
本文演示環境為python2.7,主要介紹了python模塊之re正則表達式 ...
一、簡單介紹
正則表達式是一種小型的、高度專業化的編程語言,並不是python中特有的,是許多編程語言中基礎而又重要的一部分。在python中,主要通過re模塊來實現。
正則表達式模式被編譯成一系列的位元組碼,然後由用c編寫的匹配引擎執行。那麼正則表達式通常有哪些使用場景呢?
- 比如為想要匹配的相應字元串集指定規則;
- 該字元串集可以是包含e-mail地址、Internet地址、電話號碼,或是根據需求自定義的一些字元串集;
- 當然也可以去判斷一個字元串集是否符合我們定義的匹配規則;
- 找到字元串中匹配該規則的部分內容;
- 修改、切割等一系列的文本處理;
- ......
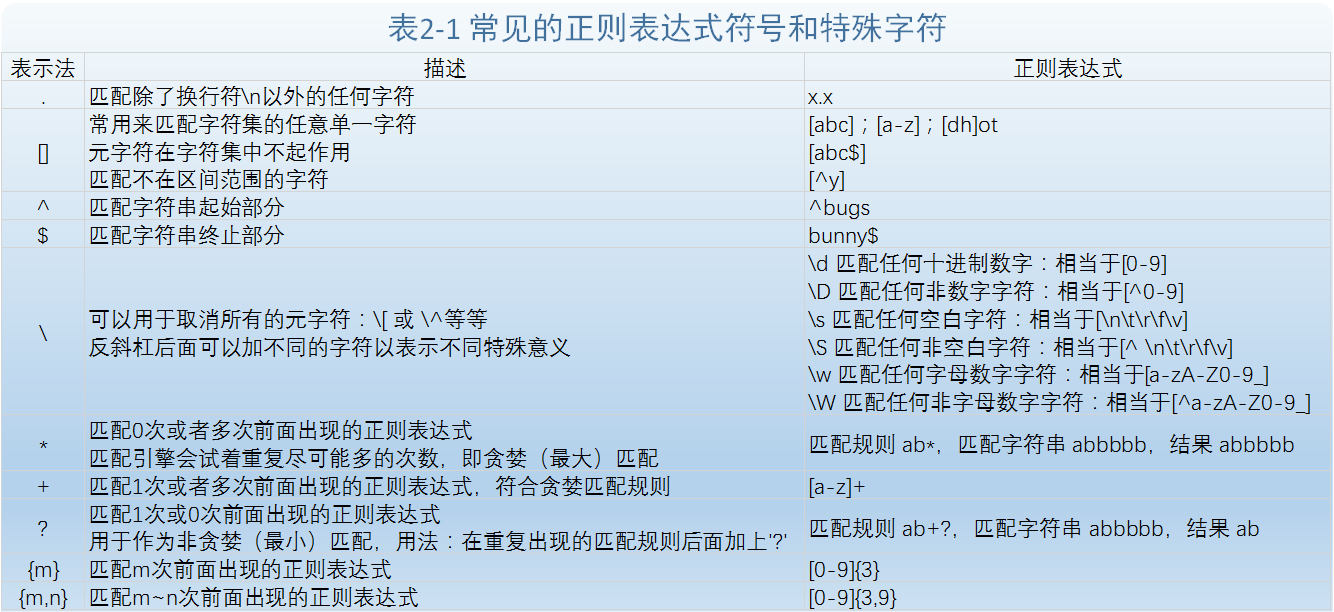
二、特殊符號和字元(元字元)
這裡介紹常見的一些元字元,它給予正則表達式強大的功能和靈活性。表2-1列出了比較常見的符號和字元。
三、正則表達式
1、使用 compile()函數編譯正則表達式
由於python代碼最終會被翻譯成位元組碼,然後在解釋器上執行。所以對於我們代碼中經常要用到的一些正則表達式進行預編譯,執行起來會更加便捷。
re模塊中的大多數函數和已經編譯的正則表達式對象和正則匹配對象的方法同名並且具有相同的功能。
示例:
>>> import re
>>> r1 = r'bugs' # 字元串前加"r"反斜杠就不會被任何特殊方式處理,這是個習慣,雖然這裡沒用到
>>> re.findall(r1, 'bugsbunny') # 直接利用re模塊進行解釋性地匹配
['bugs']
>>>
>>> r2 = re.compile(r1) # 如果r1這個匹配規則你會經常用到,為了提高效率,那就進行預編譯吧
>>> r2 # 編譯後的正則對象
<_sre.SRE_Pattern object at 0x7f5d7db99bb0>
>>>
>>> r2.findall('bugsbunny') # 訪問對象的findall方法得到的匹配結果與上面是一致的
['bugs'] # 所以說,re模塊中的大多數函數和已經編譯的正則表達式對象和正則匹配對象的方法同名並且具有相同的功能
re.compile()函數也接受可選的標誌參數,常用來實現不同的特殊功能和語法變更。這些標誌也可以作為參數適用於大多數re模塊函數。這些標誌可以用操作符(|)合併。
示例:
>>> import re
>>> r1 = r'bugs'
>>> r2 = re.compile(r1,re.I) # 這裡選擇的是忽略大小寫的標誌,完整的是re.IGNORECASE,這裡簡寫re.I
>>> r2.findall('BugsBunny')
['Bugs']
# re.S 使.匹配換行符在內的所有字元
# re.M 多行匹配,英雄^和$
# re,X 用來使正則匹配模式組織得更加清晰
完整的標誌參數列表和用法可以參考相關官方文檔。
2、使用正則表達式
re模塊提供了一個正則表達式引擎的介面,下麵具體介紹一些常用的函數和方法。
- 匹配對象以及group()和groups()方法
當處理正則表達式時,除了正則表達式對象之外,還有一個對象類型:匹配對象。這些是成功調用 match()或者search()返回的對象。匹配對象有兩個主要的方法:group()和groups()。
group()要麼返回整個匹配對象,要麼根據要求返回特定子組。groups()則僅返回一個包含唯一或者全部子組的元組。如果沒有子組的要求,那麼當group()仍然返回整個匹配時,groups返回一個空元組。下麵一些函數示例會演示到此方法。
- 使用 match()方法匹配字元串
match()函數從字元串的起始部分對模式進行匹配。如果匹配成功,就返回一個匹配對象;如果匹配失敗,就返回 None,匹配對象的方法 group()方法就能夠用於顯示那個成功的匹配。
