
截止目前,筆者在博客園上面已經發表了3篇關於網路下載的文章,這三篇博客實現了基於socket的http多線程遠程斷點下載實用程式。筆者打算在此基礎上開發出一款分散式文件管理實用程式,截止目前,已經實現了 服務端/客戶端 的上傳、下載部分的功能邏輯。涉及到的知識點包括線程池技術、linux epoll... ...
一 前言
截止目前,筆者在博客園上面已經發表了3篇關於網路下載的文章,這三篇博客實現了基於socket的http多線程遠程斷點下載實用程式。筆者打算在此基礎上開發出一款分散式文件管理實用程式,截止目前,已經實現了 服務端/客戶端 的上傳、下載部分的功能邏輯。涉及到的知識點包括線程池技術、linux epoll併發技術、上傳、下載等。JDFS的下載功能的邏輯部分與筆者前幾篇關於JWebFileTrans(JDownload)比較類似。如果讀者對socket網路下載不熟悉或者是只對下載功能感興趣,請移步筆者的另外三篇博客,本文對下載功能不會詳細描述,將主要集中於線程池、epoll和上傳。那三篇博客的地址為:
- JWebFileTrans: 一款可以從網路上下載文件的小程式(一) 鏈接地址請點我
- JWebFileTrans(JDownload): 一款可以從網路上下載文件的小程式(二) 鏈接地址請點我
- JWebFileTrans(JDownload): 一款可以從網路上下載文件的小程式(三),多線程斷點下載 鏈接地址請點我
JDFS的github地址請點擊我
PS: 本篇博客是博客園用戶“cs小學生”的原創作品,轉載請註明原作者和原文鏈接,謝謝。
按照管理,下一節將先展示一下JDFS的上傳下載功能。
二 JDFS上傳、下載功能展示
筆者是在兩台虛擬的Ubuntu上做的測試,使用的是vmware player安裝的ubuntu linux系統。在做實驗之前我們需要首先確保兩台虛擬Ubuntu之間的網路是通的,使用ping命令就可以檢測之,筆者檢測的截圖如下:

如上圖所示,登錄Ubuntu系統後現在shell裡面執行ifconfig命令來查看本機的ip是多少,圖中的藍色線標識的便分別是兩者的ip地址。

如上圖所示,兩個虛擬ubuntu互相ping,結果顯示網路是通的,那麼這個是本實驗的基礎。

如上圖所示是實驗之前server端、client端的目錄情況,左邊的是server端,目錄里有一本《Unix環境高級編程》英文版,這個當時候客戶端會請求下載這本電子書。右邊的是client端的目錄情況,其中有一本《演算法導論》英文版,實驗的時候,客戶端會請求向服務端上傳這本電子書。
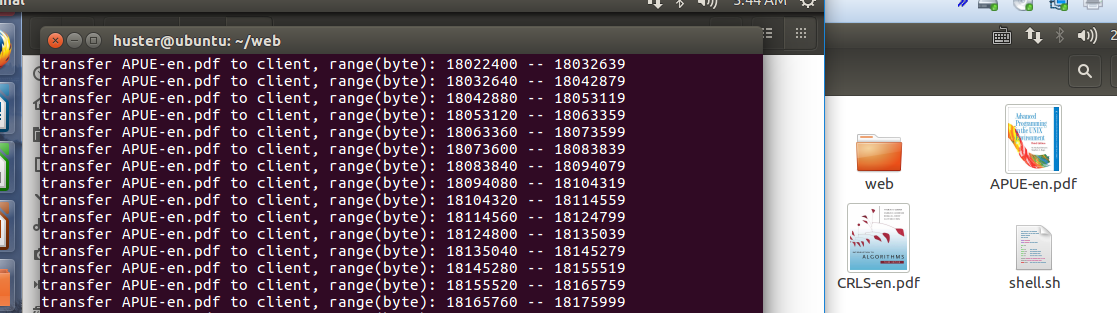
如上圖所示,是客戶端向服務端請求下載APUE-en.pdf的過程截圖,左邊是服務端,從shell的列印信息可以看出server在分段向client傳送電子書,右邊是客戶端下載完畢後的截圖。可以看出原本客戶端目錄中只有演算法導論一本書,現在多了一本unix環境高級編程這本書。
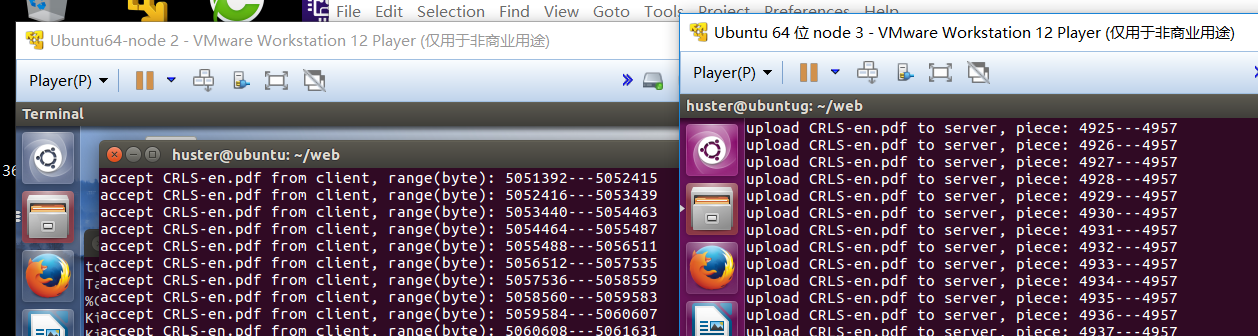
上圖所示的是客戶端請求向服務端上傳演算法導論電子書的截圖。右邊是客戶端上傳過程中列印的信息,可以看出是分片上傳的,而左邊是服務端接收過程中shell列印的信息。
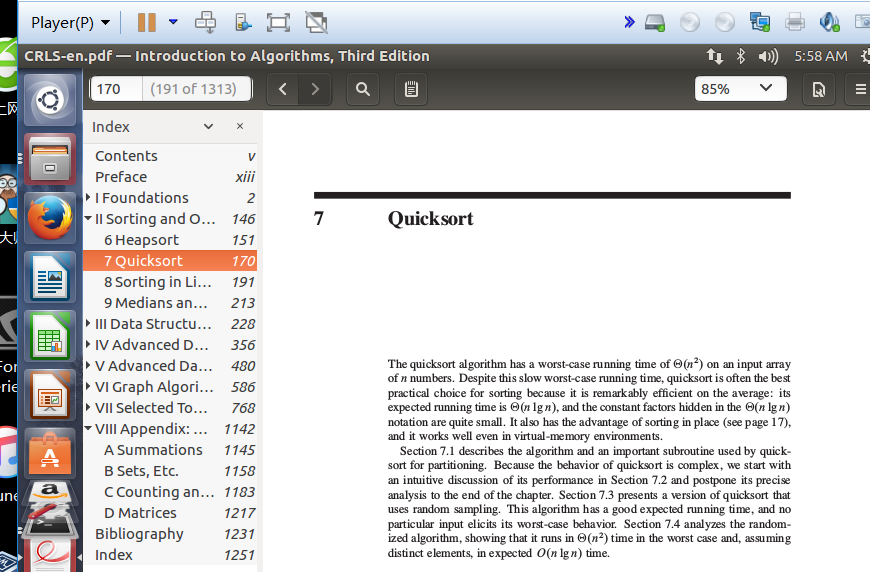
上圖是客戶端上傳演算法導論完畢後,在server端的ubuntu系統中打開演算法導論的截圖,可以看出,上傳過程正確,電子書可以正常打開瀏覽。
三 基本思路
本文是在前言中的三篇博客的基礎上構思出來的,而且JDFS的客戶端部分下載功能的邏輯與JWebFileTrans(JDownload)幾乎一模一樣,在後續的詳細介紹部分將不會客戶端的下載功能做過多介紹,主要集中在上傳功能、epoll和線程池部分。因此如果讀者之前沒有閱讀過JWebFileTrans(JDownload)相關的博客,請先到前言部分閱讀之,否則在閱讀本文的過程中可能會碰到一些障礙。
