
過了今天就2017了,做點什麼呢,寫點年終總結、個人小目標、或者?!今天窗外陽光十分的好,又恰逢周末,算了,還是用2016底的一次SQL Server資料庫性能調優經歷來做了結,告別2016! 內容摘要: 一、性能問題描述 二、監測分析 三、等待類型分析 四、優化方案 五、優化效果 一、性能問題描述 ...
每次經曆數據庫性能調優,都是對性能優化的再次認識、對自己知識不足的有力驗證,只有不斷總結、學習才能少走彎路。
內容摘要:
一、性能問題描述
應用端反應系統查詢緩慢,長時間出不來結果。SQLServer資料庫伺服器吞吐量不足,CPU資源不足,經常飆到100%.......
二、監測分析
收集性能數據採用二種方式:連續一段時間收集和高峰期實時收集
連續一天收集性能指標(以下簡稱“連續監測”)
目的: 通過此方式得到CPU/記憶體/磁碟/SQLServer總體情況,巨集觀上分析當前伺服器的主要的性能瓶頸。
工具: 性能計數器 Perfmon+PAL日誌分析器(工具使用方法請參考另外一篇博文)
配置:
-
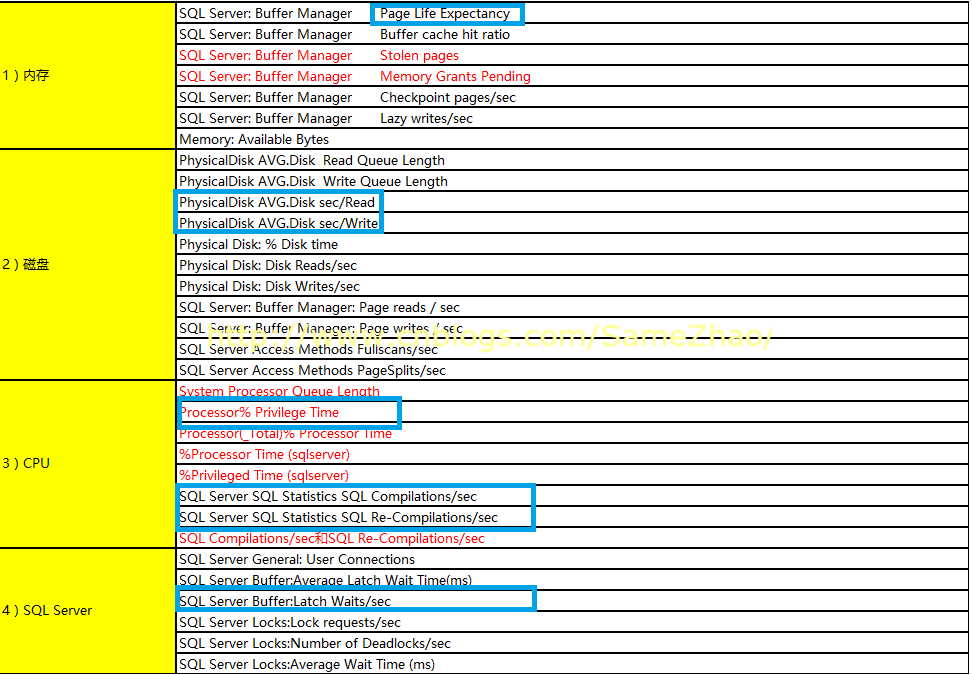
Perfmon配置主要性能計數器內容具體如下表
-
Perfmon收集的時間間隔:15秒 (不宜過短,否則會對伺服器性能造成額外壓力)
-
收集時間: 8:00~20:00業務時間,收集一天
分析監測結果
收集完成後,通過PAL(一款日誌分析工具,可見一篇博文介紹)工具自動分析出結果,顯示主要性能問題:
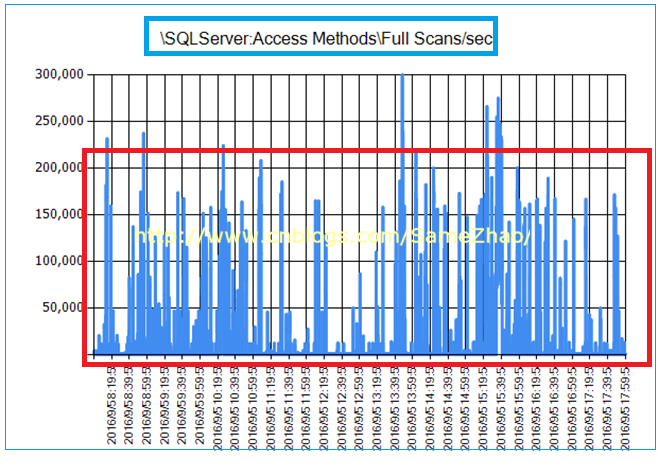
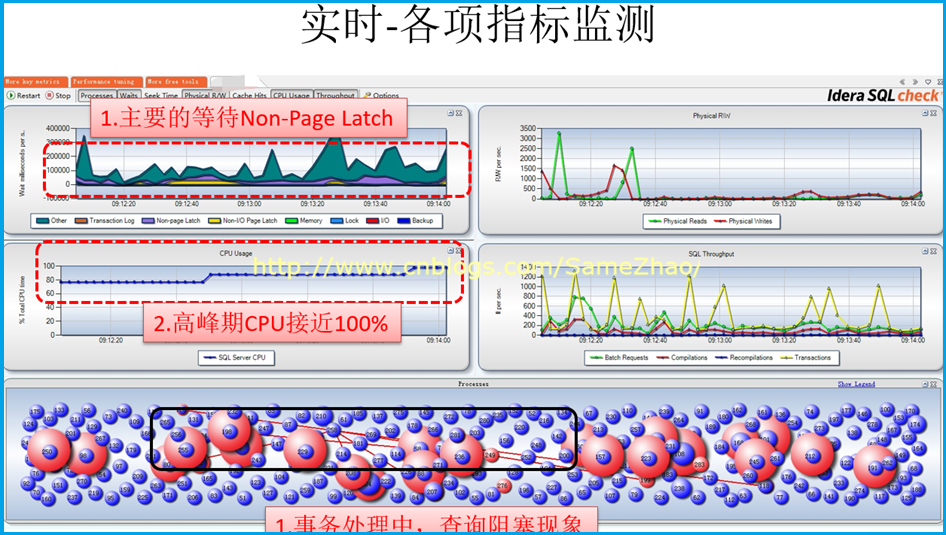
業務高峰期CPU接近100%,並伴隨較多的Latch(閂鎖)等待,查詢時有大量的掃表操作。這些只是巨集觀上得到的“現象級“的性能問題表現,並不能一定說明是CPU資源不夠導致的,需要進一步找證據分析。
PAL分析得出幾個突出性能問題
1. 業務高峰期CPU接近瓶頸:CPU平均在60%左右,高峰在80%以上,極端達到100%

