
導讀: 隨著大數據概念的火熱,啤酒與尿布的故事廣為人知。我們如何發現買啤酒的人往往也會買尿布這一規律?數據挖掘中的用於挖掘頻繁項集和關聯規則的Apriori演算法可以告訴我們。本文首先對Apriori演算法進行簡介,而後進一步介紹相關的基本概念,之後詳細的介紹Apriori演算法的具體策略和步驟,最後給出 ...
導讀:
隨著大數據概念的火熱,啤酒與尿布的故事廣為人知。我們如何發現買啤酒的人往往也會買尿布這一規律?數據挖掘中的用於挖掘頻繁項集和關聯規則的Apriori演算法可以告訴我們。本文首先對Apriori演算法進行簡介,而後進一步介紹相關的基本概念,之後詳細的介紹Apriori演算法的具體策略和步驟,最後給出Python實現代碼。
1.Apriori演算法簡介
Apriori演算法是經典的挖掘頻繁項集和關聯規則的數據挖掘演算法。A priori在拉丁語中指"來自以前"。當定義問題時,通常會使用先驗知識或者假設,這被稱作"一個先驗"(a priori)。Apriori演算法的名字正是基於這樣的事實:演算法使用頻繁項集性質的先驗性質,即頻繁項集的所有非空子集也一定是頻繁的。Apriori演算法使用一種稱為逐層搜索的迭代方法,其中k項集用於探索(k+1)項集。首先,通過掃描資料庫,累計每個項的計數,並收集滿足最小支持度的項,找出頻繁1項集的集合。該集合記為L1。然後,使用L1找出頻繁2項集的集合L2,使用L2找出L3,如此下去,直到不能再找到頻繁k項集。每找出一個Lk需要一次資料庫的完整掃描。Apriori演算法使用頻繁項集的先驗性質來壓縮搜索空間。
2. 基本概念
- 項與項集:設itemset={item1, item_2, …, item_m}是所有項的集合,其中,item_k(k=1,2,…,m)成為項。項的集合稱為項集(itemset),包含k個項的項集稱為k項集(k-itemset)。
- 事務與事務集:一個事務T是一個項集,它是itemset的一個子集,每個事務均與一個唯一標識符Tid相聯繫。不同的事務一起組成了事務集D,它構成了關聯規則發現的事務資料庫。
- 關聯規則:關聯規則是形如A=>B的蘊涵式,其中A、B均為itemset的子集且均不為空集,而A交B為空。
-
支持度(support):關聯規則的支持度定義如下:

其中
 表示事務包含集合A和B的並(即包含A和B中的每個項)的概率。註意與P(A or B)區別,後者表示事務包含A或B的概率。
表示事務包含集合A和B的並(即包含A和B中的每個項)的概率。註意與P(A or B)區別,後者表示事務包含A或B的概率。 - 置信度(confidence):關聯規則的置信度定義如下:
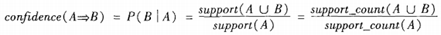
- 項集的出現頻度(support count):包含項集的事務數,簡稱為項集的頻度、支持度計數或計數。
- 頻繁項集(frequent itemset):如果項集I的相對支持度滿足事先定義好的最小支持度閾值(即I的出現頻度大於相應的最小出現頻度(支持度計數)閾值),則I是頻繁項集。
- 強關聯規則:滿足最小支持度和最小置信度的關聯規則,即待挖掘的關聯規則。
3. 實現步驟
一般而言,關聯規則的挖掘是一個兩步的過程:
- 找出所有的頻繁項集
- 由頻繁項集產生強關聯規則
3.1挖掘頻繁項集
3.1.1 相關定義
- 連接步驟:頻繁(k-1)項集Lk-1的自身連接產生候選k項集Ck
Apriori演算法假定項集中的項按照字典序排序。如果Lk-1中某兩個的元素(項集)itemset1和itemset2的前(k-2)個項是相同的,則稱itemset1和itemset2是可連接的。所以itemset1與itemset2連接產生的結果項集是{itemset1[1], itemset1[2], …, itemset1[k-1], itemset2[k-1]}。連接步驟包含在下文代碼中的create_Ck函數中。
由於存在先驗性質:任何非頻繁的(k-1)項集都不是頻繁k項集的子集。因此,如果一個候選k項集Ck的(k-1)項子集不在Lk-1中,則該候選也不可能是頻繁的,從而可以從Ck中刪除,獲得壓縮後的Ck。下文代碼中的is_apriori函數用於判斷是否滿足先驗性質,create_Ck函數中包含剪枝步驟,即若不滿足先驗性質,剪枝。
基於壓縮後的Ck,掃描所有事務,對Ck中的每個項進行計數,然後刪除不滿足最小支持度的項,從而獲得頻繁k項集。刪除策略包含在下文代碼中的generate_Lk_by_Ck函數中。
3.1.2 步驟
- 每個項都是候選1項集的集合C1的成員。演算法掃描所有的事務,獲得每個項,生成C1(見下文代碼中的create_C1函數)。然後對每個項進行計數。然後根據最小支持度從C1中刪除不滿足的項,從而獲得頻繁1項集L1。
- 對L1的自身連接生成的集合執行剪枝策略產生候選2項集的集合C2,然後,掃描所有事務,對C2中每個項進行計數。同樣的,根據最小支持度從C2中刪除不滿足的項,從而獲得頻繁2項集L2。
- 對L2的自身連接生成的集合執行剪枝策略產生候選3項集的集合C3,然後,掃描所有事務,對C3每個項進行計數。同樣的,根據最小支持度從C3中刪除不滿足的項,從而獲得頻繁3項集L3。
- 以此類推,對Lk-1的自身連接生成的集合執行剪枝策略產生候選k項集Ck,然後,掃描所有事務,對Ck中的每個項進行計數。然後根據最小支持度從Ck中刪除不滿足的項,從而獲得頻繁k項集。
3.2 由頻繁項集產生關聯規則
一旦找出了頻繁項集,就可以直接由它們產生強關聯規則。產生步驟如下:
- 對於每個頻繁項集itemset,產生itemset的所有非空子集(這些非空子集一定是頻繁項集);
-
對於itemset的每個非空子集s,如果
 ,則輸出
,則輸出 ,其中min_conf是最小置信度閾值。
,其中min_conf是最小置信度閾值。
4. 樣例以及Python實現代碼
