
awk: 強大的文本處理工具,擅長對日誌文件進行分析; 不僅用於Linux,也是任何環境中現在的功能最強大的數據處理引擎; 語法說明: awk '{pattern + action}' {filenames} pattern:指在數據中要查找的內容; action:指要操作的指令。 {}可以對一系列 ...
awk:
強大的文本處理工具,擅長對日誌文件進行分析;
不僅用於Linux,也是任何環境中現在的功能最強大的數據處理引擎;
語法說明:
awk '{pattern + action}' {filenames}
pattern:指在數據中要查找的內容;
action:指要操作的指令。
{}可以對一系列指令進行分組,不一定要出現。pattern要表達的正則表達式要用斜杠括起來。
通常,awk是以文件的一行為處理單位,每接收一行就執行相應的命令。
三種調用方法:
-
命令行:
awk [-F field-separator] 'commands' input-files
field-separator:域分隔符,指文件每一行中每個域分隔的符號,預設為空格。
-
shell腳本:
將所有awk命令插入到一個文件,並使awk程式可執行,awk命令解釋器作為腳本的首行。
#!/bin/awk
-
將所有awk命令插入到單獨文件,調用:
awk –f script-file input-files
-f選項載入script-file中的awk腳本。
awk執行流程:
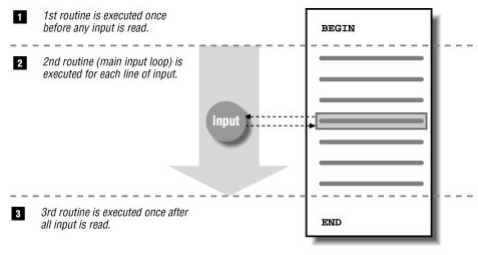
示例:
-
awk '{print $1}' access.201204
意思:顯示access.201204文件的每一行中的第一個$1數據,$1為每一行中空格相隔的第一個字串,$2為第二個字串,以此類推。
如果將print $1保存在文件內,假設保存為test1,則可以寫成:awk –f test1 access.201204
-
awk '$1~/sina/{print $1}' e20120706
意思:$1字串匹配sina字元串時,則執行print $1。
-
awk '{ip[$1]++} END { for (i in ip) {print i,ip}}' access.2028 | less |sort -nr
意思:將每行$1作為ip數組下標,進行重覆計數統計,完後再迴圈ip數組,顯示下標和統計結果,並按降序排列。
內置變數:
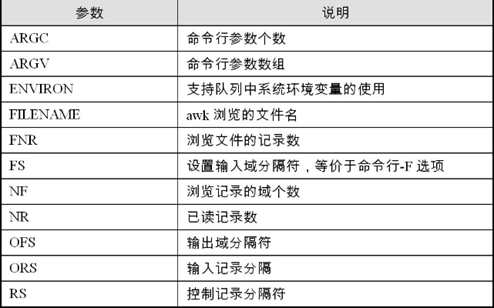
操作符:
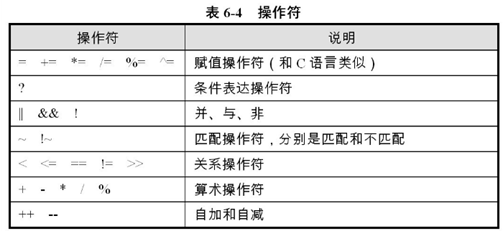
常用的字元串函數:

控制流和迴圈:

數組輸出:

參考筆記:
http://linux.vbird.org/somepaper/20090427-learn_sed_and_awk.pdf


