
當你開始編寫 Apache Spark 代碼或者瀏覽公開的 API 的時候,你會遇到各種各樣術語,比如transformation,action,RDD 等等。 瞭解到這些是編寫 Spark 代碼的基礎。 同樣,當你任務開始失敗或者你需要透過web界面去瞭解自己的應用為何如此費時的時候,你需要去瞭解 ...
當你開始編寫 Apache Spark 代碼或者瀏覽公開的 API 的時候,你會遇到各種各樣術語,比如transformation,action,RDD 等等。 瞭解到這些是編寫 Spark 代碼的基礎。 同樣,當你任務開始失敗或者你需要透過web界面去瞭解自己的應用為何如此費時的時候,你需要去瞭解一些新的名詞: job, stage, task。對於這些新術語的理解有助於編寫良好 Spark 代碼。這裡的良好主要指更快的 Spark 程式。對於 Spark 底層的執行模型的瞭解對於寫出效率更高的 Spark 程式非常有幫助。
Spark 是如何執行程式的
一個 Spark 應用包括一個 driver 進程和若幹個分佈在集群的各個節點上的 executor 進程。
driver 主要負責調度一些高層次的任務流(flow of work)。exectuor 負責執行這些任務,這些任務以 task 的形式存在, 同時存儲用戶設置需要caching的數據。 task 和所有的 executor 的生命周期為整個程式的運行過程(如果使用了dynamic resource allocation 時可能不是這樣的)。如何調度這些進程是通過集群管理應用完成的(比如YARN,Mesos,Spark Standalone),但是任何一個 Spark 程式都會包含一個 driver 和多個 executor 進程。
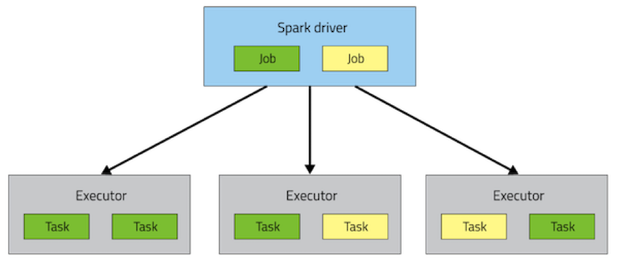
在執行層次結構的最上方是一系列 Job。調用一個Spark內部的 action 會產生一個 Spark job 來完成它。 為了確定這些job實際的內容,Spark 檢查 RDD 的DAG再計算出執行 plan 。這個 plan 以最遠端的 RDD 為起點(最遠端指的是對外沒有依賴的 RDD 或者 數據已經緩存下來的 RDD),產生結果 RDD 的 action 為結束 。
執行的 plan 由一系列 stage 組成,stage 是 job 的 transformation 的組合,stage 對應於一系列 task, task 指的對於不同的數據集執行的相同代碼。每個 stage 包含不需要 shuffle 數據的 transformation 的序列。
什麼決定數據是否需要 shuffle ?RDD 包含固定數目的 partition, 每個 partiton 包含若幹的 record。對於那些通過narrow tansformation(比如 map 和 filter)返回的 RDD,一個 partition 中的 record 只需要從父 RDD 對應的partition 中的 record 計算得到。每個對象只依賴於父 RDD 的一個對象。有些操作(比如 coalesce)可能導致一個 task處理多個輸入 partition ,但是這種 transformation 仍然被認為是 narrow 的,因為用於計算的多個輸入 record 始終是來自有限個數的 partition。
然而 Spark 也支持需要 wide 依賴的 transformation,比如 groupByKey,reduceByKey。在這種依賴中,計算得到一個 partition 中的數據需要從父 RDD 中的多個 partition 中讀取數據。所有擁有相同 key 的元組最終會被聚合到同一個partition 中,被同一個 stage 處理。為了完成這種操作, Spark需要對數據進行 shuffle,意味著數據需要在集群內傳遞,最終生成由新的 partition 集合組成的新的 stage。
舉例,以下的代碼中,只有一個 action 以及 從一個文本串下來的一系列 RDD, 這些代碼就只有一個 stage,因為沒有哪個操作需要從不同的 partition 裡面讀取數據。
sc.textFile("someFile.txt").
