
我們使用資料庫的時候,如果查詢條件太複雜,則會涉及到很多問題 1、無法維護,各種嵌套查詢,各種複雜的查詢,想要優化都無從下手 2、效率低下,一般語句複雜了之後,比如使用or,like %,,%查詢之後資料庫的索引就沒有辦法利用到了,這個時候的搜索就會全表掃描,數據量少的時候可能性能還能接受,但是數據 ...
我們使用資料庫的時候,如果查詢條件太複雜,則會涉及到很多問題
1、無法維護,各種嵌套查詢,各種複雜的查詢,想要優化都無從下手
2、效率低下,一般語句複雜了之後,比如使用or,like %,,%查詢之後資料庫的索引就沒有辦法利用到了,這個時候的搜索就會全表掃描,數據量少的時候可能性能還能接受,但是數據量大了之後性能會直線下降,速度慢的一塌胡蘿蔔。。
但是呢,資料庫的聚集索引查詢還是極快的,
所以我們可以利用這一點嘗試建立一下這樣的索引結構--就是把資料庫裡面的每一條記錄作為一個鍵,相同記錄的Id的集合作為值,這樣我們查詢記錄的時候就可以通過記錄快速定位到數據表的id,從而就可以快速查詢到這條數據瞭如圖所示

如果要搜索咪咪蝦條的話,就可以帶出這些value值,我們都知道key-value的查詢是非常快的,所以這個耗時會很短,然後通過id來查詢就會使得效率高出很多,這個思路可以用在所有欄位上,但是對空間的使用會多一些,不過存儲這東東還是蠻便宜的,畢竟體驗才是最重要的對吧,這種就叫基本的倒排索引。
但是如果用戶只搜索咪咪呢,如何能夠定位到這條咪咪蝦條的記錄呢?
這裡就涉及到了另一項比較重要的技術--中文分詞
這裡簡要說明下中文分詞:
中文分詞裡面有個東西必不可少,就是詞庫
假設我們的詞庫很簡單,就這麼幾條詞:1、咪咪,2、蝦,3、蝦條
這個時候,我們存入一條咪咪蝦條,id是10000的記錄的時候呢
分詞就會這麼乾,先讀第一個字,咪,然後發現沒有單個的這個詞,但是有一個咪咪,然後就會讀取第二個字,第二個字還是咪,這個時候咪咪是一個詞,然後讀取第三個字,蝦,發現蝦是單個的一個字,詞典里也有這個字,咪蝦不存在,咪咪蝦更加不存在,那麼咪咪這個詞就確定了,繼續往下讀,發現條,然後發現蝦是一個詞語,蝦條也是一個詞語,而現在已經讀完了,所以現在分詞有兩種組合,蝦和條,蝦條,顯然第一條有點扯淡,條不能作為一個詞,所以就取後者,這樣蝦條這個詞就出來了。
接著我們存入一條咪咪id 為10002的數據的時候,方法同上
然後存到搜索引擎的數據的就是這樣
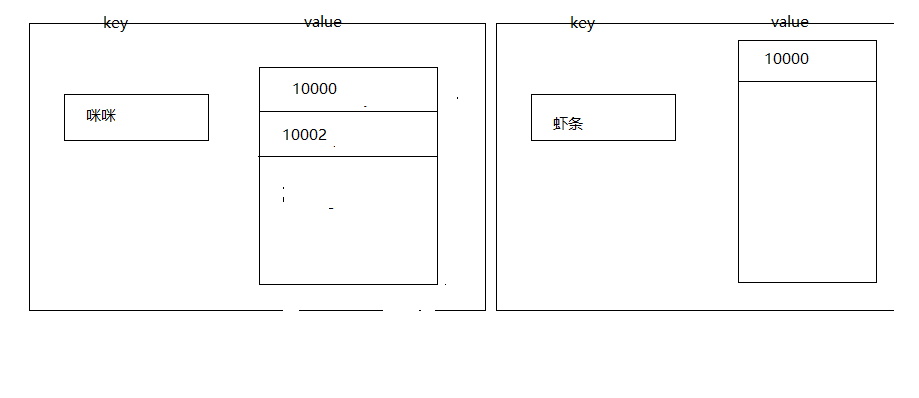
這個時候就有兩條記錄,咪咪對應的有兩條記錄,蝦條對應一條
如果我們搜索蝦條的話,10000就會被搜索出來,如果搜索咪咪的話,那10002和10000就會被搜索出來
如果我們搜索咪咪蝦條的話,就會按照上面的分詞邏輯將我們的搜索條件進行分詞,然後分出來咪咪和蝦條兩個詞,然後查詢,再merge最終得到兩個id:10000,10002
分詞這塊就我所理解也就這樣了。
說了這麼多,具體怎麼做呢?其實很簡單,一個插件就搞定,我用的是IK分詞插件,安裝簡單,地址在這裡,裡面也有安裝說明,安裝完之後重啟下就ok了
https://github.com/medcl/elasticsearch-analysis-ik
中文分詞插件
目前就這麼多,本人也是剛學這個,寫的有什麼問題歡迎指出,謝謝~


