
redis 集群的原理介紹。寫的不對的地方,還望給位大神多多指正。 ...
redis是單線程,但是一般的作為緩存使用的話,redis足夠了,因為它的讀寫速度太快了。
官方的一個簡單測試:
測試完成了50個併發執行100000個請求。
設置和獲取的值是一個256位元組字元串。
結果:讀的速度是110000次/s,寫的速度是81000次/s
在這麼快的讀寫速度下,對於一般程式來說足夠用了,但是對於訪問量特別大的網站來說,還是稍有不足。那麼,如何提升redis的性能呢?看標題就知道了,搭建集群。
3.0版本之前
3.0版本之前的redis是不支持集群的,我們的徐子睿老師說,那個時候,我們的redis如果想要集群的話,就需要一個中間件,然後這個中間件負責將我們需要存入redis中的數據的key通過一套演算法計算得出一個值。然後根據這個值找到對應的redis節點,將這些數據存在這個redis的節點中。
在取值的時候,同樣先將key進行計算,得到對應的值,然後就去找對應的redis節點,從對應的節點中取出對應的值。
這樣做有很多不好的地方,比如說我們的這些計算都需要在系統中去進行,所以會增加系統的負擔。還有就是這種集群模式下,某個節點掛掉,其他的節點無法知道。而且也不容易對每個節點進行負載均衡。
3.0版本及以後
先來一張redis集群的架構圖:
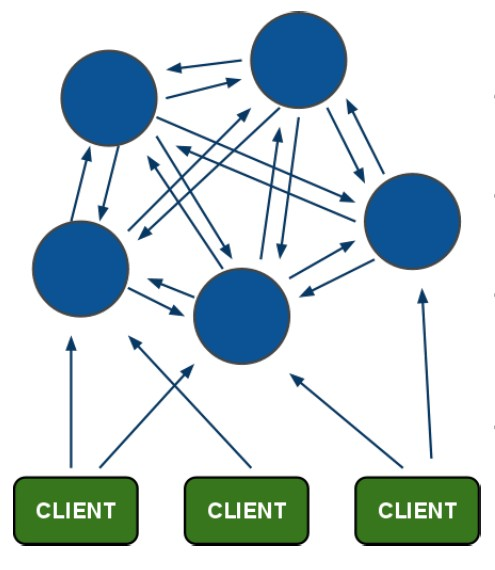
在這個圖中,每一個藍色的圈都代表著一個redis的伺服器節點。它們任何兩個節點之間都是相互連通的。客戶端可以與任何一個節點相連接,然後就可以訪問集群中的任何一個節點。對其進行存取和其他操作。
那麼redis是怎麼做到的呢?首先,在redis的每一個節點上,都有這麼兩個東西,一個是插槽(slot)可以理解為是一個可以存儲兩個數值的一個變數這個變數的取值範圍是:0-16383。還有一個就是cluster我個人把這個cluster理解為是一個集群管理的插件。當我們的存取的key到達的時候,redis會根據crc16的演算法得出一個結果,然後把結果對 16384 求餘數,這樣每個 key 都會對應一個編號在 0-16383 之間的哈希槽,通過這個值,去找到對應的插槽所對應的節點,然後直接自動跳轉到這個對應的節點上進行存取操作。

還有就是因為如果集群的話,是有好多個redis一起工作的,那麼,就需要這個集群不是那麼容易掛掉,所以呢,理論上就應該給集群中的每個節點至少一個備用的redis服務。這個備用的redis稱為從節點(slave)。那麼這個集群是如何判斷是否有某個節點掛掉了呢?
首先要說的是,每一個節點都存有這個集群所有主節點以及從節點的信息。
它們之間通過互相的ping-pong判斷是否節點可以連接上。如果有一半以上的節點去ping一個節點的時候沒有回應,集群就認為這個節點宕機了,然後去連接它的備用節點。如果某個節點和所有從節點全部掛掉,我們集群就進入faill狀態。還有就是如果有一半以上的主節點宕機,那麼我們集群同樣進入發力了狀態。這就是我們的redis的投票機制,具體原理如下圖所示:
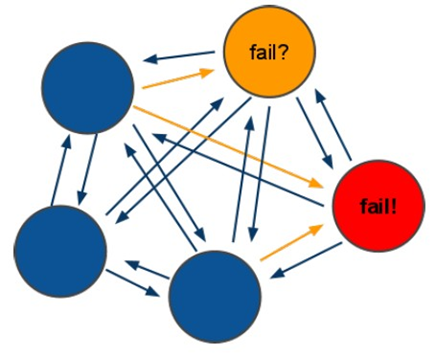
(1)投票過程是集群中所有master參與,如果半數以上master節點與master節點通信超時(cluster-node-timeout),認為當前master節點掛掉.
(2):什麼時候整個集群不可用(cluster_state:fail)?
a:如果集群任意master掛掉,且當前master沒有slave.集群進入fail狀態,也可以理解成集群的slot映射[0-16383]不完整時進入fail狀態. ps : redis-3.0.0.rc1加入cluster-require-full-coverage參數,預設關閉,打開集群相容部分失敗.
b:如果集群超過半數以上master掛掉,無論是否有slave,集群進入fail狀態.


