
logstash是一個強大的分析後端日誌的開源軟體,本文詳細介紹了logstash的配置和圖表使用,通過對訪問日誌的分析,能夠抓取用戶的地域分佈、使用的終端、感興趣的功能,介面的訪問時間排序,或者是異常檢測等等,而這些可以通過圖表的方式很直觀地展示出來,還可以進行關聯操作。
logstash是一個數據分析軟體,主要目的是分析log日誌。整一套軟體可以當作一個MVC模型,logstash是controller層,Elasticsearch是一個model層,kibana是view層。
首先將數據傳給logstash,它將數據進行過濾和格式化(轉成JSON格式),然後傳給Elasticsearch進行存儲、建搜索的索引,kibana提供前端的頁面再進行搜索和圖表可視化,它是調用Elasticsearch的介面返回的數據進行可視化。logstash和Elasticsearch是用Java寫的,kibana使用node.js框架。
這個軟體官網有很詳細的使用說明,https://www.elastic.co/,除了docs之外,還有視頻教程。這篇博客集合了docs和視頻裡面一些比較重要的設置和使用。
一、logstash的配置
1. 定義數據源
寫一個配置文件,可命名為logstash.conf,輸入以下內容:
input { file { path => "/data/web/logstash/logFile/*/*" start_position => "beginning" #從文件開始處讀寫 } # stdin {} #可以從標準輸入讀數據 }
定義的數據源,支持從文件、stdin、kafka、twitter等來源,甚至可以自己寫一個input plugin。如果像上面那樣用通配符寫file,如果有新日誌文件拷進來,它會自動去掃描。