map(mapFunc).
flatMap(flatMapFunc).
filter(filterFunc).
count()
跟上面的代碼不同,下麵一段代碼需要統計總共出現超過1000次的單詞:
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))
val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
val filtered = wordCounts.filter(_._2 >= 1000)
val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).
reduceByKey(_ + _)
charCounts.collect()
這段代碼可以分成三個 stage。recudeByKey 操作是各 stage 之間的分界,因為計算 recudeByKey 的輸出需要按照可以重新分配 partition。
這裡還有一個更加複雜的 transfromation 圖,包含一個有多路依賴的 join transformation。

粉紅色的框框展示了運行時使用的 stage 圖。
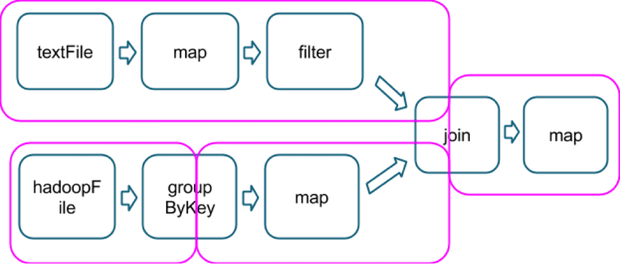
運行到每個 stage 的邊界時,數據在父 stage 中按照 task 寫到磁碟上,而在子 stage 中通過網路按照 task 去讀取數據。這些操作會導致很重的網路以及磁碟的I/O,所以 stage 的邊界是非常占資源的,在編寫 Spark 程式的時候需要儘量避免的。父 stage 中 partition 個數與子 stage 的 partition 個數可能不同,所以那些產生 stage 邊界的 transformation 常常需要接受一個 numPartition 的參數來覺得子 stage 中的數據將被切分為多少個 partition。
正如在調試 MapReduce 是選擇 reducor 的個數是一項非常重要的參數,調整在 stage 邊屆時的 partition 個數經常可以很大程度上影響程式的執行效率。我們會在後面的章節中討論如何調整這些值。
選擇正確的 Operator
當需要使用 Spark 完成某項功能時,程式員需要從不同的 action 和 transformation 中選擇不同的方案以獲得相同的結果。但是不同的方案,最後執行的效率可能有雲泥之別。迴避常見的陷阱選擇正確的方案可以使得最後的表現有巨大的不同。一些規則和深入的理解可以幫助你做出更好的選擇。
在最新的 Spark5097 文檔中開始穩定 SchemaRDD(也就是 Spark 1.3 開始支持的DataFrame),這將為使用 Spark 核心API的程式員打開 Spark的 Catalyst optimizer,允許 Spark 在使用 Operator 時做出更加高級的選擇。當 SchemaRDD穩定之後,某些決定將不需要用戶去考慮了。
選擇 Operator 方案的主要目標是減少 shuffle 的次數以及被 shuffle 的文件的大小。因為 shuffle 是最耗資源的操作,所以有 shuffle 的數據都需要寫到磁碟並且通過網路傳遞。repartition,join,cogroup,以及任何 *By 或者 *ByKey 的transformation 都需要 shuffle 數據。不是所有這些 Operator 都是平等的,但是有些常見的性能陷阱是需要註意的。
- 當進行聯合的規約操作時,避免使用 groupByKey。舉個例子,rdd.groupByKey().mapValues(_ .sum) 與 rdd.reduceByKey(_ + _) 執行的結果是一樣的,但是前者需要把全部的數據通過網路傳遞一遍,而後者只需要根據每個key 局部的 partition 累積結果,在 shuffle 的之後把局部的累積值相加後得到結果。
- 當輸入和輸入的類型不一致時,避免使用 reduceByKey。舉個例子,我們需要實現為每一個key查找所有不相同的 string。一個方法是利用 map 把每個元素的轉換成一個 Set,再使用 reduceByKey 將這些 Set 合併起來