下圖是《數據挖掘:概念與技術》(第三版)中挖掘頻繁項集的樣例圖解。

本文基於該樣例的數據編寫Python代碼實現Apriori演算法。代碼需要註意如下兩點:
- 由於Apriori演算法假定項集中的項是按字典序排序的,而集合本身是無序的,所以我們在必要時需要進行set和list的轉換;
- 由於要使用字典(support_data)記錄項集的支持度,需要用項集作為key,而可變集合無法作為字典的key,因此在合適時機應將項集轉為固定集合frozenset。
""" # Python 2.7 # Filename: apriori.py # Author: llhthinker # Email: hangliu56[AT]gmail[DOT]com # Blog: http://www.cnblogs.com/llhthinker/p/6719779.html # Date: 2017-04-16 """ def load_data_set(): """ Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition) Returns: A data set: A list of transactions. Each transaction contains several items. """ data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'], ['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'], ['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']] return data_set def create_C1(data_set): """ Create frequent candidate 1-itemset C1 by scaning data set. Args: data_set: A list of transactions. Each transaction contains several items. Returns: C1: A set which contains all frequent candidate 1-itemsets """ C1 = set() for t in data_set: for item in t: item_set = frozenset([item]) C1.add(item_set) return C1 def is_apriori(Ck_item, Lksub1): """ Judge whether a frequent candidate k-itemset satisfy Apriori property. Args: Ck_item: a frequent candidate k-itemset in Ck which contains all frequent candidate k-itemsets. Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets. Returns: True: satisfying Apriori property. False: Not satisfying Apriori property. """ for item in Ck_item: sub_Ck = Ck_item - frozenset([item]) if sub_Ck not in Lksub1: return False return True def create_Ck(Lksub1, k): """ Create Ck, a set which contains all all frequent candidate k-itemsets by Lk-1's own connection operation. Args: Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets. k: the item number of a frequent itemset. Return: Ck: a set which contains all all frequent candidate k-itemsets. """ Ck = set() len_Lksub1 = len(Lksub1) list_Lksub1 = list(Lksub1) for i in range(len_Lksub1): for j in range(1, len_Lksub1): l1 = list(list_Lksub1[i]) l2 = list(list_Lksub1[j]) l1.sort() l2.sort() if l1[0:k-2] == l2[0:k-2]: Ck_item = list_Lksub1[i] | list_Lksub1[j] # pruning if is_apriori(Ck_item, Lksub1): Ck.add(Ck_item) return Ck def generate_Lk_by_Ck(data_set, Ck, min_support, support_data): """ Generate Lk by executing a delete policy from Ck. Args: data_set: A list of transactions. Each transaction contains several items. Ck: A set which contains all all frequent candidate k-itemsets. min_support: The minimum