本文的核心部分是上傳、下載,需要在服務端、客戶端分別實現對應的邏輯,客戶端與服務端遵循相同的協議,或者換句話說,服務端需要與客戶端約定好一些規則,然後客戶端按照規則發送請求,服務端按照規則響應請求。比如我們定義一個數據結構,裡面包含了[請求類型,文件起始位置,文件名等]。服務端接收到客戶端的數據後,先把數據的頭部按照事先定義好的數據結構來解析之,如果請求類型是上傳,則做好接收頭部描述的起始位置的那段數據,並寫入到磁碟文件。如果請求類型是下載,則根據文件名在服務端的目錄里查找該文件,若找到則將對應區段的文件內容發送給客戶端。發送、接收分別是通過send() recv()函數來實現的。
那麼服務端需要一直在特定的[ip,埠]上監聽,服務端的邏輯怎麼實現呢?大部分人會想到用一個while死迴圈來一直監聽,網上也有相當多的一部分博客也是這麼描述的。這樣做的缺點是服務端cpu資源占用率較高,甚至可能接近100%cpu占用率。也就是說大部分情況下cpu被浪費了,即使沒有客戶端連接。
在linux中有一種高效的實現服務端併發的方案:epoll,使用epoll後,當沒有客戶端連接請求的時候,用top命令可以看到服務端程式甚至沒有顯示,這是因為被內核掛起了,一旦有客戶端的下載請求,在筆者的實驗過程中發現cpu占用率基本在5%左右。可見cpu被很好的利用而沒有浪費。有請求則服務,沒請求則被內核掛起,一點都不會浪費系統資源。而epoll又分為水平觸發和邊緣觸發,邊緣觸發需要服務端使用非同步IO,邏輯稍微複雜點,而水平觸發可以使用非同步也可以使用非非同步。關於水平觸發、邊緣觸發的概念,請讀者自行在網上搜索相關技術博客,此文不在對此贅述,而是集中於JDFS的業務邏輯部分。
那麼使用epoll的話還有一個問題,客戶端每來一個請求怎麼辦,是服務端親自處理嗎,如果是的話,那麼假設同一時間有100個客戶端請求,那豈不是服務端挨個滿足服務請求,這就變成了串列處理了,效率肯定不高,畢竟epoll是專門為服務端大規模併發處理而生的。所以,使用pthread?每來一個請求就創建一個線程來服務之,這樣就可以達到服務端並行處理的目的。但是問題是,假設有100萬個請求,難道要創建100萬個線程?且不說系統所支持創建的線程數目是否有上限,光是這麼多的線程的創建和銷毀就要銷毀大量系統資源。那麼除此之外還有什麼辦法呢?沒錯,就是線程池。
線程池可以形象的理解為一個池塘,這個池塘中有一定數量的事先創建好的線程,池塘裡面還有一個隊列,這個隊列是專門存儲客戶端請求數據用的。線程不斷地從隊列中取任務並執行之。
綜上,本文服務端的模型是使用epoll來監聽客戶端的請求,一旦有請求,並不執行,而是將該請求加入到線程池的作業隊列中,然後服務端繼續監聽客戶端的請求,而完全不用關心線程池如何滿足客戶端請求,也不會被線程池阻塞。這樣服務端主要邏輯負責監聽,而線程池負責執行的邏輯便躍然紙上。
四 JDFS個部件詳細介紹
1. 線程池
在前文我們提到線程池的時候說了兩個關鍵詞:線程池、作業隊列。那麼我們首先來定義一下數據結構,筆者本科時清晰的記得課本中有句名言:數據結構+演算法=程式,由此可見數據結構的重要性。作業隊列是一個鏈表,每一個鏈表節點存儲的是客戶端的請求,我們在此稱之為一個Job吧,這個Job要做什麼事情只有服務端知道,服務端當初接收到客戶端的請求後,會創建一個Job節點插入線程池的作業隊列中,併在節點中記錄要做的事情,也就是傳進來一個函數指針。線程池中的線程直接每服務一個Job節點,便調用對應的函數指針,像這種通過函數指針的方式來調用函數的做法就是回調函數。說到這,我們大致可猜出一個Job節點要記錄:回調函數、回調函數的參數、指向下一個Job節點的指針:
1 typedef struct job 2 { 3 void * (*call_back_func)(void *arg); 4 void *arg; 5 int job_kind; 6 struct job *next; 7 }job;
相應的作業隊列數據結構的定義如下:
1 typedef struct task_queue 2 { 3 int is_queue_alive; 4 int max_num_of_jobs_of_this_task_queue; 5 int current_num_of_jobs_of_this_task_queue; 6 job *task_queue_head; 7 job *task_queue_tail; 8 9 pthread_cond_t task_queue_empty; 10 pthread_cond_t task_queue_not_empty; 11 pthread_cond_t task_queue_not_full; 12 13 }task_queue;