rdd.map(kv => (kv._1, new Set[String]() + kv._2)) .reduceByKey(_ ++ _)
這段代碼生成了無數的非必須的對象,因為每個需要為每個 record 新建一個 Set。這裡使用 aggregateByKey 更加適合,因為這個操作是在 map 階段做聚合。
val zero = new collection.mutable.Set[String]() rdd.aggregateByKey(zero)( (set, v) => set += v, (set1, set2) => set1 ++= set2)
- 避免 flatMap-join-groupBy 的模式。當有兩個已經按照key分組的數據集,你希望將兩個數據集合併,並且保持分組,這種情況可以使用 cogroup。這樣可以避免對group進行打包解包的開銷。
什麼時候不發生 Shuffle
當然瞭解在哪些 transformation 上不會發生 shuffle 也是非常重要的。當前一個 transformation 已經用相同的patitioner 把數據分 patition 了,Spark知道如何避免 shuffle。參考一下代碼:
rdd1 = someRdd.reduceByKey(...) rdd2 = someOtherRdd.reduceByKey(...) rdd3 = rdd1.join(rdd2)
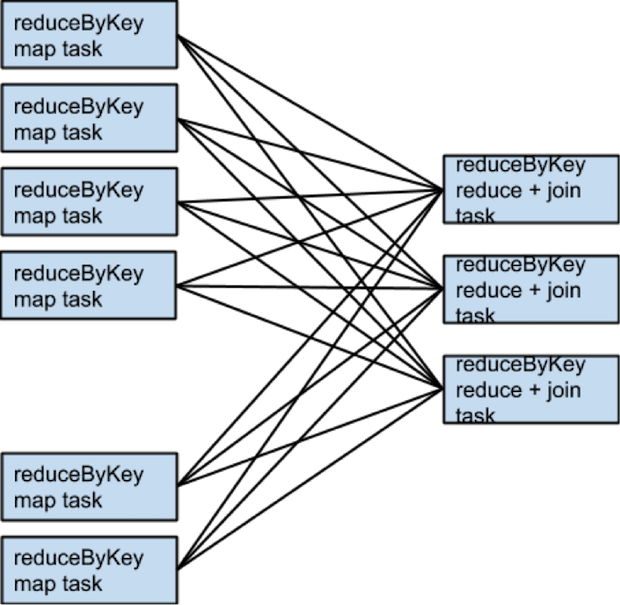
因為沒有 partitioner 傳遞給 reduceByKey,所以系統使用預設的 partitioner,所以 rdd1 和 rdd2 都會使用 hash 進行分 partition。代碼中的兩個 reduceByKey 會發生兩次 shuffle 。如果 RDD 包含相同個數的 partition, join 的時候將不會發生額外的 shuffle。因為這裡的 RDD 使用相同的 hash 方式進行 partition,所以全部 RDD 中同一個 partition 中的 key的集合都是相同的。因此,rdd3中一個 partiton 的輸出只依賴rdd2和rdd1的同一個對應的 partition,所以第三次shuffle 是不必要的。
舉個例子說,當 someRdd 有4個 partition, someOtherRdd 有兩個 partition,兩個 reduceByKey 都使用3個partiton,所有的 task 會按照如下的方式執行:
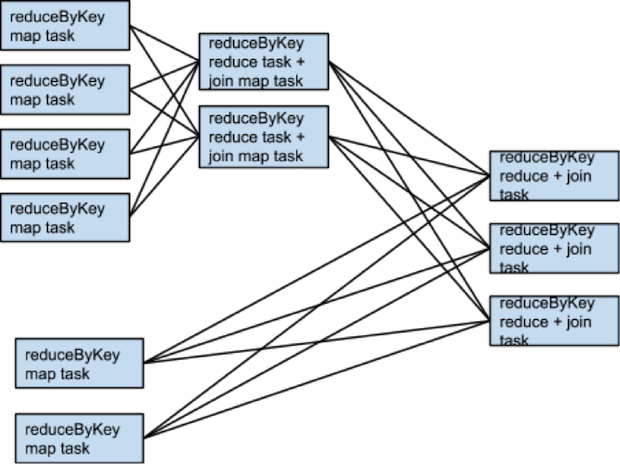
如果 rdd1 和 rdd2 在 reduceByKey 時使用不同的 partitioner 或者使用相同的 partitioner 但是 partition 的個數不同的情況,那麼只有一個 RDD (partiton 數更少的那個)需要重新 shuffle。
相同的 tansformation,相同的輸入,不同的 partition 個數:
當兩個數據集需要 join 的時候,避免 shuffle 的一個方法是使用 broadcast variables。如果一個數據集小到能夠塞進一個executor 的記憶體中,那麼它就可以在 driver 中寫入到一個 hash table中,然後 broadcast 到所有的 executor 中。然後map transformation 可以引用這個 hash table 作查詢。
什麼情況下 Shuffle 越多越好
儘可能減少 shuffle 的準則也有例外的場合。如果額外的 shuffle 能夠增加併發那麼這也能夠提高性能。比如當你的數據保存在幾個沒有切分過的大文件中時,那麼使用 InputFormat 產生分 partition 可能會導致每個 partiton 中聚集了大量的record,如果 partition 不夠,導致沒有啟動足夠的併發。在這種情況下,我們需要在數據載入之後使用 repartiton (會導致shuffle)提高 partiton 的個數,這樣能夠充分使用集群的CPU。