2. 定義數據的格式
根據打日誌的格式,用正則表達式進行匹配
filter { #定義數據的格式 grok { match => { "message" => "%{DATA:timestamp}\|%{IP:serverIp}\|%{IP:clientIp}\|%{DATA:logSource}\|%{DATA:userId}\|%{DATA:reqUrl}\|%{DATA:reqUri}\|%{DATA:refer}\|%{DATA:device}\|%{DATA:textDuring}\|%{DATA:duringTime:int}\|\|"} } }
由於打日誌的格式是這樣的:
2015-05-07-16:03:04|10.4.29.158|120.131.74.116|WEB|11299073|http://quxue.renren.com/shareApp?isappinstalled=0&userId=11299073&from=groupmessage|/shareApp|null|Mozilla/5.0 (iPhone; CPU iPhone OS 8_2 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Mobile/12D508 MicroMessenger/6.1.5 NetType/WIFI|duringTime|98||
以|符號隔開,第一個是訪問時間,timestamp,作為logstash的時間戳,接下來的依次為:服務端IP,客戶端的IP,機器類型(WEB/APP/ADMIN),用戶的ID(沒有用0表示),請求的完整網址,請求的控制器路徑,reference,設備的信息,duringTime,請求所花的時間。
如上面代碼,依次定義欄位,用一個正則表達式進行匹配,DATA是logstash定義好的正則,其實就是(.*?),並且定義欄位名。
我們將訪問時間作為logstash的時間戳,有了這個,我們就可以以時間為區分,查看分析某段時間的請求是怎樣的,如果沒有匹配到這個時間的話,logstash將以當前時間作為該條記錄的時間戳。需要再filter裡面定義時間戳的格式,即打日誌用的格式:
filter { #定義數據的格式 grok {#同上... } #定義時間戳的格式 date { match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ] locale => "cn" } }
在上面的欄位裡面需要跟logstash指出哪個是客戶端IP,logstash會自動去抓取該IP的相關位置信息:
filter { #定義數據的格式 grok {#同上} #定義時間戳的格式 date {#同上} #定義客戶端的IP是哪個欄位(上面定義的數據格式) geoip { source => "clientIp" }
}
同樣地還有客戶端的UA,由於UA的格式比較多,logstash也會自動去分析,提取操作系統等相關信息
#定義客戶端設備是哪一個欄位 useragent { source => "device" target => "userDevice" }
哪些欄位是整型的,也需要告訴logstash,為了後面分析時可進行排序,使用的數據裡面只有一個時間
#需要進行轉換的欄位,這裡是將訪問的時間轉成int,再傳給Elasticsearch mutate { convert => ["duringTime", "integer"] }
3. 輸出配置
最後就是輸出的配置,將過濾扣的數據輸出到elasticsearch
