
學習Hadoop,兩個東西肯定是繞不過,MapReduce和HDFS,上一篇博客介紹了MapReduce的處理流程,這一篇博客就來學習一下HDFS。 HDFS是一個分散式的文件系統,就是將多台機器的存儲當做一個文件系統來使用,因為在大數據的情景下,單機的存儲量已經完全不夠用了,所以採取分散式的方法來 ...
學習Hadoop,兩個東西肯定是繞不過,MapReduce和HDFS,上一篇博客介紹了MapReduce的處理流程,這一篇博客就來學習一下HDFS。
HDFS是一個分散式的文件系統,就是將多台機器的存儲當做一個文件系統來使用,因為在大數據的情景下,單機的存儲量已經完全不夠用了,所以採取分散式的方法來擴容,解決本地文件系統在文件大小、文件數量、打開文件數等的限制問題。我們首先來看一下HDFS的架構
HDFS架構
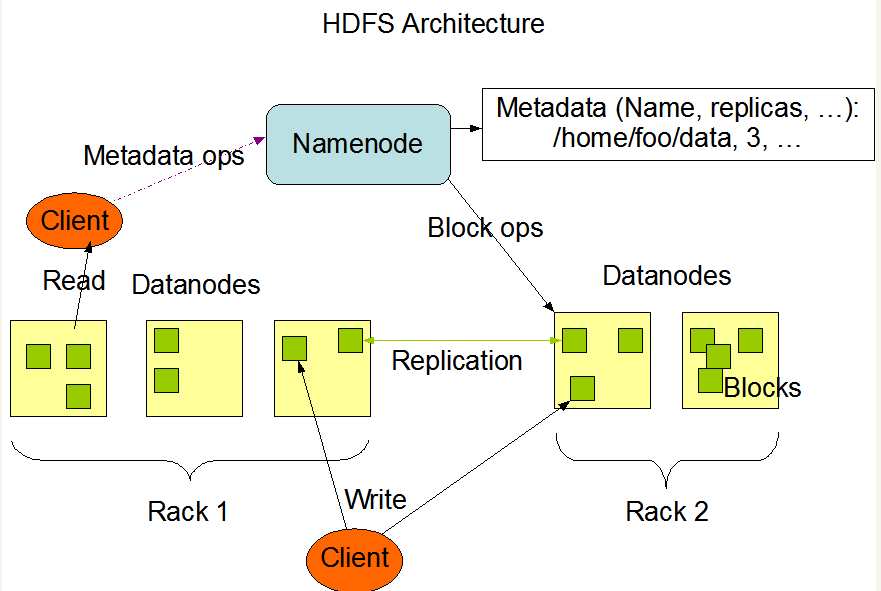
從上圖可以看到,HDFS的主要組成部分為Namenode、Datanodes、Client,還有幾個名詞:Block、Metadata、Replication 、Rack,它們分別是什麼意思呢?
對於分散式的文件系統,數據存儲在很多的機器上,而Datanode代表的就是這些機器,是數據實際存儲的地方,數據存好之後,我們需要知道它們具體存在哪一個Datanode上,這就是Namenode做的工作,它記錄著元數據信息(也就是Metadata,其主要內容就是哪個數據塊存在哪個Datanode上的哪個目錄下,這也是為什麼HDFS不適合存大量小文件的原因,因為 為了響應速度,Namenode 把文件系統的元數據放置在記憶體中,所以文件系統所能容納的文件數目是由 Namenode 的記憶體大小來決定。一般來說,每一個文件、文件夾和 Block 需要占據 150 位元組左右的空間,如果存100 萬個小文件,至少需要 300MB記憶體,但這麼多小文件實際卻沒有存太多數據,這樣就太浪費記憶體了),有了元數據信息,我們就能通過Namenode來查到數據塊的具體位置了,而與Namenode打交道的工具就是Client,Client給我們用戶提供存取數據的介面,我們可以通過Client進行數據存取的工作。
而剩下來的幾個名詞,Block表示的是數據塊,因為存在HDFS上的一般都是很大的文件,我們需要將它拆成很多個數據塊進行存儲;Replication是副本的意思,這是為了數據的可靠性,如果某個數據塊丟失了,還能通過它的副本找回來,HDFS預設一個數據塊存儲三份;Rack表示的是機架的意思,可以理解為存放多個Datanode的地方。