support. support_data: A dictionary. The key is frequent itemset and the value is support. Returns: Lk: A set which contains all all frequent k-itemsets. """ Lk = set() item_count = {} for t in data_set: for item in Ck: if item.issubset(t): if item not in item_count: item_count[item] = 1 else: item_count[item] += 1 t_num = float(len(data_set)) for item in item_count: if (item_count[item] / t_num) >= min_support: Lk.add(item) support_data[item] = item_count[item] / t_num return Lk def generate_L(data_set, k, min_support): """ Generate all frequent itemsets. Args: data_set: A list of transactions. Each transaction contains several items. k: Maximum number of items for all frequent itemsets. min_support: The minimum support. Returns: L: The list of Lk. support_data: A dictionary. The key is frequent itemset and the value is support. """ support_data = {} C1 = create_C1(data_set) L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data) Lksub1 = L1.copy() L = [] L.append(Lksub1) for i in range(2, k+1): Ci = create_Ck(Lksub1, i) Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data) Lksub1 = Li.copy() L.append(Lksub1) return L, support_data def generate_big_rules(L, support_data, min_conf): """ Generate big rules from frequent itemsets. Args: L: The list of Lk. support_data: A dictionary. The key is frequent itemset and the value is support. min_conf: Minimal confidence. Returns: big_rule_list: A list which contains all big rules. Each big rule is represented as a 3-tuple. """ big_rule_list = [] sub_set_list = [] for i in range(0, len(L)): for freq_set in L[i]: for sub_set in sub_set_list: if sub_set.issubset(freq_set): conf = support_data[freq_set] / support_data[freq_set - sub_set] big_rule = (freq_set - sub_set, sub_set, conf) if conf >= min_conf and big_rule not in big_rule_list: # print freq_set-sub_set, " => ", sub_set, "conf: ", conf big_rule_list.append(big_rule) sub_set_list.append(freq_set) return big_rule_list if __name__ == "__main__": """ Test """ data_set = load_data_set() L, support_data = generate_L(data_set, k=3, min_support=0.2) big_rules_list = generate_big_rules(L, support_data, min_conf=0.7) for Lk in L: print "="*50 print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport" print "="*50 for freq_set in Lk: print freq_set, support_data[freq_set] print print "Big Rules" for item in big_rules_list: print item[0], "=>", item[1], "conf: ", item[2]
代碼運行結果截圖如下:
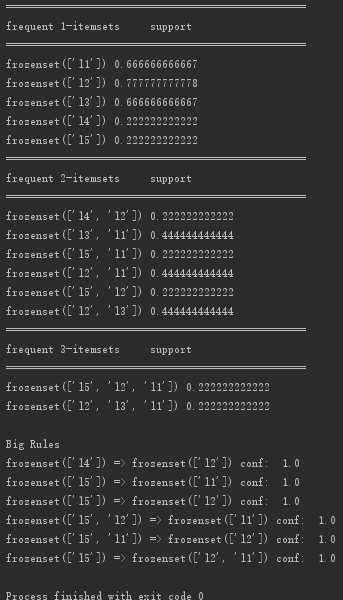
==============================
參考:
《數據挖掘:概念與技術》(第三版)
《機器學習實戰》