output { #將輸出保存到elasticsearch,如果沒有匹配到時間就不保存,因為日誌里的網址參數有些帶有換行 if [timestamp] =~ /^\d{4}-\d{2}-\d{2}/ { elasticsearch { host => localhost } } #輸出到stdout # stdout { codec => rubydebug } #定義訪問數據的用戶名和密碼 # user => webService # password => 1q2w3e4r }
我們將上述配置,保存到logstash.conf,然後運行logstash
在logstash啟動完成之後,輸入上面的那條訪問記錄,logstash將輸出過濾後的數據:
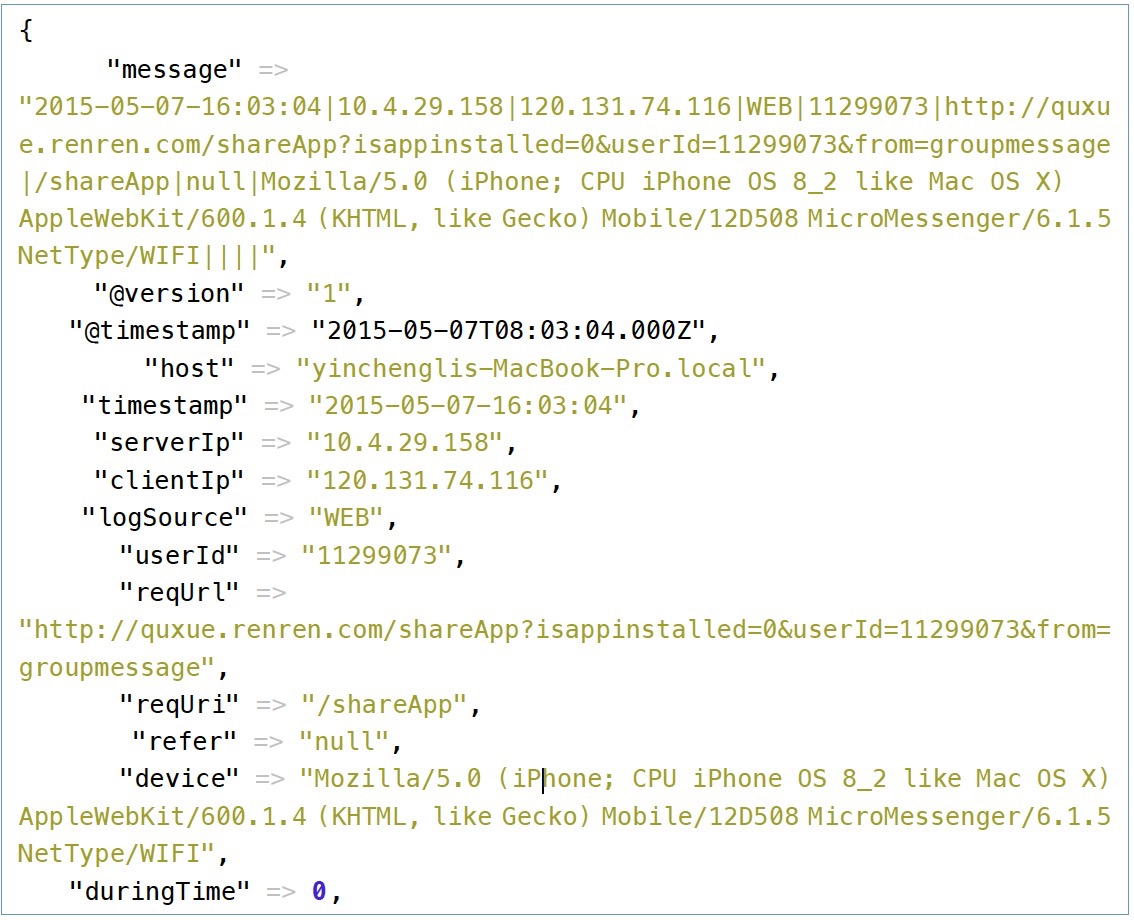

可以看到logstash,自動去查詢IP的歸屬地,並將請求裡面的device欄位進行分析。
二、配置Elasticsearch和kibana
1. Elasticsearch
這個不需要怎麼配,使用預設的配置即可。配置是: config/elasticsearch.yml
如果需要設置數據的過期時間,可以加上這兩行(目測是這樣配的,沒有驗證過,讀者可以試一下):
#設置為30天過期 indices.cache.filter.expire: 30d index.cache.filter: 30d
Elasticsearch預設監聽在9200埠,可對其進行查詢和管理,例如看索引的健康狀態:
curl 'localhost:9200/_cluster/health?level=indices&pretty'
輸出