這其中有三個condition變數,task_queue_empty:銷毀線程池的函數會在該變數上等待,只有作業隊列空的時候才可以銷毀線程池。task_queue_not_empty: 從作業隊列取數據的函數可能會在該變數上等待,只有作業隊列不空的時候才可以從中取Job. task_queue_not_full:服務端在接收到客戶端的請求後,會把該請求打包放入線程池中的作業隊列中,但是只有隊列不滿的時候才可以加入,如果滿則服務端會在該變數上面阻塞直到隊列不滿的時候被喚醒。
線程池的數據結構定義如下:
1 typedef struct threadpool 2 { 3 int thread_num; 4 pthread_t *thread_id_array; 5 int is_threadpool_alive; 6 7 pthread_mutex_t mutex_of_threadpool; 8 task_queue tq; 9 10 }threadpool;
因為本數據結構的欄位都是根據其功能命名的,很好理解,其中有一個mutex變數,這個mutex是保護整個線程池的,不論是從線程池中取數據還是往線程池中添加數據都需要首先對線程池的mutex加鎖,然後再做相應的操作。另外作業隊列中有一個表明作業隊列當前是否還活著的變數:is_queue_alive,同樣線程池中有一個表明線程池是否還活著的變數:is_threadpool_alive. 它們的功能是這樣的:
- 往線程池中的作業隊列添加作業:只有線程池活著才可以添加作業
- 從線程池中取作業:只有作業隊列還活著,才可以從中取作業。
- 銷毀線程池:只有線程池和作業隊列都不處於活著的狀態時才可以銷毀。
需要指出的是:當線程池被設置為not alive的時候,此時作業隊列中可能仍然有作業,因此需要等待作業隊列中的作業都被執行完畢的時候,把作業隊列設置為not alive,此時才可以銷毀線程池。
線上程池中大量使用了pthread_cond_wait()和pthread_cond_broadcast()函數。在這兩個函數的使用過程中需要註意一點,應該這樣使用:
pthread_mutex_lock();
while(condition is not ok){ ........... pthread_cond_wait(); ........... }
沒錯,一定要用while迴圈,為什麼呢?筆者曾在網上搜索了大量關於這個問題的解答,但是感覺大部分說的不是太清楚。但是至少有一種理由支持我們關於while的用法。我們假設condition是線程等待隊列不滿,從而可以添加作業到隊列中。如果不用while迴圈而是僅僅用if判斷如果隊列不滿的狀態不滿足,pthread_cond_wait函數會首先unlock mutex然後進入睡眠等待條件滿足是被喚醒(關於pthread_cond_wait()內部的加鎖解鎖,請讀者自行查閱相關資料).unlock mutex後,其他線程就會同樣成功加鎖,然後進入等待。假設共有N個這樣的線程等待該條件變數。再假設這時候有一個從作業隊列中取作業的線程取走了一個作業,導致作業隊列恰好有一個空位出來,這時候該線程會調用pthread_cond_broadcast()喚醒所有等待該條件變數的線程。這個時候N個線程同時被喚醒,pthread_cond_wait()內部會再次加鎖,這時候只有一個線程成功加鎖,然後往作業隊列中添加一個作業,這時候作業隊列又滿了,緊接著該線程釋放muex,其他N-1個線程中會有一個線程再次有機會獲得鎖,並且從pthread_cond_wait()中返回。如果是if判斷語句,該線程就以為隊列已經不滿可以添加作業了(實際上作業隊列再一次滿了),而如果用while迴圈,則會再一次判斷作業隊列是處於滿的狀態,於是再一次調用pthread_cond_wait()進行睡眠。
以上便是線程池背景相關知識的介紹。線程池定義了一組函數介面,如下:
