
一、 Storm整體介紹 Storm 是一個類似Hadoop MapReduce的系統, 用戶按照指定的介面實現一個任務,然後將這個任務遞交給JStorm系統,Jstorm將這個任務跑起來,並且按7 * 24小時運行起來,一旦中間一個Worker 發生意外故障, 調度器立即分配一個新的Worker替
一、 Storm整體介紹
Storm 是一個類似Hadoop MapReduce的系統, 用戶按照指定的介面實現一個任務,然後將這個任務遞交給JStorm系統,Jstorm將這個任務跑起來,並且按7 * 24小時運行起來,一旦中間一個Worker 發生意外故障, 調度器立即分配一個新的Worker替換這個失效的Worker。
因此,從應用的角度,JStorm 應用是一種遵守某種編程規範的分散式應用。從系統角度, JStorm一套類似MapReduce的調度系統。 從數據的角度, 是一套基於流水線的消息處理機制。
實時計算現在是大數據領域中最火爆的一個方向,因為人們對數據的要求越來越高,實時性要求也越來越快,傳統的Hadoop MapReduce,逐漸滿足不了需求,因此在這個領域需求不斷。
1.1. Storm組件和Hadoop組件對比
|
Storm |
Hadoop |
|
|
角色 |
Nimbus |
JobTracker |
|
Supervisor |
TaskTracker |
|
|
Worker |
Child |
|
|
應用名稱 |
Topology |
Job |
|
編程介面 |
Spout/Bolt |
Mapper/Reducer |
1.2. 優點
在Storm和JStorm出現以前,市面上出現很多實時計算引擎,但自Storm和JStorm出現後,基本上可以說一統江湖: 究其優點:
- 開發非常迅速:介面簡單,容易上手,只要遵守Topology、Spout和Bolt的編程規範即可開發出一個擴展性極好的應用,底層RPC、Worker之間冗餘,數據分流之類的動作完全不用考慮
- 擴展性極好:當一級處理單元速度,直接配置一下併發數,即可線性擴展性能
- 健壯強:當Worker失效或機器出現故障時, 自動分配新的Worker替換失效Worker
- 數據準確性:可以採用Ack機制,保證數據不丟失。 如果對精度有更多一步要求,採用事務機制,保證數據準確。
二、 安裝
參考文檔:
https://github.com/alibaba/jstorm/wiki/%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85
三、 storm詳細講解
3.1. storm的整體架構
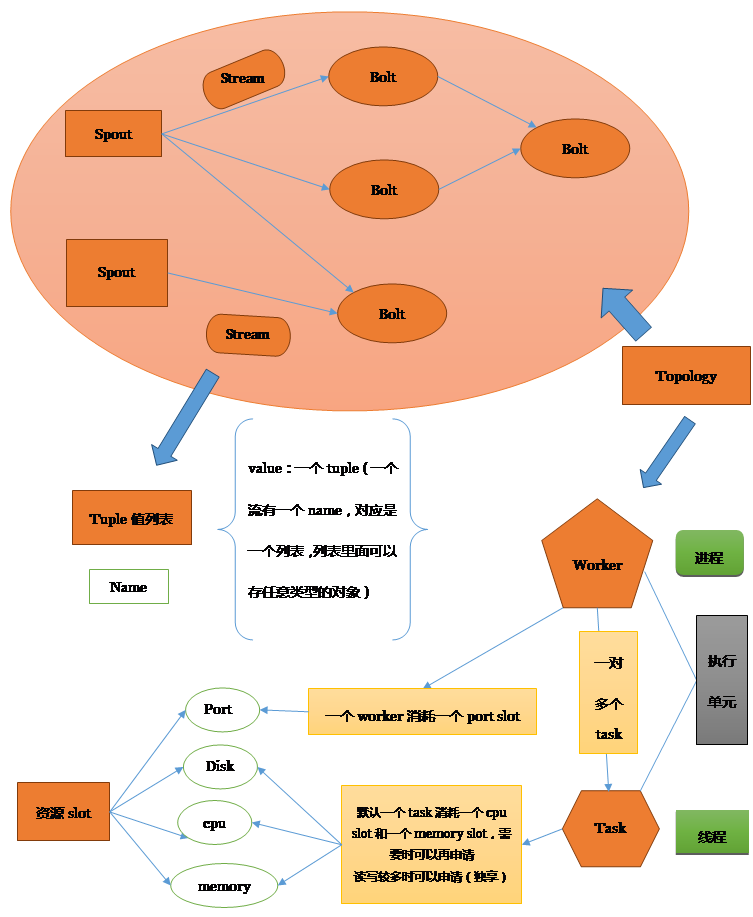
3.2. 基本概念簡介
圖中  這種顏色標識的是storm中的基本組件,包括:
這種顏色標識的是storm中的基本組件,包括:
Topology,bolt,spout,worker,task,slot,stream,tuple
3.2.1. Topology
Storm的核心是topology,程式以topology作為一個整體提交到集群上

3.2.2. Spout
數據流入口:spout程式負責從數據源讀入數據,然後發射出去,形成一個stream流,可以被多個bolt接受,形成多個流
3.2.3. Bout
數據的消費者,從stream流中讀取數據,處理數據
可以從不同的流中讀取數據
3.2.4. Stream
Spout發射的數據形成數據流,
3.2.5. Worker
可以理解為一個topology承包給多少個包工頭(worker)
3.2.6. Task
可以理解為工人,一個worker下麵有多個task,每個task運行一個bolt或spout的實例
3.3. Bolt,spout和worker,task的關係