{ "cluster_name" : "elasticsearch", "status" : "yellow", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 1, "active_primary_shards" : 161, "active_shards" : 161, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 161, "number_of_pending_tasks" : 0, "indices" : { "logstash-2015.05.05" : { "status" : "yellow", #有三級,green, yellow和red "number_of_shards" : 5, "number_of_replicas" : 1, "active_primary_shards" : 5, "active_shards" : 5, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 5 }
}
可在瀏覽器進行訪問,例如查詢一下使用chrome瀏覽器情況:
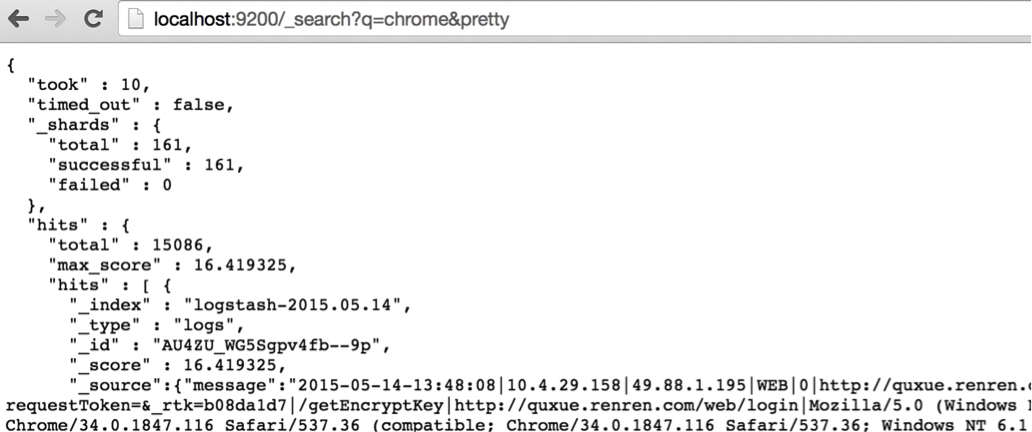
2. kibana
這個也不用配置,預設監聽在5601埠。
#讓它運行在後臺
localhost# nohup bin/kibana &
註意以上兩個要使用Java 7以上版本,還有小版本要求,下一個最新的Java 8即可,然後在啟動腳本里export JAVA_HOME;
三、可視化數據分析
訪問5601埠,如localhost:5601,打開kibana
1. 生成索引名稱
第一次訪問kibana會重定向到設置索引的頁面:
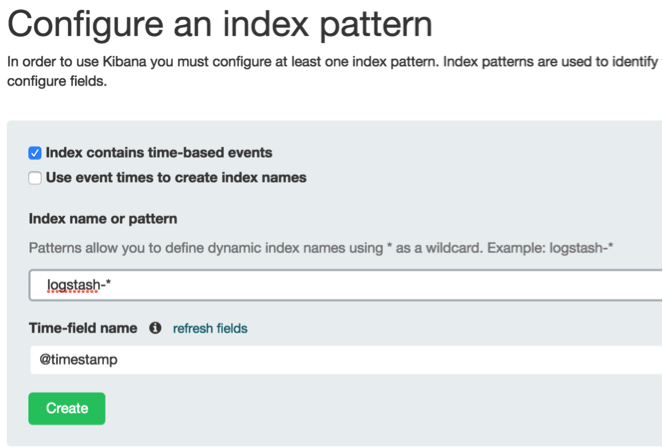