總結一下就是,數據存在Datanode上,並且有副本,而Namenode知道數據及其副本具體存在哪個Datanode上,我們想要找數據或者寫數據的時候就通過Client來和Namenode聯繫,由它來告訴我們應該把數據存在哪裡或者到哪裡去取。
HDFS讀寫流程
看完了HDFS的架構,我們來看一下HDFS具體是怎麼存取數據的。首先是寫流程:
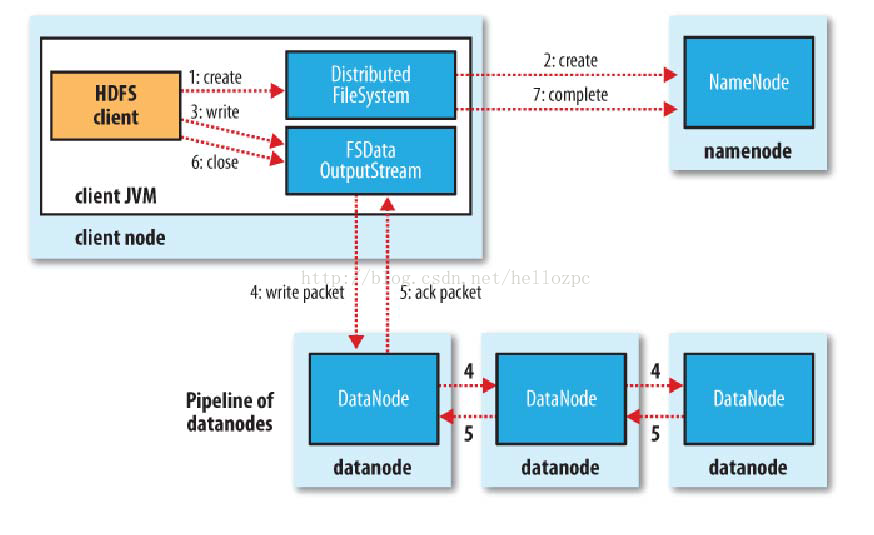
註:以下步驟並不嚴格對應如中的發生順序
1)使用HDFS提供的客戶端開發庫,向遠程的Namenode發起請求;
2)Namenode會檢查要創建的文件是否已經存在,創建者是否有許可權進行操作,成功則會為文件創建一個記錄,否則會讓客戶端拋出異常;
3)當客戶端開始寫入文件的時候,會將文件切分成多個packets(數據包),併在內部以“data queue”(數據隊列)的形式管理這些packets,並向Namenode申請新的blocks,獲取用來存儲replication的合適的datanodes列表,列表的大小根據在Namenode中對replication的設置而定。
4)開始以pipeline(管道)的形式將packet寫入所有的replication中。先將packet以流的方式寫入第一個datanode,該datanode把該packet存儲之後,再將其傳遞給在此pipeline中的下一個datanode,直到最後一個datanode,這種寫數據的方式呈流水線的形式。
5)最後一個datanode成功存儲之後會返回一個ack packet(確認包),在pipeline里傳遞至客戶端,在客戶端內部維護著“ack queue”(確認隊列),成功收到datanode返回的ackpacket後會從“ack queue”移除相應的packet,代表該packet寫入成功。
6)如果傳輸過程中,有某個datanode出現了故障,那麼當前的pipeline會被關閉,出現故障的datanode會從當前的pipeline中移除,剩餘的block會在剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的datanode,保持replication設定的數量。