示例如下:
>>> m = re.match('bugs', 'bugsbunny') # 模式匹配字元串
>>> if m is not None: # 如果匹配成功,就輸出匹配內容
... m.group()
...
'bugs'
>>> m
<_sre.SRE_Match object at 0x7f5d7da1f168> # 確認返回的匹配對象
- 使用search()在一個字元串中查找模式
search()的工作方式與match()完全一致,不同之處在於search()是對給定正則表達式模式搜索第一次出現的匹配情況。簡單來說,就是在任意位置符合都能匹配成功,不僅僅是字元串的起始部分,這就是與match()函數的區別,用腳指頭想想search()方法使用的範圍更多更廣。
示例:
>>> m = re.search('bugs', 'hello bugsbunny')
>>> if m is not None:
... m.group()
...
'bugs'
- 使用findall()和finditer()查找每一次出現的位置
findall()是用來查找字元串中所有(非重覆)出現的正則表達式模式,並返回一個匹配列表;finditer()與findall()不同的地方是返回一個迭代器,對於每一次匹配,迭代器都返回一個匹配對象。
>>> m = re.findall('bugs', 'bugsbunnybugs')
>>> m
['bugs', 'bugs']
>>> m = re.finditer('bugs', 'bugsbunnybugs')
>>> m.next() # 迭代器用next()方法返回一個匹配對象
<_sre.SRE_Match object at 0x7f5d7da71a58> # 匹配用group()方法顯示出來
>>> m.next().group()
'bugs'
- 使用sub()和subn()搜索與替換
都是將某字元串中所有匹配正則表達式的部分進行某種形式的替換。sub()返回一個用來替換的字元串,可以定義替換次數,預設替換所有出現的位置。subn()和sub()一樣,但subn()還返回一個表示替換的總是,替換後的字元串和表示替換總數一起作為一個擁有兩個元素的元組返回。
示例:
>>> r = 'a.b'
>>> m = 'acb abc aab aac'
>>> re.sub(r,'hello',m)
'hello abc hello aac'
>>> re.subn(r,'hello',m)
('hello abc hello aac', 2)
字元串也有一個replace()方法,當遇到一些模糊搜索替換的時候,就需要更為靈活的sub()方法了。
- 使用split()分割字元串
同樣的,字元串中也有split(),但它也不能處理正則表達式匹配的分割。在re模塊中,分居正則表達式的模式分隔符,split函數將字元串分割為列表,然後返回成功匹配的列表。
示例:
>>> s = '1+2-3*4' >>> re.split(r'[\+\-\*]',s) ['1', '2', '3', '4']
- 分組
有時在匹配的時候我們只想提取一些想要的信息或者對提取的信息作一個分類,這時就需要對正則匹配模式進行分組,只需要加上()即可。
示例:
>>> m = re.match('(\w{3})-(\d{3})','abc-123')
>>> m.group() # 完整匹配
'abc-123'
>>> m.group(1) # 子組1
'abc'
>>> m.group(2) # 子組2
'123'
>>> m.groups() # 全部子組
('abc', '123')
由以上的例子可以看出,group()通常用於以普通方式顯示所有的匹配部分,但也能用於獲取各個匹配的子組。可以使用groups()方法來獲取一個包含所有匹配字元串的元組。