在藍色方框里輸入要進行探索的索引,如果輸入logstash-*就是匹配所有的索引,還可以指定日期,logstash的索引是按日期區分的,一個日期一個文件夾
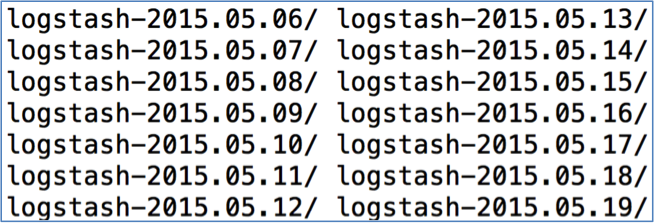
因此也可以輸入logstash-2015.05*,那麼如果用這個索引名稱,在接下來的操作都是針對5月份的記錄。也可以再一個六月份的,在接下來的過程中在網頁左上角索引那裡隨時進行切換。
2. 按天查看上月份的訪問量
點左上角的discover
![]()
再點右上角的時鐘,選時間

有三種格式的時間可以選擇,我們選擇上一個月,就可以看到上月份的訪問情況:
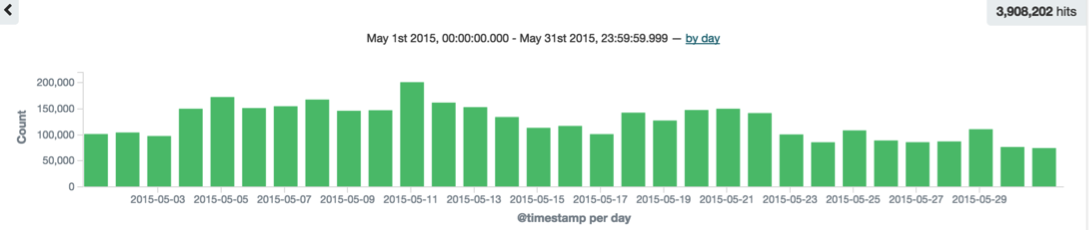
3. 按地域訪問情況
點擊上面菜單欄的visualize,選擇最後一個條形圖,再選擇from a new search

在左邊的視窗里選擇X-Axis,然後,Aggregation選擇Date Histogram,Interval選擇Daily,以天為單位
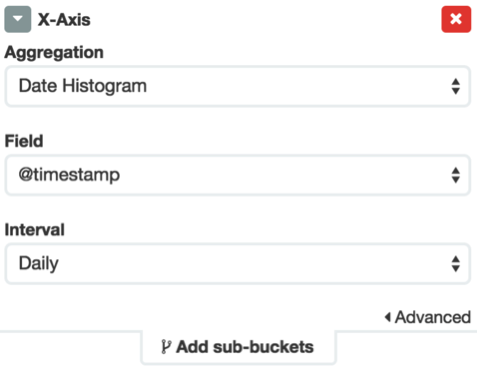
再點擊上圖的綠色箭頭,右邊出來日訪問量:
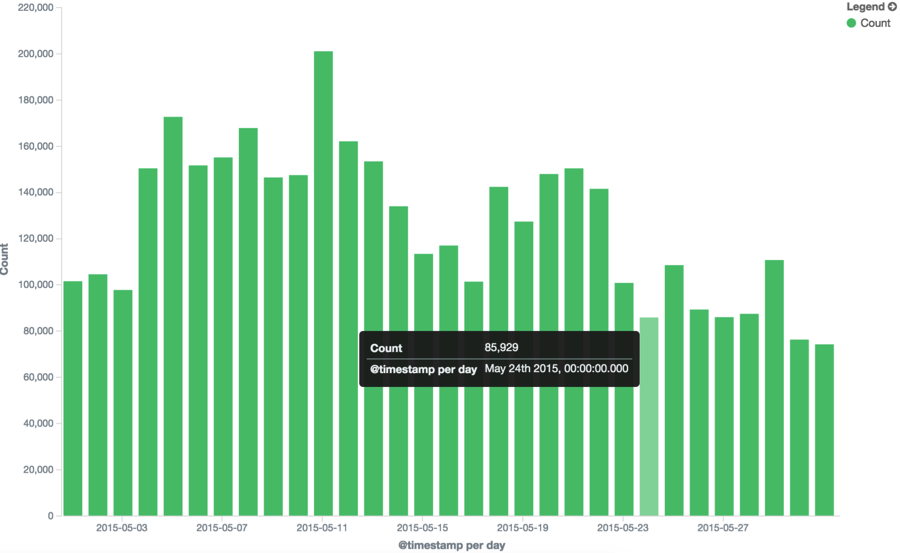
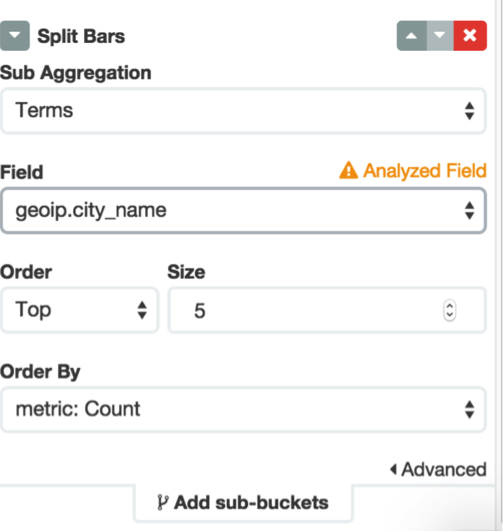
接著點擊左邊的Add Sub-buckets,選擇split bars,然後Sub Aggression選擇Terms,相應的Field選擇city_name,如下圖:
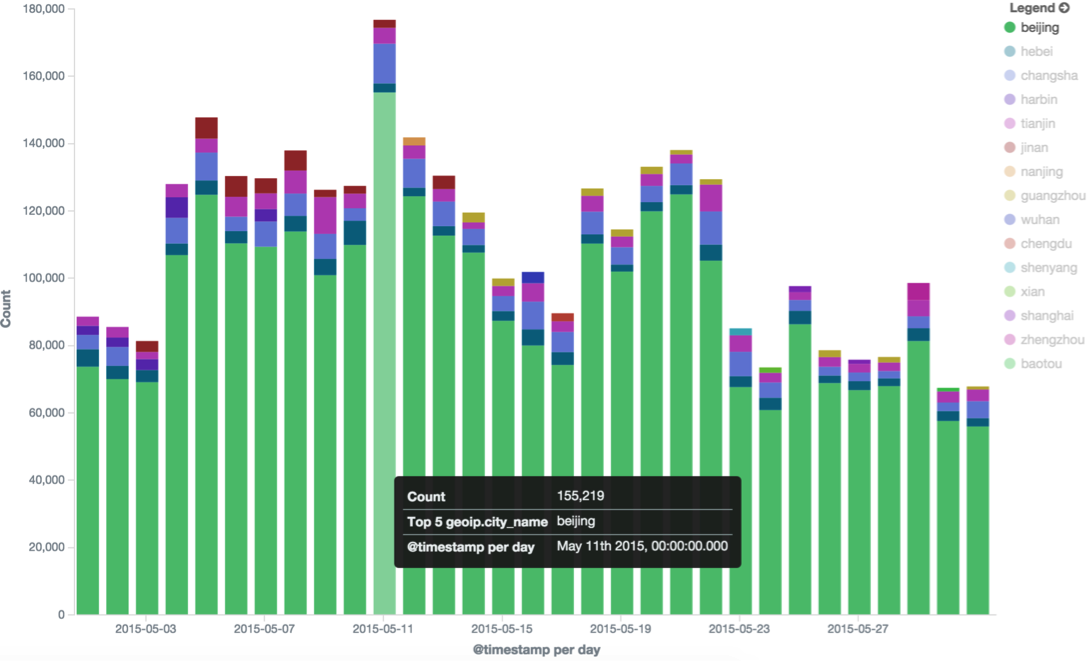
點綠色的播放按鈕,右邊出來按照每天最高訪問量的5個城市:
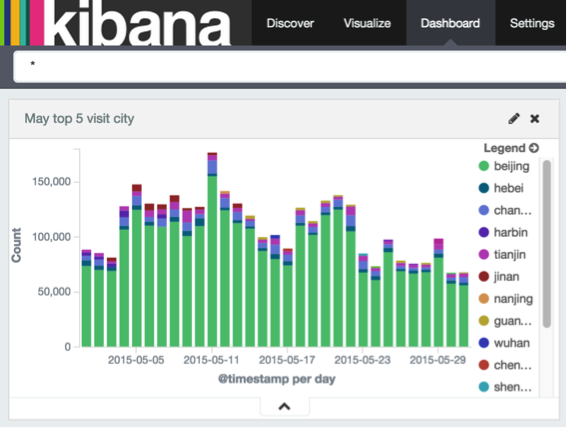
然後把它保存到Dashboard里,等會還要進行比較,點擊右上角的save按鈕,再起個名字
點擊上面菜單欄的Dashboard,將剛剛保存的加進去。
接下來我們看一下,這幾個城市的人分別訪問的哪些介面比較多,可能可以看出不同地域的人對什麼感興趣
4. 查看不同城市的人訪問介面的異同
點擊Visulize(點兩次),選擇倒數第三個的餅圖,接下來的操作類型於上面,按回車:

可以看出五月份的訪問量,北京最多,然後就是長沙、天津、河北。
接著,Add sub-buckets,如下配置

可以看出,北京訪問的介面從高到低今次是getdataversion、getthomeinfo、getactivitys等。然後繼續保存到Dashboard。
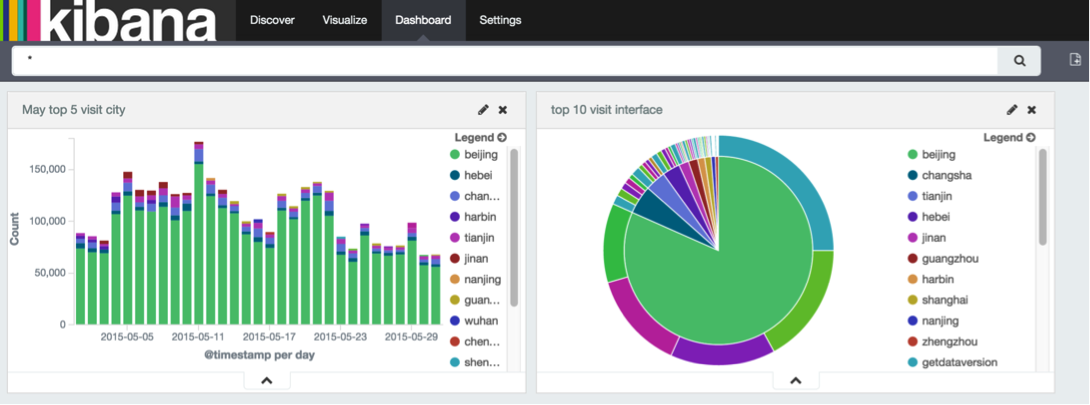
再看下訪問比較活躍的是哪幾個IP
5. 查看訪問量最高的幾個IP
繼續點visualize,選擇data table,相應的配置類似於上面,返回一個前20個最活躍的IP的表格:

保存到面板
然後再看下5月份,總的訪問量
6. 總點擊量
在visualize那裡選擇metric,總的訪問量為:

還可以看下在地圖上的分佈
7. 地圖分佈
在visualize選擇Title map
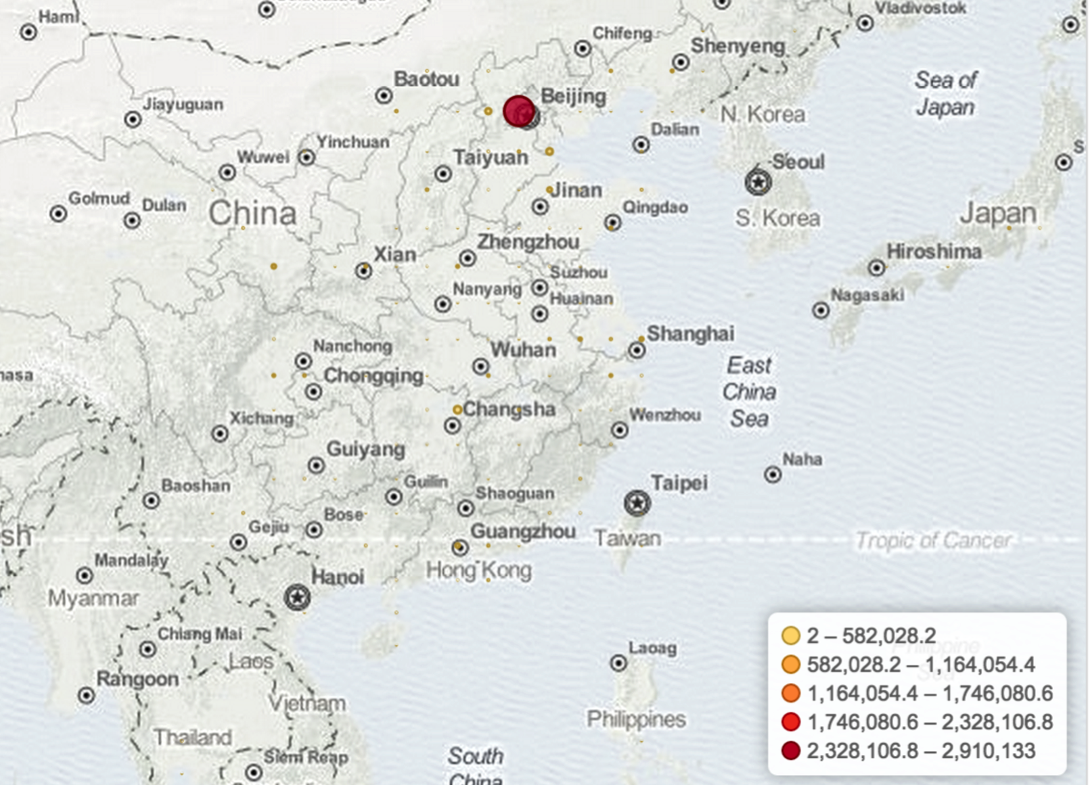
可以看出訪問量主要集中在北京一帶。
同樣保存到面板,現在在面板保存了5張圖:
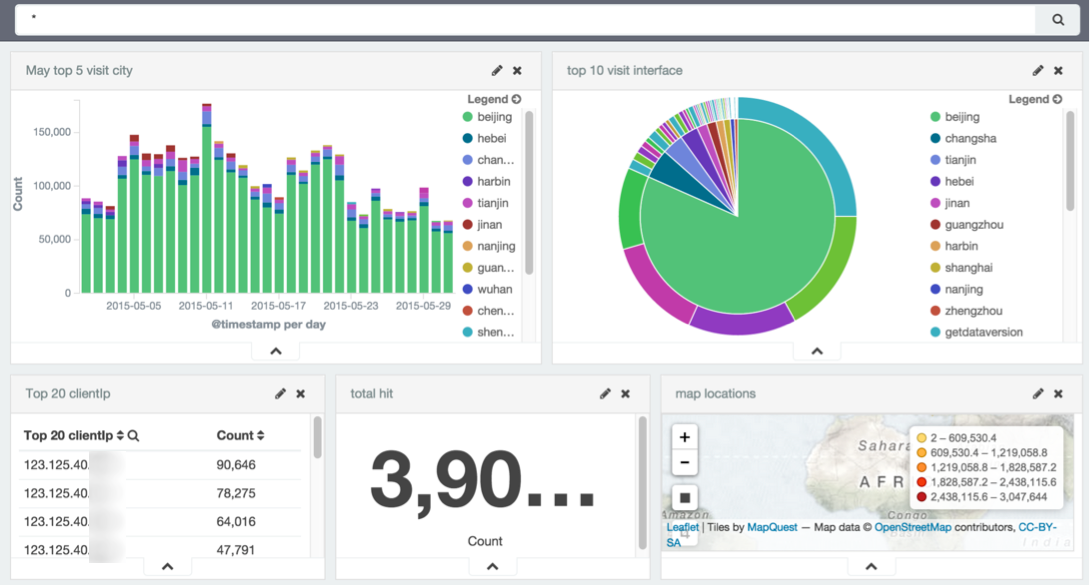
8. Dashboard的相關聯操作
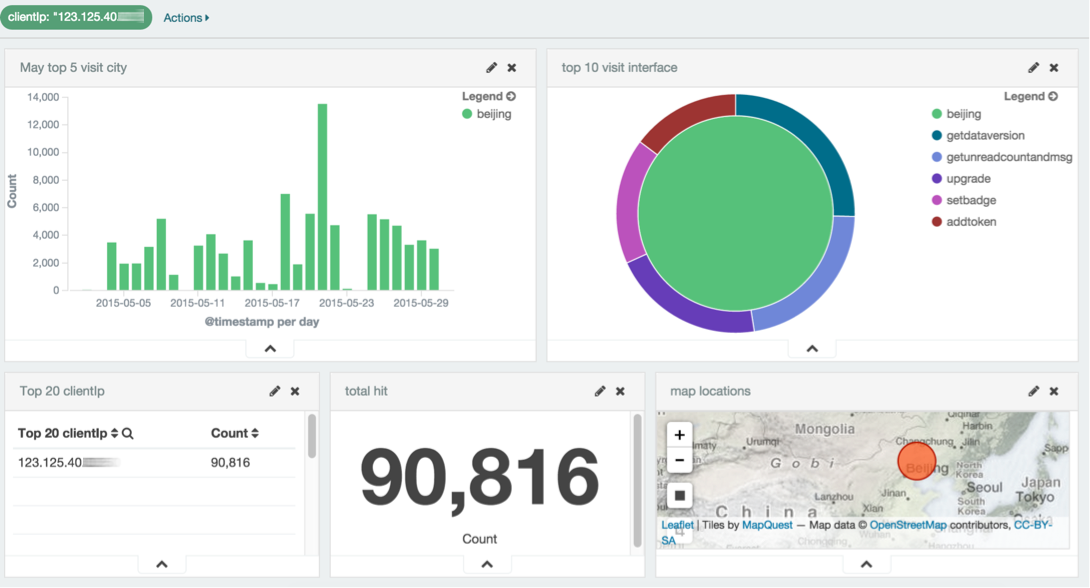