另外一種例外情況是在使用 recude 或者 aggregate action 聚集數據到 driver 時,如果數據把很多 partititon 個數的數據,單進程執行的 driver merge 所有 partition 的輸出時很容易成為計算的瓶頸。為了緩解 driver 的計算壓力,可以使用reduceByKey 或者 aggregateByKey 執行分散式的 aggregate 操作把數據分佈到更少的 partition 上。每個 partition中的數據並行的進行 merge,再把 merge 的結果發個 driver 以進行最後一輪 aggregation。查看 treeReduce 和treeAggregate 查看如何這麼使用的例子。
這個技巧在已經按照 Key 聚集的數據集上格外有效,比如當一個應用是需要統計一個語料庫中每個單詞出現的次數,並且把結果輸出到一個map中。一個實現的方式是使用 aggregation,在每個 partition 中本地計算一個 map,然後在 driver中把各個 partition 中計算的 map merge 起來。另一種方式是通過 aggregateByKey 把 merge 的操作分佈到各個partiton 中計算,然後在簡單地通過 collectAsMap 把結果輸出到 driver 中。
二次排序
還有一個重要的技能是瞭解介面 repartitionAndSortWithinPartitions transformation。這是一個聽起來很晦澀的transformation,但是卻能涵蓋各種奇怪情況下的排序,這個 transformation 把排序推遲到 shuffle 操作中,這使大量的數據有效的輸出,排序操作可以和其他操作合併。
舉例說,Apache Hive on Spark 在join的實現中,使用了這個 transformation 。而且這個操作在 secondary sort 模式中扮演著至關重要的角色。secondary sort 模式是指用戶期望數據按照 key 分組,並且希望按照特定的順序遍歷 value。使用 repartitionAndSortWithinPartitions 再加上一部分用戶的額外的工作可以實現 secondary sort。
在這篇文章中,首先完成在 Part I 中提到的一些東西。作者將儘量覆蓋到影響 Spark 程式性能的方方面面,你們將會瞭解到資源調優,或者如何配置 Spark 以壓榨出集群每一分資源。然後我們將講述調試併發度,這是job性能中最難也是最重要的參數。最後,你將瞭解到數據本身的表達形式,Spark 讀取在磁碟的上的形式(主要是Apache Avro和 Apache Parquet)以及當數據需要緩存或者移動的時候記憶體中的數據形式。調試資源分配
Spark 的用戶郵件郵件列表中經常會出現 “我有一個500個節點的集群,為什麼但是我的應用一次只有兩個 task 在執行”,鑒於 Spark 控制資源使用的參數的數量,這些問題不應該出現。但是在本章中,你將學會壓榨出你集群的每一分資源。推薦的配置將根據不同的集群管理系統( YARN、Mesos、Spark Standalone)而有所不同,我們將主要集中在YARN 上,因為這個 Cloudera 推薦的方式。
我們先看一下在 YARN 上運行 Spark 的一些背景。查看之前的博文:點擊這裡查看
Spark(以及YARN) 需要關心的兩項主要的資源是 CPU 和 記憶體, 磁碟 和 IO 當然也影響著 Spark 的性能,但是不管是 Spark 還是 Yarn 目前都沒法對他們做實時有效的管理。
在一個 Spark 應用中,每個 Spark executor 擁有固定個數的 core 以及固定大小的堆大小。core 的個數可以在執行 spark-submit 或者 pyspark 或者 spark-shell 時,通過參數 --executor-cores 指定,或者在 spark-defaults.conf 配置文件或者 SparkConf 對象中設置 spark.executor.cores 參數。同樣地,堆的大小可以通過 --executor-memory 參數或者 spark.executor.memory 配置項。core 配置項控制一個 executor 中task的併發數。 --executor-cores 5 意味著每個executor 中最多同時可以有5個 task 運行。memory 參數影響 Spark 可以緩存的數據的大小,也就是在 groupaggregate 以及 join 操作時 shuffle 的數據結構的最大值。
