
正則表達式基礎以及grep的簡單使用 1 定義 正則表達式是你所定義的模式模板,Linux可以用它來過濾文本。Linux工具(比如grep、sed、gawk)能夠在處理數據時使用正則表達式對數據進行模式匹配。如果數據匹配模式,它就會被接受併進一步處理;如果數據不匹配,它就會被濾掉。 2 正則表達式的 ...
正則表達式基礎以及grep的簡單使用
1 定義
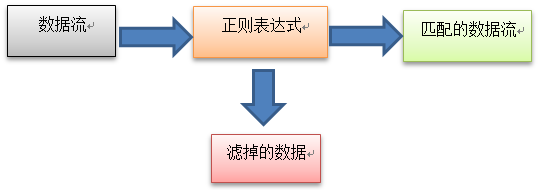
正則表達式是你所定義的模式模板,Linux可以用它來過濾文本。Linux工具(比如grep、sed、gawk)能夠在處理數據時使用正則表達式對數據進行模式匹配。如果數據匹配模式,它就會被接受併進一步處理;如果數據不匹配,它就會被濾掉。
2 正則表達式的原則
(1)正則表達式模式都區分大小寫。(2)可以使用空格,數字。(3)空格和其他字元並沒有什麼區別。
3 特殊字元
包括 * [ ] ^ $ ( ) \ + ? | { }
要使用特殊字元,必須轉義,在轉義字元時,需要在它前面加個特殊字元來告訴正則表達式引擎應該將接下來的字元當做普通的文本字元,這個特殊符號就是反斜線(\)。
4 錨字元
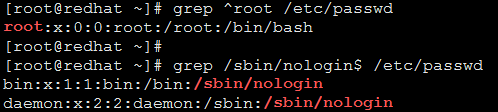
^ 行首錨定
$ 行尾錨定
\b \b 匹配詞首和詞尾
\< \> 匹配詞首和詞尾

5 grep 基本用法
-v 取反,找出不包含關鍵字的行
-i 忽略字元大小寫
-n 顯示匹配的行號
-c 統計匹配到的行數
-o 僅顯示匹配到的字元串
-w 匹配整個單詞
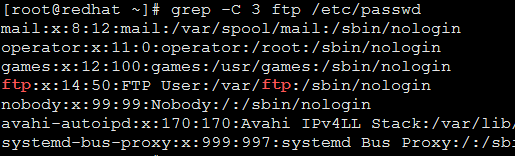
-A n匹配的前n行
-B n 關鍵字的後n行
-C n 關鍵字的前後各n行
-e 實現多個選項的邏輯或關係

-E === egrep 支持擴展的正則表達式
-F === fgrep 不支持正則表達式
6 字元匹配規則
. 配任意單個字元
[abc] 匹配a,b,c中單個字元
[^abc] 匹配除a,b,c之外的字元
[:alnum:] 匹配數字和字元
[:alpha:] 匹配英文大小寫字母a-z,A-Z
[:lower:] 匹配小寫字母
[:upper:] 匹配大寫字母
[:space:] 匹配空格
[:digit:] 匹配十進位數字
7 匹配次數
* 匹配前面的字元任意次數,0至正無窮
.* 匹配任意字元任意次數
\? 匹配前面字元0次或者1次
\+ 匹配前面字元至少1次
\{n\} 配前面字元n次
\{m,n\} 匹配前面字元出現m至n次
\{,n\} 匹配前面字元最多出現n次
\{n,\} 匹配前面字元至少n次
8 擴展正則表達式 egrep
次數匹配,和基本正則表達式類似,就是少了轉義字元(\)
* 匹配前面字元任意次
? 匹配前面字元0次或1次
+ 匹配前面字元1次或多次
{m} 匹配前面字元m 次
{m,n}匹配前面字元m到n 次
9 使用管道(|)
管道允許你在檢查數據時,用邏輯或方式指定正則表達式引擎要用的兩個或者多個模式,如果任何一個模式匹配了數據文本,文本就通過,如果沒有模式匹配,則數據流文本匹配失敗。

10 分組
將匹配規則分成不同的組 使用 1 2 3..等數字去標識,便於後面使用同樣規則的時候可以直接飲用
\(root\)\+\1
\(string1\+\(string2\)*\)
\1 string1\+\(string2\)*
\2 string2
找出/etc/passwd用戶名同shell名的行
cat /etc/passwd | grep "^\(\b[[:alnum:]]\+\b\):.*\1$" grep "^\<\(.*\)\>.*\1$" /etc/passwd cat /etc/passwd | egrep "^(\b[[:alnum:]]+\b):.*\1$"



