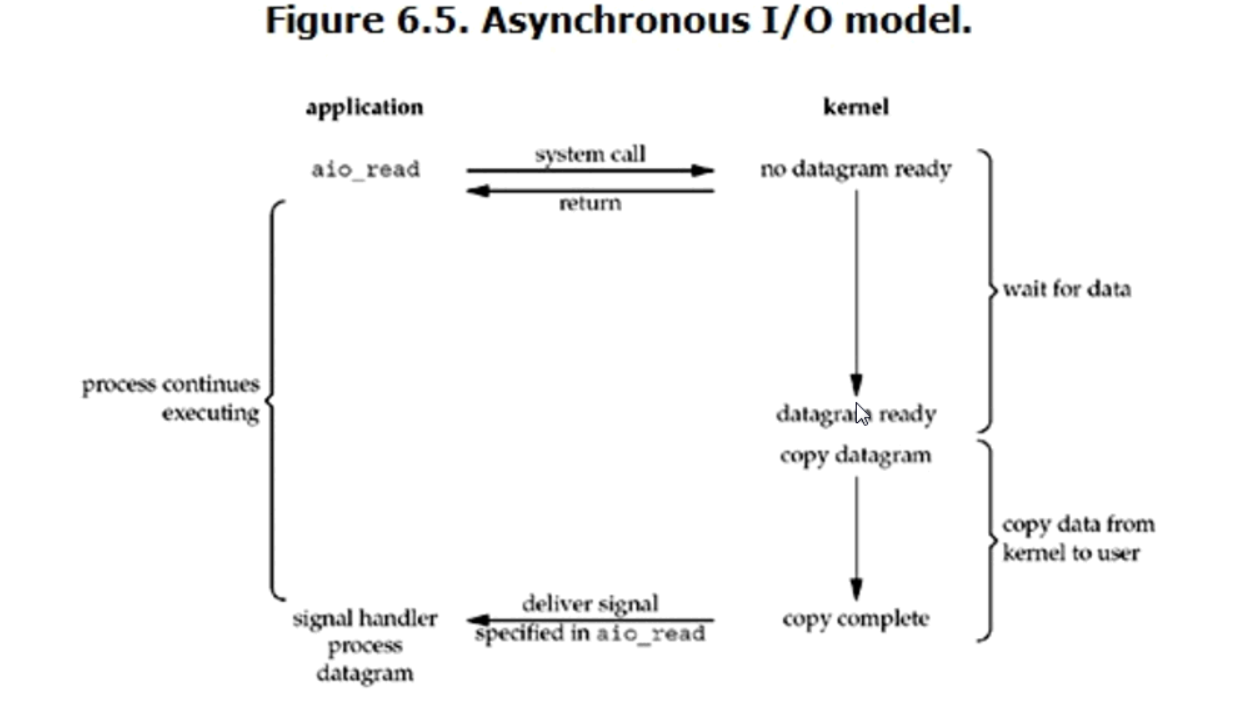
這個模式是全程無阻塞,只有全程無阻塞才能叫非同步,這個模式雖然看起來不錯,但是實際操作起來,如果請求量很大,效率會很低,而且操作系統的任務很重
七、selectors 模塊
學會了這個模塊,就不用在乎用的是select,還是poll,或者是epoll了,他們的介面都是這個模塊。我們只需要知道這個介面怎麼用,它裡面封裝的是什麼,就不用考慮了
在這個模塊中,套接字與函數的綁定是用的一個regesier()的方法,模塊的用法很固定,服務端示例如下:
1 import selectors,socket 2 3 sel=selectors.DefaultSelector() 4 5 sock=socket.socket() 6 sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 7 sock.bind(('127.0.0.1',8080)) 8 sock.listen(5) 9 sock.setblocking(False) 10 11 def read(conn,mask): 12 data=conn.recv(1024) 13 print(data.decode('