--num-executors 命令行參數或者spark.executor.instances 配置項控制需要的 executor 個數。從 CDH 5.4/Spark 1.3 開始,你可以避免使用這個參數,只要你通過設置 spark.dynamicAllocation.enabled 參數打開 動態分配 。動態分配可以使的 Spark 的應用在有後續積壓的在等待的 task 時請求 executor,並且在空閑時釋放這些 executor。
同時 Spark 需求的資源如何跟 YARN 中可用的資源配合也是需要著重考慮的,YARN 相關的參數有:
- yarn.nodemanager.resource.memory-mb 控制在每個節點上 container 能夠使用的最大記憶體;
- yarn.nodemanager.resource.cpu-vcores 控制在每個節點上 container 能夠使用的最大core個數;
請求5個 core 會生成向 YARN 要5個虛擬core的請求。從 YARN 請求記憶體相對比較複雜因為以下的一些原因:
- --executor-memory/spark.executor.memory 控制 executor 的堆的大小,但是 JVM 本身也會占用一定的堆空間,比如內部的 String 或者直接 byte buffer,executor memory 的 spark.yarn.executor.memoryOverhead 屬性決定向 YARN 請求的每個 executor 的記憶體大小,預設值為max(384, 0.7 * spark.executor.memory);
- YARN 可能會比請求的記憶體高一點,YARN 的 yarn.scheduler.minimum-allocation-mb 和 yarn.scheduler.increment-allocation-mb 屬性控制請求的最小值和增加量。
下麵展示的是 Spark on YARN 記憶體結構:
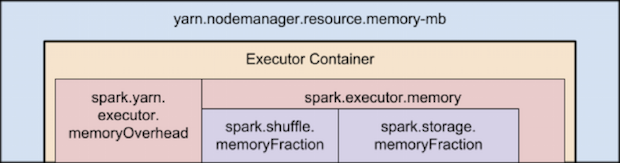
如果這些還不夠決定Spark executor 個數,還有一些概念還需要考慮的:
- 應用的master,是一個非 executor 的容器,它擁有特殊的從 YARN 請求資源的能力,它自己本身所占的資源也需要被計算在內。在 yarn-client 模式下,它預設請求 1024MB 和 1個core。在 yarn-cluster 模式中,應用的 master 運行 driver,所以使用參數 --driver-memory 和 --driver-cores 配置它的資源常常很有用。
- 在 executor 執行的時候配置過大的 memory 經常會導致過長的GC延時,64G是推薦的一個 executor 記憶體大小的上限。
- 我們註意到 HDFS client 在大量併發線程是時性能問題。大概的估計是每個 executor 中最多5個並行的 task 就可以占滿的寫入帶寬。
- 在運行微型 executor 時(比如只有一個core而且只有夠執行一個task的記憶體)扔掉在一個JVM上同時運行多個task的好處。比如 broadcast 變數需要為每個 executor 複製一遍,這麼多小executor會導致更多的數據拷貝。
為了讓以上的這些更加具體一點,這裡有一個實際使用過的配置的例子,可以完全用滿整個集群的資源。假設一個集群有6個節點有NodeManager在上面運行,每個節點有16個core以及64GB的記憶體。那麼 NodeManager的容量:yarn.nodemanager.resource.memory-mb 和 yarn.nodemanager.resource.cpu-vcores 可以設為 63 * 1024 = 64512 (MB) 和 15。我們避免使用 100% 的 YARN container 資源因為還要為 OS 和 hadoop 的 Daemon 留一部分資源。在上面的場景中,我們預留了1個core和1G的記憶體給這些進程。Cloudera Manager 會自動計算並且配置。
