
存儲數據的安全性和可靠性是生產資料庫的關註重點,本文為大家分析了目前採用較多的保障MySQL可用性方案。 ...
作者介紹:易固武,騰訊高級工程師,參與騰訊賬號安全建設,騰訊數據倉庫(TDW)優化改造,騰訊雲資料庫等項目,對大規模分散式存儲和計算系統有濃厚的興趣和經歷
MySQL資料庫是目前開源應用最大的關係型資料庫,有海量的應用將數據存儲在MySQL資料庫中。存儲數據的安全性和可靠性是生產資料庫的關註重點。本文分析了目前採用較多的保障MySQL可用性方案。
MySQL Replication
MySQL Replication是MySQL官方提供的主從同步方案,用於將一個MySQL實例的數據,同步到另一個實例中。Replication為保證數據安全做了重要的保證,也是現在運用最廣的MySQL容災方案。Replication用兩個或以上的實例搭建了MySQL主從複製集群,提供單點寫入,多點讀取的服務,實現了讀的scale out。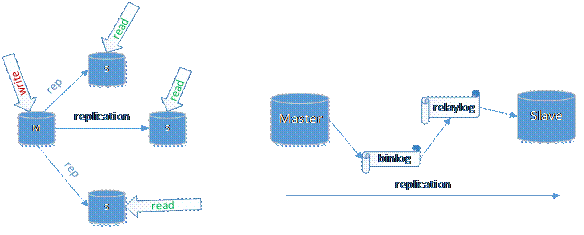
圖1. MySQL Replication主從複製集群
如圖一所示,一個主實例(M),三個從實例(S),通過replication,Master生成event的binlog,然後發給slave,Slave將event寫入relaylog,然後將其提交到自身資料庫中,實現主從數據同步。對於資料庫之上的業務層來說,基於MySQL的主從複製集群,單點寫入Master,在event同步到Slave後,讀邏輯可以從任何一個Slave讀取數據,以讀寫分離的方式,大大降低Master的運行負載,同時提升了Slave的資源利用。
對於高可用來說,MySQL Replication有個重要的缺陷:數據複製的時延。在通常情況下,MySQL Replication數據複製是非同步的,即是MySQL寫binlog後,發送給Slave並不等待Slave返回確認收到,本地事務就提交了。一旦出現網路延遲或中斷,數據延遲發送到Slave側,主從數據就會出現不一致。在這個階段中,Master一旦宕機,未發送到Slave的數據就丟失了,無法做到數據的高可用。
為瞭解決這個問題,google提供瞭解決方案:半同步和同步複製。在數據非同步複製的基礎之上,做了一點修改。半同步複製是Master等待event寫入Slave的relay後,再提交本地,保證Slave一定收到了需要同步的數據。同步複製不不僅是要求Slave收到數據,還要求Slave將數據commit到資料庫中,從而保證每次的數據寫入,主從數據都是一致的。
基於半同步和同步複製,MySQL Replication的高可用得到了質的提升,特別是同步複製。基於同步複製的MySQL Replication集群,每個實例讀取的數據都是一致的,不會存在Slave幻讀。同時,Master宕機後,應用程式切換到任何一個Slave都可以保證讀寫數據的一致性。但是,同步複製帶來了重大的性能下降,這裡需要做一個折衷。另外,MySQL Replication的主從切換需要人工介入判斷,同時需要Slave的replaylog提交完畢,故障恢復時間會比較長。
MySQL Fabric
MySQL Fabric是MySQL社區提供的管理多個MySQL服務的擴展。高可用是它設計的主要特性之一。
Fabric將兩個及以上的MySQL實例劃分為一個HA Group。其中的一個是主,其餘的都是從。HA Group保證訪問指定HA Group的數據總是可用的。其基礎的數據複製是基於MySQL Replication,然後,Fabric提供了更多的特性:
失效檢測和恢復:Fabric監控HA Group中的主實例,一旦發現主實例失效,Fabric會從HA Group中剩餘的從實例中選擇一個,並將其提升為主實例。
讀寫均衡:Fabric可以自動的處理一個HA Group的讀寫操作,將寫操作發送給主實例,而讀請求在多個從實例之間做負載均衡。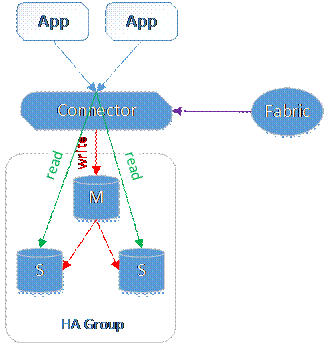
圖2. Fabric
MHA
MHA(MySQL-master-ha)是目前廣泛使用的MySQL主從複製的高可用方案。MHA設計目標是自動實現主實例宕機後,從機切換為主,並儘量降低切換時延(通常在10-30s內切換完成)。同時,由MHA保證在切換過程中的數據一致性。MHA對MySQL的主從複製集群非常友好,沒有對集群做任何侵入性的修改。
