
1. HADOOP背景介紹 1.1 什麼是HADOOP 1. HADOOP是apache旗下的一套開源軟體平臺 2. HADOOP提供的功能:利用伺服器集群,根據用戶的自定義業務邏輯,對海量數據進行分散式處理 3. HADOOP的核心組件有 A. HDFS(分散式文件系統) B. YARN(運算資源 ...
1. HADOOP背景介紹
1.1 什麼是HADOOP
1. HADOOP是apache旗下的一套開源軟體平臺
2. HADOOP提供的功能:利用伺服器集群,根據用戶的自定義業務邏輯,對海量數據進行分散式處理
3. HADOOP的核心組件有
A. HDFS(分散式文件系統)
B. YARN(運算資源調度系統)
C. MAPREDUCE(分散式運算編程框架)
4. 廣義上來說,HADOOP通常是指一個更廣泛的概念——HADOOP生態圈
1.2 HADOOP產生背景
1. HADOOP最早起源於Nutch。Nutch的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存儲和索引問題。
2. 2003年、2004年谷歌發表的兩篇論文為該問題提供了可行的解決方案。
——分散式文件系統(GFS),可用於處理海量網頁的存儲
——分散式計算框架MAPREDUCE,可用於處理海量網頁的索引計算問題。
3. Nutch的開發人員完成了相應的開源實現HDFS和MAPREDUCE,並從Nutch中剝離成為獨立項目HADOOP,到2008年1月,HADOOP成為Apache頂級項目,迎來了它的快速發展期。
1.3 HADOOP在大數據、雲計算中的位置和關係
1. 雲計算是分散式計算、並行計算、網格計算、多核計算、網路存儲、虛擬化、負載均衡等傳統電腦技術和互聯網技術融合發展的產物。藉助IaaS(基礎設施即服務)、PaaS(平臺即服務)、SaaS(軟體即服務)等業務模式,把強大的計算能力提供給終端用戶。
2. 現階段,雲計算的兩大底層支撐技術為“虛擬化”和“大數據技術”
3. 而HADOOP則是雲計算的PaaS層的解決方案之一,並不等同於PaaS,更不等同於雲計算本身。
1.4 國內外HADOOP應用案例介紹
1、HADOOP應用於數據服務基礎平臺建設
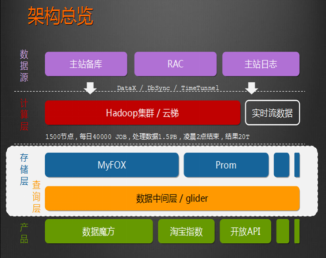
2/HADOOP用於用戶畫像

3、HADOOP用於網站點擊流日誌數據挖掘
1.5 國內HADOOP的就業情況分析
1、 HADOOP就業整體情況
A. 大數據產業已納入國家十三五規劃
B. 各大城市都在進行智慧城市項目建設,而智慧城市的根基就是大數據綜合平臺
C. 互聯網時代數據的種類,增長都呈現爆髮式增長,各行業對數據的價值日益重視
D. 相對於傳統JAVAEE技術領域來說,大數據領域的人才相對稀缺
E. 隨著現代社會的發展,數據處理和數據挖掘的重要性只會增不會減,因此,大數據技術是一個尚在蓬勃發展且具有長遠前景的領域
2、 HADOOP就業職位要求
大數據是個複合專業,包括應用開發、軟體平臺、演算法、數據挖掘等,因此,大數據技術領域的就業選擇是多樣的,但就HADOOP而言,通常都需要具備以下技能或知識:
A. HADOOP分散式集群的平臺搭建
B. HADOOP分散式文件系統HDFS的原理理解及使用
C. HADOOP分散式運算框架MAPREDUCE的原理理解及編程
D. Hive數據倉庫工具的熟練應用
E. Flume、sqoop、oozie等輔助工具的熟練使用
F. Shell/python等腳本語言的開發能力
3、 HADOOP相關職位的薪資水平
大數據技術或具體到HADOOP的就業需求目前主要集中在北上廣深一線城市,薪資待遇普遍高於傳統JAVAEE開發人員,以北京為例:

1.6 HADOOP生態圈以及各組成部分的簡介
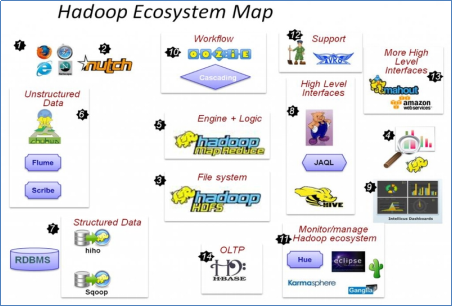
各組件簡介
重點組件:
HDFS:分散式文件系統
MAPREDUCE:分散式運算程式開發框架
HIVE:基於大數據技術(文件系統+運算框架)的SQL數據倉庫工具
HBASE:基於HADOOP的分散式海量資料庫
ZOOKEEPER:分散式協調服務基礎組件
Mahout:基於mapreduce/spark/flink等分散式運算框架的機器學習演算法庫
Oozie:工作流調度框架
Sqoop:數據導入導出工具
Flume:日誌數據採集框架