Dashboard的一個強大之處是可以進行關聯查看。例如說要看一下最活躍的IP,是什麼時候訪問的,訪問了哪些介面。
只需要在上圖左下角的clientIP點一下相應的IP即可,面板里的其它各圖都會相應地變化。
 9. 搜索
9. 搜索
kibana每個頁面都有一個搜索的輸入框,進行的任何可視化都可以通過搜索動態地改變.
![]()
kibana的搜索使用Luence語法,常用的可能就以下幾個
(1)欄位名:值
點擊上面菜單的Discover,在搜索那裡輸入: clientIp:123.125.40.1,就可以調出這個IP,該段時間內所進行的所有訪問,然後再進行後續其它的各種操作。
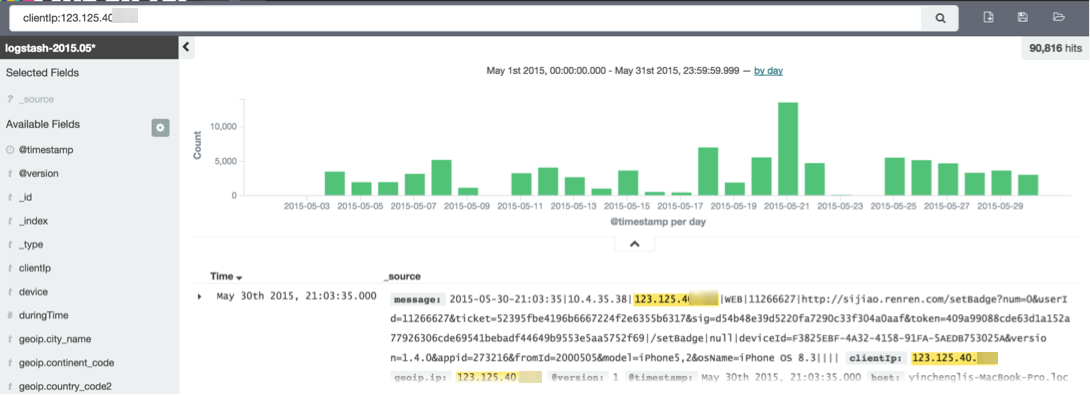
例如再看下他使用什麼設備訪問,在左邊側欄點擊userDevice.os_name,再點Visualize
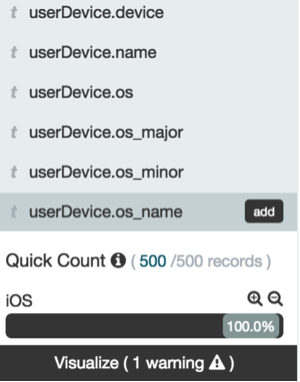
可以看出他使用的是ios系統比較多:
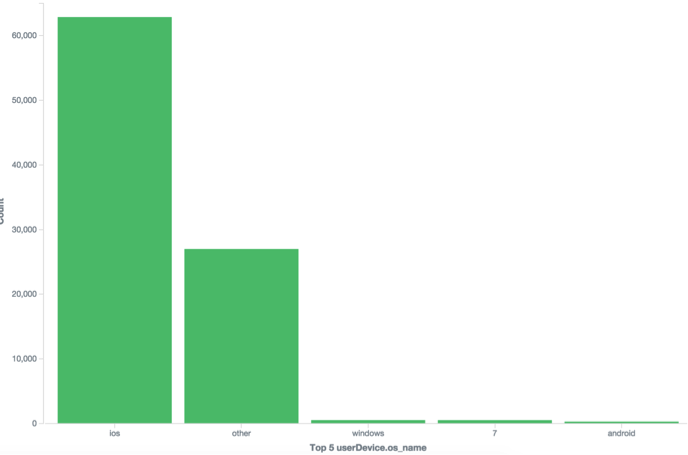
(2)To 範圍
欄位是Number型的支持範圍搜索,例如看下響應時間在1000ms以上的。搜索duringTime:[1000 TO 1000000000]
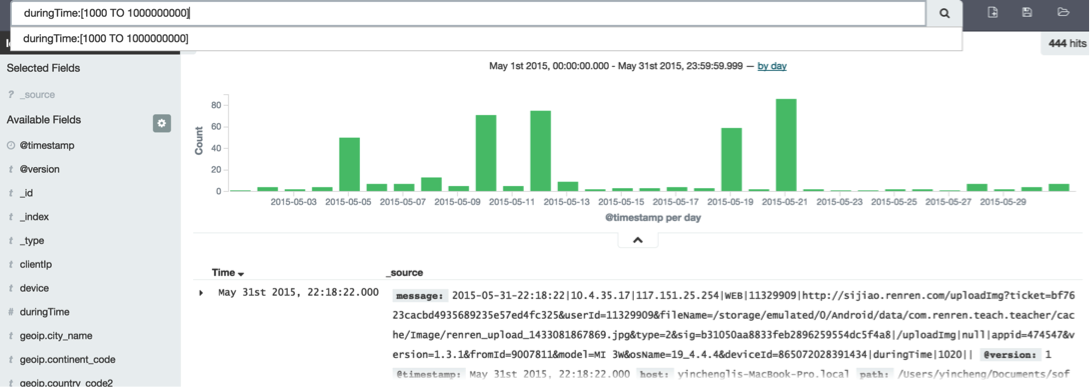
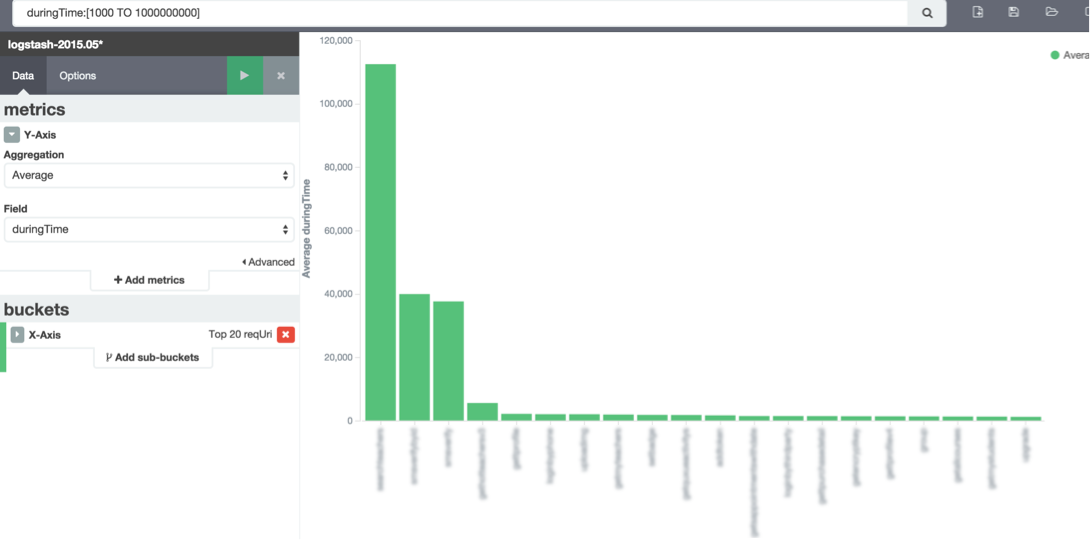
看下是哪些介面,設置y軸為平均響應時間,就可以看出哪些介面的調用比較耗時:
(3)支持and or ()的組合,這裡不再說明。
這裡只是根據自已的日誌進行一個分析,讀者可根據自己的數據內容做相關的挖掘
參考:
1. https://www.elastic.co/ logstash官網