MHA的一個重點特性是:在主實例宕機後,MHA可以自動的判斷主從複製集群中哪個從實例的relaylog是最新的,並將最新從實例的差異log“應用”到其餘的從實例中,從而保證每個實例的數據一致。通常情況下,MHA需要10s左右檢測主實例異常,並將主實例關閉從而避免腦裂。然後再用10s左右將差異的log event同步,並啟用新的Master。整個MHA的RTO時間大約在30s。
MySQL Cluster
MySQL Cluster是一個高度可擴展的,相容ACID事務的實時資料庫,基於分散式架構不存在單點故障,MySQL Cluster支持自動水平擴容,並能做自動的讀寫負載均衡。
MySQL Cluster使用了一個叫NDB的記憶體存儲引擎來整合多個MySQL實例,提供一個統一的服務集群。如圖三所示。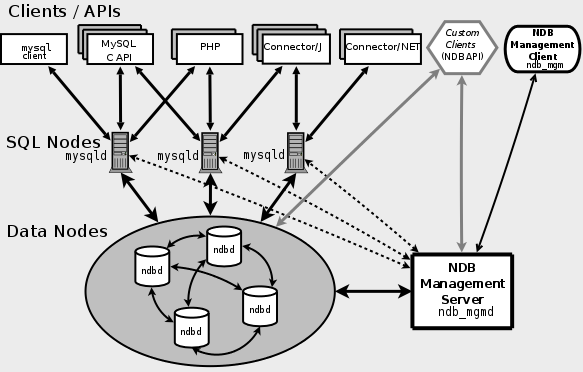
圖3. MySQL Cluster組成
MySQL Cluster由SQL Nodes,DataNodes,和NDB Management Server組成。SQL Nodes是應用程式的介面,像普通的mysqld服務一樣,接受用戶的SQL輸入,執行並返回結果。Data Nodes是數據存儲節點,NDB Management Server用來管理集群中的每個node。
MySQL Cluster採用了新的數據分片和容錯的方式來實現數據安全和高可用。其由Partition,Replica,Data Node,Node Group構成。
Partition:NDB一張表的一個數據分片,包含一張表的一部分數據。
Replica:一個Partition的拷貝。一個Partition可以有一個或多個Replica,一個Partition的所有Replica數據都是一致的。
Data Node:Replica的存儲載體,每個Node存儲一個或多個Replica。
Node Group:一個Data Node的集合。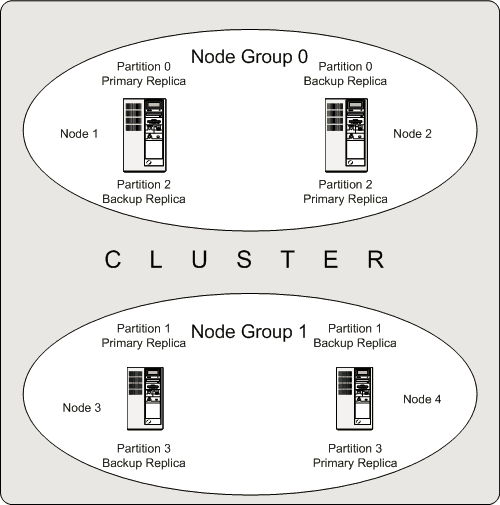
圖4. MySQL Cluster數據高可用
一個MySQL Cluster有4個Node,被分為了兩個Grou。Node1和2歸屬於Group0,Node3和4歸屬於Group1,。有一張表被分為4個Partition,並分別有兩個Replica。Partition0和Partition2的兩個Replica,分別存儲在Node1和Node2上,Pratition1和Partition3的兩個Replica分別存在Node3和Node4上。這樣,對於一張表的一個Partition來說,在整個集群有兩份數據,並分佈在兩個獨立的Node上,實現了數據容災。同時,每次對一個Partition的寫操作,都會在兩個Replica上呈現,如果Primary Replica異常,那麼Backup Replica可以立即提供服務,實現數據的高可用。
小結
本文分析了目前MySQL使用較多的幾種MySQL數據複製和高可用方案,從使用來看,MySQL Replication是使用最為廣泛的數據複製方案,因為是MySQL原生支持,針對其在不同場景下的一些缺陷,衍生出了半同步複製,強同步複製等數據高可用的方案。在此基礎之上,為了運維方便,MySQL Fabric和MHA應運而生,從不同的方向解決了主從切換時數據一致性問題和流程自動化的問題。此外,隨著分散式系統架構和方案的逐步成熟。MySQL Cluster設計了全新的分散式架構,採用多副本,Sharding等特性,支持水平擴展,做到了5個9的資料庫服務質量保證。
參考文獻
1.http://dev.mysql.com/doc/refman/5.7/en/mysql-cluster.html
2.https://code.google.com/p/mysql-master-ha/
3.https://www.mysql.com/products/enterprise/fabric.html
相關推薦
MySQL語句複製(SBR)的缺陷列舉
基於Discuz的Mysql雲資料庫搬遷實例解析
雲資料庫CDB for MySQL相關文檔
此文已由作者授權騰訊雲技術社區發佈,轉載請註明文章出處,獲取更多雲計算技術乾貨,可請前往騰訊雲技術社區