接下來是讀流程:
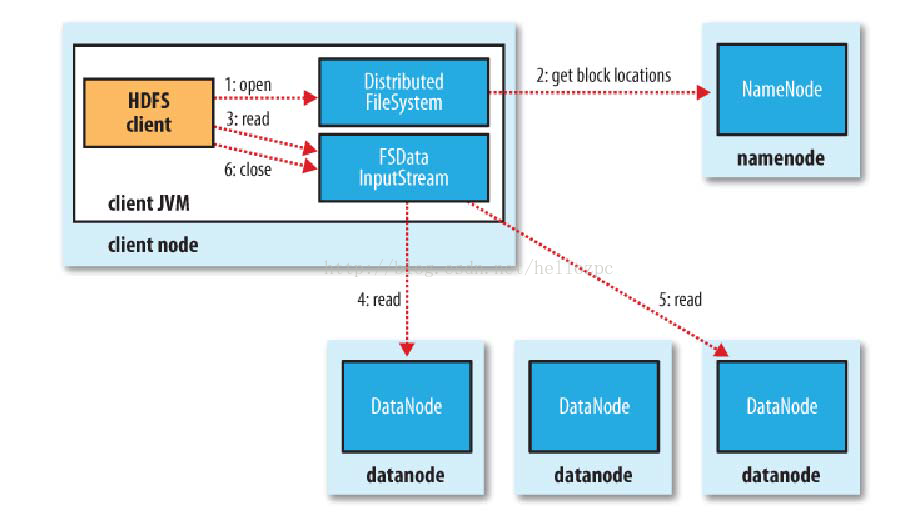
註:以下步驟並不嚴格對應如中的發生順序
1)使用HDFS提供的客戶端,向遠程的Namenode發起請求;
2)Namenode會視情況返迴文件的部分或者全部block列表,對於每個block,Namenode都會返回有該block拷貝的Datanode地址;
3)客戶端會選取離客戶端最接近的Datanode來讀取block;
4)讀取完當前block的數據後,關閉與當前的Datanode連接,併為讀取下一個block尋找最佳的Datanode;
5)當讀完列表的block後,且文件讀取還沒有結束,客戶端會繼續向Namenode獲取下一批的block列表。
6)讀取完一個block都會進行checksum(校驗和)驗證,看文件內容是否出錯;另外,如果讀取Datanode時出現錯誤,客戶端會通知Namenode,然後再從下一個擁有該block拷 貝的Datanode繼續讀。
以上便是HDFS的讀寫流程,瞭解這些之後,我們思考幾個問題,對於分散式的文件系統,我們怎麼保證數據的一致性?就是說如果有多個客戶端向同一個文件寫數據,那麼我們該怎麼處理?另外,我們看到Namenode在HDFS中非常重要,它保存著關鍵的元數據信息,但是從架構圖中看到,Namenode只有一個,如果它掛掉了,我們怎麼保證系統能夠繼續工作?
分散式領域CAP理論
CAP理論是分散式中一個經典的理論,具體內容如下:
Consistency(一致性):在分散式系統中的所有數據備份,在同一時刻是否同樣的值。
Availability(可用性):在集群中一部分節點故障後,集群整體是否還能響應客戶端的讀寫請求。
Partition tolerance(分區容錯性):系統應該能持續提供服務,即使系統內部有消息丟失(分區)。
一致性和可用性比較好理解,主要解釋一下分區容錯性,它的意思就是說因為網路的原因,可能是網路斷開了,也可能是某些機器宕機了,網路延時等導致數據交換無法在期望的時間內完成。因為網路問題是避免不了的,所以我們總是需要解決這個問題,也就是得保證分區容錯性。為了保證數據的可靠性,HDFS採取了副本的策略。