1 int threadpool_create(threadpool *pool, int num_of_thread, int max_num_of_jobs_of_one_task_queue); 2 int threadpool_add_jobs_to_taskqueue(threadpool *pool, void * (*call_back_func)(void *arg), void *arg, int job_kind); 3 int destory_threadpool(threadpool *pool); 4 5 void *thread_func(void *arg); 6 int threadpool_fetch_jobs_from_taskqueue(threadpool *pool, job **job_fetched);
前三個介面是外部介面,供調用者:創建線程池、添加作業到線程池的作業隊列中、任務完成後銷毀線程池。後面兩個函數是內部介面,僅供線程池內部使用,線程池在創建的時候就會啟動N個線程,這N個線程都會執行thread_func()函數,在該函數內部,線程會不斷調用threadpool_fetch_jobs_from_taskqueue()來獲取作業,並執行之。
以上便是線程池主要邏輯,關於邏輯細節,請讀者移步筆者的github代碼。
2 下載功能
2.1 客戶端下載功能
在JDFS中,客戶端的下載功能和筆者前幾篇關於JWebFileTrans的邏輯幾乎一樣,只有些許差異,這個差異主要體現在協議上。在一個遵循Http協議標準的下載程式里,程式通過GET命令向服務端發送請求,而服務端會根據http協議解析客戶端的請求,根據解析結果來執行之,比如解析的結果是客戶端請求文件A的第n到第m個位元組,則發送[n,m]區段的A文件內容給客戶端。而在JDFS中,客戶端、服務端都是筆者自己設計,為了簡化編程,我們不使用http協議,而是自己定義一套規則,並按照這個規則來執行。簡言之,這個規則其實是用一個數據結構來表示的:
1 typedef struct http_request_buffer 2 { 3 int request_kind; 4 long num1; 5 long num2; 6 char file_name[100]; 7 }http_request_buffer;
其中request_kind表示請求類型:0表示查詢文件長度,服務端接收到此種請求會把文件的大小寫入到num1欄位,然後調用send函數返回給客戶端。1表示客戶端要上傳文件到服務端,num1,num2表示上傳的是文件file_name的第num1到第num2個位元組,此時服務端就要調用recv來接收客戶端的數據,並寫入到本地磁碟中。2表示下載,即客戶端請求下載文件file_name的第num1到第num2個位元組的數據。
以上便是客戶端下載邏輯與JWebFileTrans的不同之處,僅僅是遵從的規則發生了變化而已,下載功能的業務邏輯基本是沒有變化的,讀者可以參考前言中列出的那幾篇博客,此處不再贅述。
2.2 服務端下載功能
下麵是服務端的下載功能的邏輯部分,這是一個回調函數,服務端再接收到請求後添加到作業隊列,線程池中的線程會調用該回調函數來滿足客戶端的下載請求。服務端採用的是epoll,會在後續部分介紹。
1 void *Http_server_callback_download(void *arg){ 2 3 callback_arg_download *cb_arg_download=(callback_arg_download *)arg; 4 char *file_name=cb_arg_download->file_name; 5 int client_socket_fd=cb_arg_download->socket_fd; 6 long range_begin=cb_arg_download->range_begin; 7 long range_end=cb_arg_download->range_end; 8 unsigned char *server_buffer=cb_arg_download->server_buffer; 9 FILE *fp=fopen(file_name, "r"); 10 if(fp==NULL){ 11 perror("Http_server_callback_download,fopen\n"); 12 close(client_socket_fd); 13 return (void *)1; 14 } 15 16 17 http_request_buffer *hrb=(http_request_buffer *)server_buffer; 18 