所以看起來我們最先想到的配置會是這樣的:--num-executors 6 --executor-cores 15 --executor-memory 63G。但是這個配置可能無法達到我們的需求,因為:
- 63GB+ 的 executor memory 塞不進只有 63GB 容量的 NodeManager;
- 應用的 master 也需要占用一個core,意味著在某個節點上,沒有15個core給 executor 使用;
- 15個core會影響 HDFS IO的吞吐量。
配置成 --num-executors 17 --executor-cores 5 --executor-memory 19G 可能會效果更好,因為:
- 這個配置會在每個節點上生成3個 executor,除了應用的master運行的機器,這台機器上只會運行2個 executor
- --executor-memory 被分成3份(63G/每個節點3個executor)=21。 21 * (1 - 0.07) ~ 19。
調試併發
我們知道 Spark 是一套數據並行處理的引擎。但是 Spark 並不是神奇得能夠將所有計算並行化,它沒辦法從所有的並行化方案中找出最優的那個。每個 Spark stage 中包含若幹個 task,每個 task 串列地處理數據。在調試 Spark 的job時,task的個數可能是決定程式性能的最重要的參數。
那麼這個數字是由什麼決定的呢?在之前的博文中介紹了 Spark 如何將 RDD 轉換成一組 stage。task 的個數與 stage 中上一個 RDD 的 partition 個數相同。而一個 RDD 的 partition 個數與被它依賴的 RDD 的 partition 個數相同,除了以下的情況: coalesce transformation 可以創建一個具有更少 partition 個數的 RDD,union transformation 產出的 RDD的 partition 個數是它父 RDD 的 partition 個數之和, cartesian 返回的 RDD 的 partition 個數是它們的積。
如果一個 RDD 沒有父 RDD 呢? 由 textFile 或者 hadoopFile 生成的 RDD 的 partition 個數由它們底層使用的 MapReduce InputFormat 決定的。一般情況下,每讀到的一個 HDFS block 會生成一個 partition。通過 parallelize 介面生成的 RDD 的 partition 個數由用戶指定,如果用戶沒有指定則由參數 spark.default.parallelism 決定。
要想知道 partition 的個數,可以通過介面 rdd.partitions().size() 獲得。
這裡最需要關心的問題在於 task 的個數太小。如果運行時 task 的個數比實際可用的 slot 還少,那麼程式解沒法使用到所有的 CPU 資源。
過少的 task 個數可能會導致在一些聚集操作時, 每個 task 的記憶體壓力會很大。任何 join,cogroup,*ByKey 操作都會在記憶體生成一個 hash-map或者 buffer 用於分組或者排序。join, cogroup ,groupByKey 會在 shuffle 時在 fetching 端使用這些數據結構, reduceByKey ,aggregateByKey 會在 shuffle 時在兩端都會使用這些數據結構。
當需要進行這個聚集操作的 record 不能完全輕易塞進記憶體中時,一些問題會暴露出來。首先,在記憶體 hold 大量這些數據結構的 record 會增加 GC的壓力,可能會導致流程停頓下來。其次,如果數據不能完全載入記憶體,Spark 會將這些數據寫到磁碟,這會引起磁碟 IO和排序。在 Cloudera 的用戶中,這可能是導致 Spark Job 慢的首要原因。
那麼如何增加你的 partition 的個數呢?如果你的問題 stage 是從 Hadoop 讀取數據,你可以做以下的選項:
- 使用 repartition 選項,會引發 shuffle;
- 配置 InputFormat 用戶將文件分得更小;
- 寫入 HDFS 文件時使用更小的block。