對於一致性,HDFS提供的是簡單的一致性模型,為一次寫入,多次讀取一個文件的訪問模式,支持追加(append)操作,但無法更改已寫入數據。HDFS中的文件都是一次性寫入的,並且嚴格要求在任何時候只能有一個寫入者。什麼時候一個文件算寫入成功呢?對於HDFS來說,有兩個參數:dfs.namenode.replication.min (預設為1) 和dfs.replication (預設為 3),一個文件的副本數大於等於參數dfs.namenode.replication.min 時就被標記為寫成功,但是副本數要是小於參數dfs.replication,此文件還會標記為“unreplication”,會繼續往其它Datanode里寫副本,所以如果我們想要直到所有要保存數據的DataNodes確認它們都有文件的副本時,數據才被認為寫入完成,我們可以將dfs.namenode.replication.min設置與dfs.replication相等。因此,數據一致性是在寫的階段完成的,一個客戶端無論選擇從哪個DataNode讀取,都將得到相同的數據。
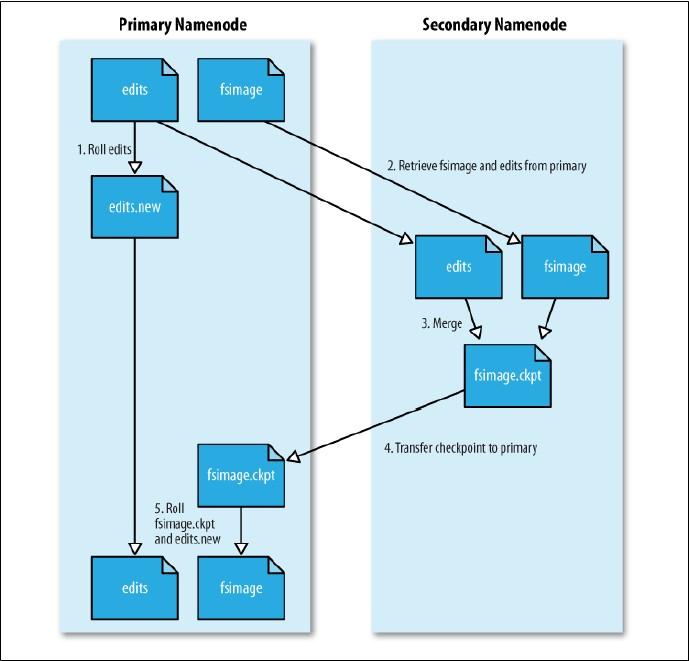
對於可用性,HDFS2.0對Namenode提供了高可用性(High Availability),這裡提一下,Secondary NameNode不是HA,Namenode因為需要知道每個數據塊具體在哪,所以為每個數據塊命名,並保存這個命名文件(fsimage文件),只要有操作文件的行為,就將這些行為記錄在編輯日誌中(edits文件),為了響應的速度,這兩個文件都是放在記憶體中的,但是隨著文件操作額進行,edits文件會越來越大,所以Secondary NameNode會階段性的合併edits和fsimage文件,以縮短集群啟動的時間。當NameNode失效的時候,Secondary NameNode並無法立刻提供服務,Secondary NameNode甚至無法保證數據完整性,如果NameNode數據丟失的話,在上一次合併後的文件系統的改動會丟失。Secondary NameNode合併edits和fsimage文件的流程具體如下:
目前HDFS2中提供了兩種HA方案,一種是基於NFS(Network File System)共用存儲的方案,一種基於Paxos演算法的方案Quorum Journal Manager(QJM),下麵是基於NFS共用存儲的方案
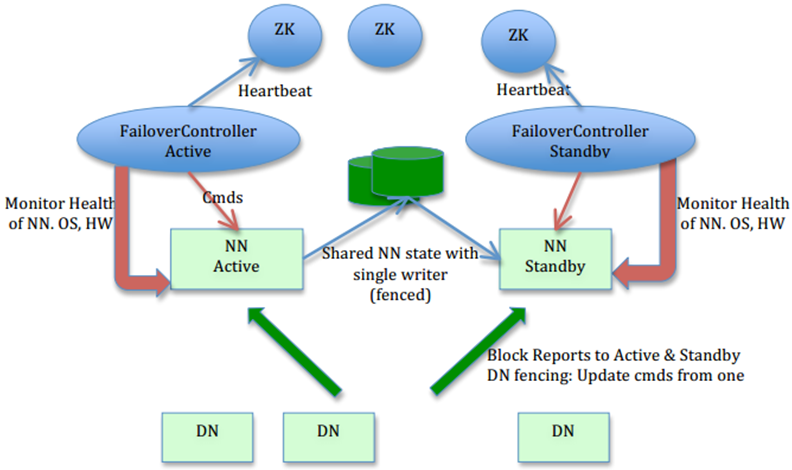