hrb->num1=range_begin; 19 hrb->num2=range_end; 20 21 fseek(fp, range_begin, SEEK_SET); 22 long http_request_buffer_len=sizeof(http_request_buffer); 23 memcpy(server_buffer+http_request_buffer_len,"JDFS",4); 24 25 fread(server_buffer+http_request_buffer_len+4, range_end-range_begin+1, 1, fp); 26 int send_num=0; 27 int ret=send(client_socket_fd,server_buffer+send_num,http_request_buffer_len+4+range_end-range_begin+1-send_num,0); 28 if(ret==-1){ 29 perror("Http_server_body,send"); 30 close(client_socket_fd); 31 } 32 33 if(fclose(fp)!=0){ 34 perror("Http_server_callback_download,fclose"); 35 } 36 }
以上便是服務端下載功能的回調函數,由於筆者對函數名和變數名嚴格按照功能來取名的,因此代碼很直觀,很容易理解。需要註意的是結尾處的flcose(fp),這個很重要,回調函數會被調用很多次,如果不在結尾處關閉文件描述符,會出現打開文件太多的錯誤提示。
3 上傳功能
3.1 客戶端上傳功能
下麵是客戶端下載功能的部分邏輯
1 for(int i=0;i<upload_loop_num;i++){ 2 3 printf("upload %s to server, piece: %d---%d\n",file_name, i,upload_loop_num); 4 5 long offset=i*upload_one_piece_size; 6 fseek(fp, offset, SEEK_SET); 7 hrb->num1=offset; 8 hrb->num2=offset+upload_one_piece_size-1; 9 10 int ret=fread(upload_buffer+sizeof(http_request_buffer)+4, upload_one_piece_size, 1, fp); 11 if(ret!=1){ 12 printf("JDFS_http_upload,fread failed\n"); 13 exit(0); 14 } 15 16 while(1){ 17 int ret=send(socket_fd, upload_buffer, upload_buffer_len+4, 0); 18 if(ret==(upload_buffer_len+4)){ 19 break; 20 }else{ 21 int ret=close(socket_fd); 22 if(ret==0){ 23 Http_connect_to_server(server_ip, server_port, &socket_fd); 24 continue; 25 }else{ 26 perror("JDFS_http_upload, close"); 27 exit(0); 28 } 29 } 30 } 31 32 }
3.2 服務端上傳功能
下麵是服務端上傳功能的代碼,該處代碼與下載功能不同之處在於此處並不是回調函數,而是服務端主程式自己來處理,為什麼不是線程池調回調函數呢?這源於服務端當初設計的一個缺陷,原因後面會講。