如果問題 stage 從其他 stage 中獲得輸入,引發 stage 邊界的操作會接受一個 numPartitions 的參數,比如
val rdd2 = rdd1.reduceByKey(_ + _, numPartitions = X)
X 應該取什麼值?最直接的方法就是做實驗。不停的將 partition 的個數從上次實驗的 partition 個數乘以1.5,直到性能不再提升為止。
同時也有一些原則用於計算 X,但是也不是非常的有效是因為有些參數是很難計算的。這裡寫到不是因為它們很實用,而是可以幫助理解。這裡主要的目標是啟動足夠的 task 可以使得每個 task 接受的數據能夠都塞進它所分配到的記憶體中。
每個 task 可用的記憶體通過這個公式計算:spark.executor.memory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction)/spark.executor.cores 。 memoryFraction 和 safetyFractio 預設值分別 0.2 和 0.8.
在記憶體中所有 shuffle 數據的大小很難確定。最可行的是找出一個 stage 運行的 Shuffle Spill(memory) 和 Shuffle Spill(Disk) 之間的比例。在用所有shuffle 寫乘以這個比例。但是如果這個 stage 是 reduce 時,可能會有點複雜:
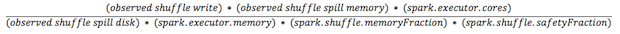
在往上增加一點因為大多數情況下 partition 的個數會比較多。
試試在,在有所疑慮的時候,使用更多的 task 數(也就是 partition 數)都會效果更好,這與 MapRecuce 中建議 task 數目選擇儘量保守的建議相反。這個因為 MapReduce 在啟動 task 時相比需要更大的代價。
壓縮你的數據結構
Spark 的數據流由一組 record 構成。一個 record 有兩種表達形式:一種是反序列化的 Java 對象另外一種是序列化的二進位形式。通常情況下,Spark 對記憶體中的 record 使用反序列化之後的形式,對要存到磁碟上或者需要通過網路傳輸的record 使用序列化之後的形式。也有計劃在記憶體中存儲序列化之後的 record。
spark.serializer 控制這兩種形式之間的轉換的方式。Kryo serializer,org.apache.spark.serializer.KryoSerializer 是推薦的選擇。但不幸的是它不是預設的配置,因為 KryoSerializer 在早期的 Spark 版本中不穩定,而 Spark 不想打破版本的相容性,所以沒有把 KryoSerializer 作為預設配置,但是 KryoSerializer 應該在任何情況下都是第一的選擇。
你的 record 在這兩種形式切換的頻率對於 Spark 應用的運行效率具有很大的影響。去檢查一下到處傳遞數據的類型,看看能否擠出一點水分是非常值得一試的。
過多的反序列化之後的 record 可能會導致數據到處到磁碟上更加頻繁,也使得能夠 Cache 在記憶體中的 record 個數減少。點擊這裡查看如何壓縮這些數據。
過多的序列化之後的 record 導致更多的 磁碟和網路 IO,同樣的也會使得能夠 Cache 在記憶體中的 record 個數減少,這裡主要的解決方案是把所有的用戶自定義的 class 都通過 SparkConf#registerKryoClasses 的API定義和傳遞的。
數據格式
任何時候你都可以決定你的數據如何保持在磁碟上,使用可擴展的二進位格式比如:Avro,Parquet,Thrift或者Protobuf,從中選擇一種。當人們在談論在Hadoop上使用Avro,Thrift或者Protobuf時,都是認為每個 record 保持成一個 Avro/Thrift/Protobuf 結構保存成 sequence file。而不是JSON。
每次當時試圖使用JSON存儲大量數據時,還是先放棄吧...
原文地址:
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-1/
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/