通過上圖可知,Namenode的高可用性是通過為其設置一個Standby Namenode來實現的,要是目前的Namenode掛掉了,就啟用備用的Namenode。而兩個Namenode之間通過共用的存儲來同步信息,以下是一些要點:
• 利用共用存儲來在兩個NameNode間同步edits信息。
• DataNode同時向兩個NameNode彙報塊信息。這是讓Standby NameNode保持集群最新狀態的必需步驟。
• 用於監視和控制NameNode進程的FailoverController進程(一旦工作的Namenode掛了,就啟用切換程式)。
• 隔離(Fencing),防止腦裂,就是保證在任何時候只有一個主NameNode,包括三個方面:
• 共用存儲fencing,確保只有一個NameNode可以寫入edits。
• 客戶端fencing,確保只有一個NameNode可以響應客戶端的請求。
• DataNode fencing,確保只有一個NameNode可以向DataNode下發命令,譬如刪除塊,複製塊,等等。
另一種是QJM方案:
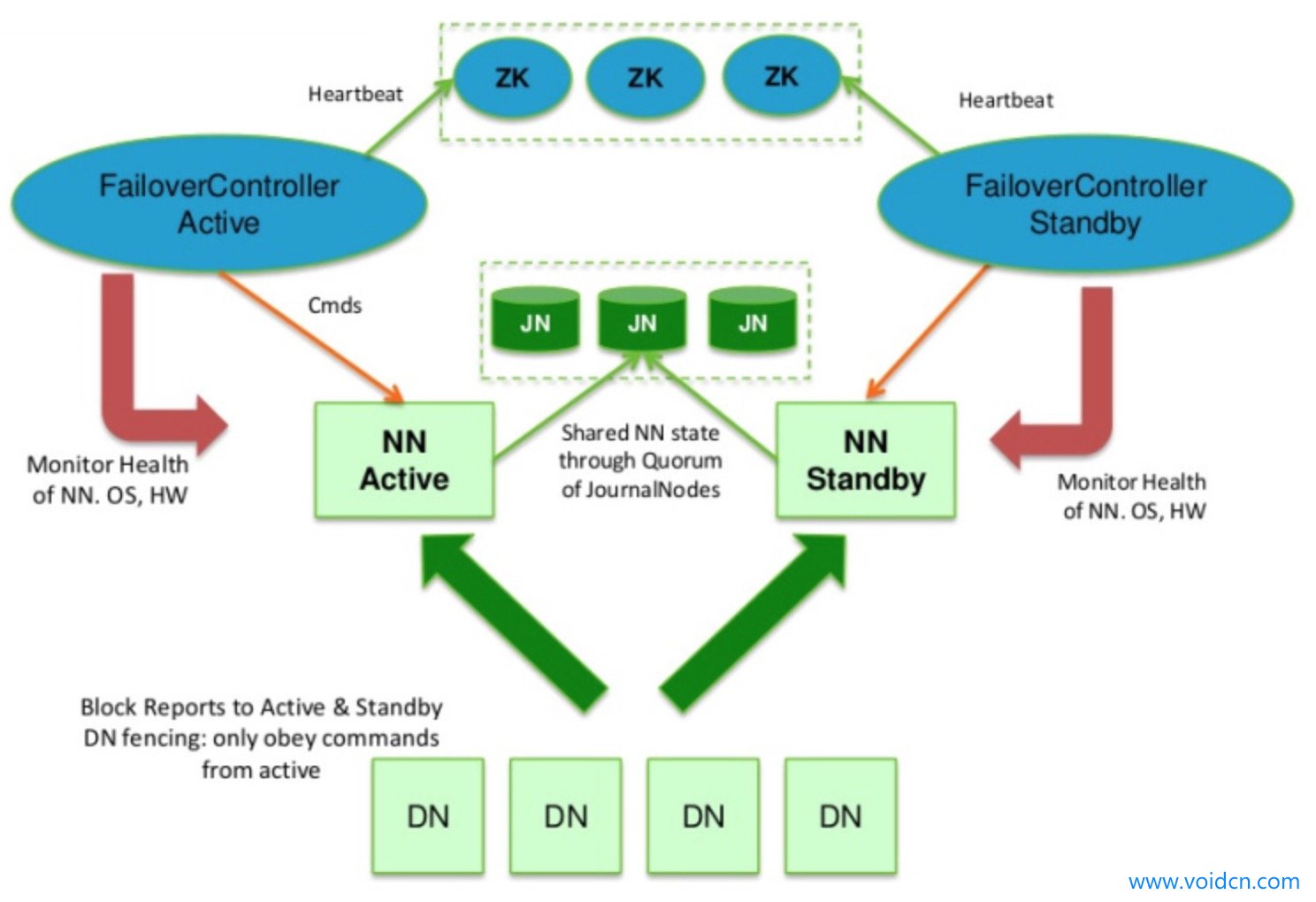
簡單來說,就是為了讓Standby Node與Active Node保持同步,這兩個Node都與一組稱為JNS(Journal Nodes)的互相獨立的進程保持通信。它的基本原理就是用2N+1台JournalNode存儲edits文件,每次寫數據操作有大多數(大於等於N+1)返回成功時即認為該次寫成功。因為QJM方案是基於Paxos演算法的,而Paxos演算法不是兩三句就能說清楚的,有興趣的可以看這個知乎專欄:Paxos演算法或者參考官方文檔。
總結
本篇博客主要介紹了HDFS的架構、讀寫流程和HDFS在CAP上的做法,幫助大家對HDFS的理解,如果想要更詳細的技術細節,可以看看官方文檔或者我在參考中列出的鏈接。
參考
《Hadoop權威指南》
http://www.cnblogs.com/youngerchina/p/5624459.html
http://blog.csdn.net/hguisu/article/details/7259716
http://www.cnblogs.com/codeOfLife/p/5375120.html
https://www.zybuluo.com/jewes/note/68185