1 else if(hrb->request_kind==1){ 2 printf("accept %s from client, range(byte): %ld---%ld\n",hrb->file_name,hrb->num1,hrb->num2); 3 FILE *fp=NULL; 4 char *file_name=hrb->file_name; 5 if(hrb->num1==0){ 6 fp=fopen(file_name, "w+"); 7 }else{ 8 fp=fopen(file_name,"r+"); 9 } 10 11 12 if(fp==NULL){ 13 perror("Http_server_body,fopen"); 14 close(client_socket_fd); 15 }else{ 16 17 long offset=hrb->num1; 18 fseek(fp, offset, SEEK_SET); 19 20 int ret=fwrite(server_buffer+sizeof(http_request_buffer)+4, hrb->num2-hrb->num1+1, 1, fp); 21 if(ret!=1){ 22 close(client_socket_fd); 23 } 24 } 25 26 fclose(fp); 27 28 }else if(hrb->request_kind==2){
3.3 上傳功能的缺陷
當前JDFS的上傳功能是有缺陷的,原因主要在於服務端,當初筆者調試上傳功能的時候,老是失敗,在不斷減小客戶端調用send()函數一次發送的數據量的過程中,當數據量小到一定的程度時,上傳就成功了。分析原因在於:當客戶端發送數據量較大的時候,比如客戶端發送了一段字元“header華中科技大學的電腦專業是全國十強”這句話的時候,服務端是調用recv()來接收數據的,由於網路的原因並不保證一次就能接收完畢,假設分兩次傳送完畢,服務端接收到的數據有可能是這樣的:“header華中科技大學的電腦” “專業是全國十強”。這樣就會引發錯誤,這時候服務端每次調用recv()函數的時候必須判斷該段數據是否真的接收完畢,如果不這樣做,就有可能把"專業是全國十強”這段數據當成是客戶端另一個完整的send()調用發送過來的數據,於是把前幾個位元組當做header來解析,而實際上這段文字只是客戶端上次send()的數據的一部分。
除此之外,服務端的設計也導致了上傳功能無法使用線程池來並行處理,具體原因參見下一節。
4 基於epoll的服務端框架
前面說過,服務端設計的時候最直觀的就是用一個while迴圈不斷查詢是否有客戶端連接過來。這樣導致效率不高,而針對服務端大併發,linux提供了epoll來支持。什麼是epoll呢?網上有大量詳細的文章介紹,這裡為了方便讀者理解,我們可以這樣簡要的理解:epoll就是當有數據請求的時候才會激活服務端來處理,其他時間都會使得服務端處於睡眠狀態,不占用系統資源。當然epoll的功能遠不止筆者的描述,這裡描述的只是其中的一個點而已。關於epoll筆者也是用到的時候現學的。
epoll主要有三個函數介面:epoll_create()創建一個epoll並返回對應的epoll描述符,epoll_ctl()主要是添加一些感興趣的事件,比如對socket監聽描述符fd上的數據輸入感興趣。epoll_wait():一旦感興趣的那個文件描述符(比如socket監聽描述符)上有感興趣的事情(數據讀、數據寫),則返回這些事情的個數,並可以根據這個‘個數’來遍歷epoll_wait()的第二個參數,來獲取具體的請求(比如客戶端連接請求、客戶端有數據發送)。關於這三個函數的具體使用也請讀者自行查閱相關資料,此處不再贅述。
JDFS服務端的epoll框架部分縮略版代碼如下:
1 int epoll_fd=epoll_create(20); 2 if(epoll_fd==-1){ 3 perror("Http_server_body,epoll_create"); 4 exit(0); 5 } 6 7 int ret=epoll_ctl(epoll_fd,EPOLL_CTL_ADD,*server_listen_fd,&event_for_epoll_ctl); 8 if(ret==-1){ 9 perror("Http_server_body,epoll_ctl"); 10 exit(0); 11 } 12 13 int num_of_events_to_happen=0; 14 while(1){ 15 16 num_of_events_to_happen=epoll_wait(epoll_fd,event_for_epoll_wait,event_for_epoll_wait_num,-1); 17 if(num_of_events_to_happen==-1){ 18 