
一、什麼是編碼 編碼是指信息從一種形式或格式轉換為另一種形式或格式的過程。 在電腦中,編碼,簡而言之,就是將人能夠讀懂的信息(通常稱為明文)轉換為電腦能夠讀懂的信息。眾所周知,電腦能夠讀懂的是高低電平,也就是二進位位(0,1組合)。 而解碼,就是指將電腦的能夠讀懂的信息轉換為人能夠讀懂的信息 ...
一、什麼是編碼
編碼是指信息從一種形式或格式轉換為另一種形式或格式的過程。
在電腦中,編碼,簡而言之,就是將人能夠讀懂的信息(通常稱為明文)轉換為電腦能夠讀懂的信息。眾所周知,電腦能夠讀懂的是高低電平,也就是二進位位(0,1組合)。
而解碼,就是指將電腦的能夠讀懂的信息轉換為人能夠讀懂的信息。
二、 編碼的發展淵源
之前的博客中已經提過,由於電腦最早在美國發明和使用,所以一開始人們使用的是ASCII編碼。ASCII編碼占用1個位元組,8個二進位位,最多能夠表示2**8=256個字元。
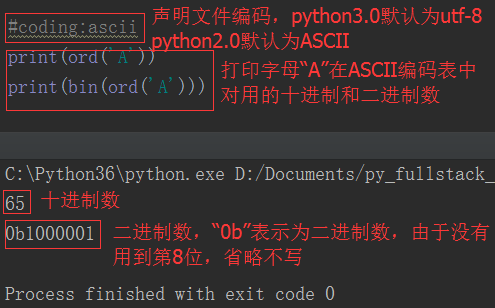
隨著電腦的發展,ASCII碼已經不能滿足世界人民的需求。因為世界各國語言繁多,字元遠遠超過256個。所以各個國家都在ASCII基礎上搞自己國家的編碼。
例如中國,為了處理漢字,設計了GB2312編碼,一共收錄了7445個字元,包括6763個漢字和682個其它符號。1995年的漢字擴展規範GBK1.0收錄了21886個符號。2000年的 GB18030是取代GBK1.0的正式國家標準。該標準收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字。

但是,在編碼上,各國”各自為政“,很難互相交流。於是出現了Unicode編碼。Unicode是國際組織制定的可以容納世界上所有文字和符號的字元編碼方案。
Unicode規定字元最少使用2個位元組表示,所以最少能夠表示2**16=65536個字元。這樣看來,問題似乎解決了,各國人民都能夠將自己的文字和符號加入Unicode,從此就可以輕鬆交流了。
然而,在當時,電腦的記憶體容量可是寸土寸金的情況下,美國等北美洲國家是部接受這個編碼的。因為這憑空增加了他們文件的體積,進而影響了記憶體使用率,影響工作效率。這就尷尬了。
顯然國際標準在美國這邊不受待見,所以應運而生產生了utf-8編碼。
UTF-8,是對Unicode編碼的壓縮和優化,它不再要求最少使用2個位元組,而是將所有的字元和符號進行分類:ASCII碼中的內容用1個位元組保存、歐洲的字元用2個位元組保存,東亞的字元用3個位元組保存。
這樣,大家各取所需,皆大歡喜。
三、utf-8是如何節省存儲空間和流量的
當電腦在工作時,記憶體中的數據一直時以Unicode的編碼方式表示的,當數據要保存到磁碟或者網路傳輸時,才會使用utf-8編碼進行操作。
在電腦中,”I'm 傑克"的unicode字元集是這樣的編碼表:
I 0x49 ' 0x27 m 0x6d 0x20 傑 0x6770 克 0x514b
每個字元對應一個十六進位數(方便人們閱讀,0x代表十六進位數),但是電腦只能讀懂二進位數,所以,實際在電腦內表示如下:
I 0b1001001 ' 0b100111 m 0b1101101 0b100000 傑 0b110011101110000 克 0b101000101001011
由於Unicode規定,每個字元最少占用2個位元組,所以,以上字元串在記憶體中的實際占位如下:
I 00000000 01001001 ' 00000000 00100111 m 00000000 01101101 00000000 00100000 傑 01100111 01110000 克 01010001 01001011
這串字元總共占用了12個位元組,但是對比中英文的二進位碼,可以發現,英文的前9位都是0,非常的浪費空間和流量。
看看utf-8是怎麼解決的:
I 01001001 ' 00100111 m 01101101 00100000 傑 11100110 10011101 10110000 克 11100101 10000101 10001011
utf-8用了10個位元組,對比Unicode,少了2個位元組。但是,我們的程式中很少用到中文,如果我們程式中90%的內容都是英文,那麼可以節省45%的存儲空間或者流量。
所以,在存儲和傳輸時,大部分時候遵循utf-8編碼

四、Python2.x與Python3.x中的編解碼
1. 在Python2.x中,有兩種字元串類型:str和unicode類型。str存bytes數據,unicode類型存unicode數據
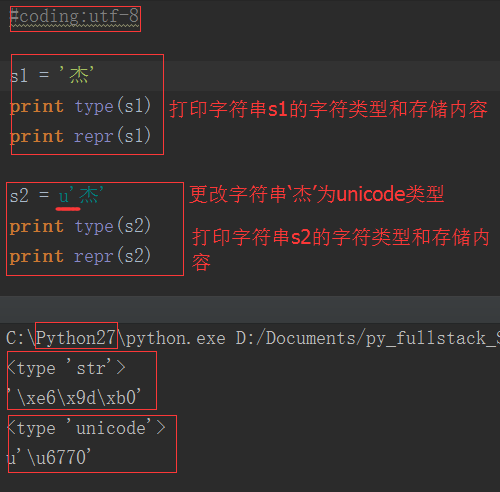
由上圖可以看出,str類型存儲的是十六進位位元組數據;unicode類型存儲的是unicode數據。utf-8編碼的中文占3個位元組,unicode編碼的中文占2個位元組。
位元組數據常用來存儲和傳輸,unicode數據用來顯示明文,那如何轉換兩種數據類型呢:

無論是utf-8還是gbk都只是一種編碼規則,一種把unicode數據編碼成位元組數據的規則,所以utf-8編碼的位元組一定要用utf-8的規則解碼,否則就會出現亂碼或者報錯的情況。
python2.x編碼的特色:
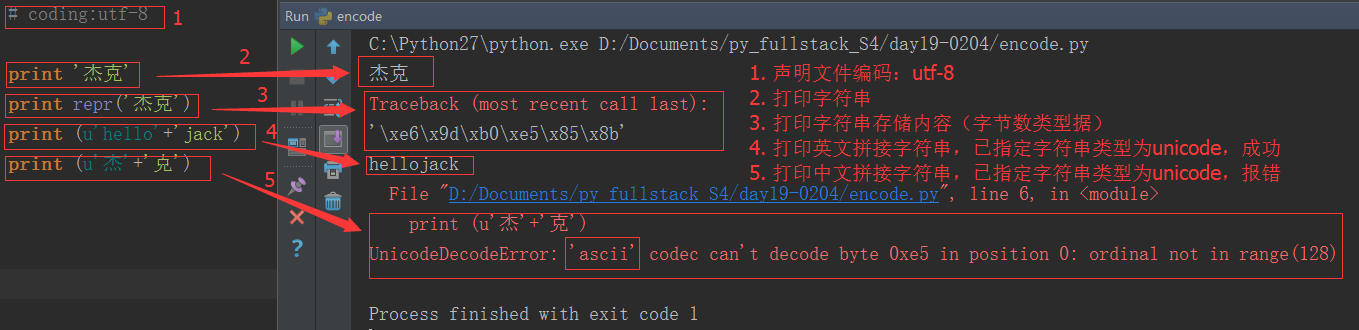
為什麼英文拼接成功了,而中文拼接就報錯了?
這是因為在python2.x中,python解釋器悄悄掩蓋掉了 byte 到 unicode 的轉換,只要數據全部是 ASCII 的話,所有的轉換都是正確的,一旦一個非 ASCII 字元偷偷進入你的程式,那麼預設的解碼將會失效,從而造成 UnicodeDecodeError 的錯誤。python2.x編碼讓程式在處理 ASCII 的時候更加簡單。你付出的代價就是在處理非 ASCII 的時候將會失敗。
2. 在Python3.x中,也只有兩種字元串類型:str和bytes類型。
str類型存unicode數據,bytse類型存bytes數據,與python2.x比只是換了一下名字而已。
還記得之前博文中提到的這句話嗎?ALL IS UNICODE NOW
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.

Python 3最重要的新特性大概要算是對文本和二進位數據作了更為清晰的區分,不再會對bytes位元組串進行自動解碼。文本總是Unicode,由str類型表示,二進位數據則由bytes類型表示。Python 3不會以任意隱式的方式混用str和bytes,正是這使得兩者的區分特別清晰。你不能拼接字元串和位元組包,也無法在位元組包里搜索字元串(反之亦然),也不能將字元串傳入參數為位元組包的函數(反之亦然)。
註意:無論python2,還是python3,與明文直接對應的就是unicode數據,列印unicode數據就會顯示相應的明文(包括英文和中文)
五、文件從磁碟到記憶體的編碼
當我們在編輯文本的時候,字元在記憶體對應的是unicode編碼的,這是因為unicode覆蓋範圍最廣,幾乎所有字元都可以顯示。但是,當我們將文本等保存在磁碟時,數據是怎麼變化的?
答案是通過某種編碼方式編碼的bytes位元組串。比如utf-8,一種可變長編碼,很好的節省了空間;當然還有歷史產物的gbk編碼等等。於是,在我們的文本編輯器軟體都有預設的保存文件的編碼方式,比如utf-8,比如gbk。當我們點擊保存的時候,這些編輯軟體已經"默默地"幫我們做了編碼工作。
那當我們再打開這個文件時,軟體又默默地給我們做瞭解碼的工作,將數據再解碼成unicode,然後就可以呈現明文給用戶了!所以,unicode是離用戶更近的數據,bytes是離電腦更近的數據。
其實,python解釋器也類似於一個文本編輯器,它也有自己預設的編碼方式。python2.x預設ASCII碼,python3.x預設的utf-8,可以通過如下方式查詢:
import sys print(sys.getdefaultencoding())
如果我們不想使用預設的解釋器編碼,就得需要用戶在文件開頭聲明瞭。還記得我們經常在python2.x中的聲明嗎?
#coding:utf-8
如果python2解釋器去執行一個utf-8編碼的文件,就會以預設的ASCII去解碼utf-8,一旦程式中有中文,自然就解碼錯誤了,所以我們在文件開頭位置聲明 #coding:utf-8,其實就是告訴解釋器,你不要以預設的編碼方式去解碼這個文件,而是以utf-8來解碼。而python3的解釋器因為預設utf-8編碼,所以就方便很多了。
參考資料
1. http://www.cnblogs.com/yuanchenqi/articles/5956943.html
2. http://www.cnblogs.com/284628487a/p/5584714.html