perror("Http_server_body,epoll_wait"); 19 exit(0); 20 } 21 22 for(int i=0;i<num_of_events_to_happen;i++){ 23 struct sockaddr_in client_socket; 24 int client_socket_len=sizeof(client_socket); 25 if(*server_listen_fd==event_for_epoll_wait[i].data.fd){ 26 int client_socket_fd=accept(*server_listen_fd,(struct sockaddr *)&client_socket,&client_socket_len); 27 if(client_socket_fd==-1){ 28 continue; 29 } 30 31 event_for_epoll_ctl.data.fd=client_socket_fd; 32 event_for_epoll_ctl.events=EPOLLIN; 33 34 epoll_ctl(epoll_fd,EPOLL_CTL_ADD,client_socket_fd,&event_for_epoll_ctl); 35 36 }else if(event_for_epoll_wait[i].events & EPOLLIN){ 37 int client_socket_fd=event_for_epoll_wait[i].data.fd; 38 if(client_socket_fd<0){ 39 continue; 40 } 41 42 memset(server_buffer,0,sizeof(server_buffer)); 43 int ret=recv(client_socket_fd,server_buffer,sizeof(http_request_buffer)+4+upload_one_piece_size,0); 44 if(ret<=0){ 45 close(client_socket_fd); 46 continue; 47 } 48 49 http_request_buffer *hrb=(http_request_buffer *)server_buffer; 50 51 if(hrb->request_kind==0){ 52 53 54 55 }else if(hrb->request_kind==1){ 56 57 58 }else if(hrb->request_kind==2){ 59 60 61 }else{ 62 63 } 64 65 66 } 67 } 68 69 }
如上述代碼,在用epoll註冊完感興趣的事情後,接著就是一個while迴圈來檢測是否有新的客戶端請求。epoll_wait返回的就是當前請求的個數,接著便是一個for迴圈挨個遍歷這些請求。在for迴圈裡面最外層的if-else語句,首先判斷是不是有新的客戶端請求,如果是的話,則調用accept接收之,然後緊接著把這個客戶端連接的socket fd加入到epoll中,並設置為對此socket fd的數據輸入感興趣。在else分支里,如果是有數據待讀入,則調用recv()函數接收之,並解析讀到的數據頭,根據hrb->request_kind來分別處理。如果hrb->request_kind=0,2則代表著客戶端分別有查詢、下載請求,因此將該請求加入線程池,如果該值是1,則表示客戶端有數據上傳,因為此處的邏輯是先recv(),再解析頭部,然後分別處理,所以一旦是上傳數據請求,那麼此處的recv()函數已經接收了客戶端的上傳數據,無法再將該請求加入線程池,來並行處理。因為服務端主程式已經做了recv操作,這正是前文提到的由於服務端框架的設計導致了上傳數據無法並行處理。
在下一篇博客中,將對JDFS進行改進,一方面使得上傳部分也能並行處理,另一方面修改服務端上傳部分的邏輯,使得無論一次客戶端send()的數據有多大,服務端上傳功能都能夠正確接收數據。
五 結束語
至此本文就結束了,總結來說,本文基於socket實現了一個具有上傳、下載功能的實用程式。後續會繼續完善JDFS,期望最終開發出一個分散式文件管理實用程式。
聯繫方式:https://github.com/junhuster/