2. Latch等待一直持續存在,平均在>500。Non-Page Latch等待嚴重


4. SQL編譯和反編譯參數高於正常

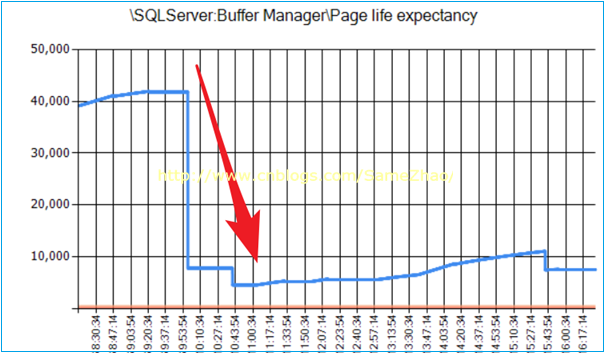
5.PLE即頁在記憶體中的生命周期,其數量從某個時間點出現斷崖式下降
其數量從早上某個時間點下降後直持續到下午4點,說明這段時間記憶體中頁面切換比較頻繁,出現從磁碟讀取大量頁數據到記憶體,很可能是大面積掃表導致。
實時監測性能指標
目的: 根據“連續監測“已知的業務高峰期PeakTime主要發生時段,接下來通過實時監測重點關註這段時間各項指標,進一步確認問題。
工具: SQLCheck(工具使用請見另外一篇 博文介紹)
配置: 客戶端連接到SQLCheck配置
小貼士:建議不要在當前伺服器運行,可選擇另外一臺機器運行SQLCheck
分析監測結果
實時監測顯示Non-Page Latch等待嚴重,這點與上面“連續監測”得到結果一直
Session之間阻塞現象時常發生,經分析是大的結果集查詢阻塞了別的查詢、更新、刪除操作導致
詳細分析
資料庫存存在大量表掃描操作,導致緩存中數據不能滿足查詢,需要從磁碟中讀取數據,產生IO等待導致阻塞。
1. Non-Page Latch等待時間長
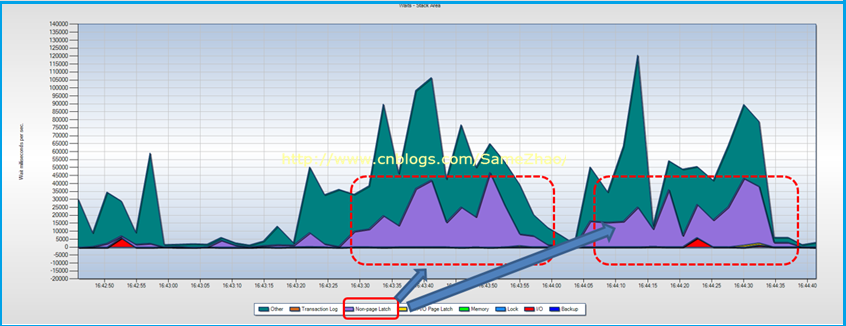
2. 當 Non-Page Latch等待發生時候,實時監測顯示正在執行大的查詢操作

3. 伴有session之間阻塞現象,在大的查詢時發生阻塞現象,CPU也隨之飆到95%以上
解決方案
找到問題語句,創建基於條件的索引來減少掃描,並更新統計信息。
上面方法還無法解決,考慮將受影響的數據轉移到更快的IO子系統,考慮增加記憶體。
三、等待類型分析
通過等待類型,換個角度進一步分析到底時哪些資源出現瓶頸
工具: DMV/DMO
操作:
1. 先清除歷史等待數據
選擇早上8點左右執行下麵語句
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
2. 晚上8點左右執行,執行下麵語句收集Top 10的等待類型信息統計。


WITH [Waits] AS ( SELECT [wait_type] , [wait_time_ms] / 1000.0 AS [WaitS] , ( [wait_time_ms] - [signal_wait_time_ms] ) / 1000.0 AS [ResourceS] , [signal_wait_time_ms] / 1000.0 AS [SignalS] , [waiting_tasks_count] AS [WaitCount] , 100.0 * [wait_time_ms] / SUM([wait_time_ms]) OVER ( ) AS [Percentage] , ROW_NUMBER() OVER ( ORDER BY [wait_time_ms] DESC ) AS [RowNum] FROM sys.dm_os_wait_stats WHERE [wait_type] NOT IN ( N'CLR_SEMAPHORE', N'LAZYWRITER_SLEEP', N'RESOURCE_QUEUE', N'SQLTRACE_BUFFER_FLUSH', N'SLEEP_TASK', N'SLEEP_SYSTEMTASK', N'WAITFOR', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'CHECKPOINT_QUEUE', N'REQUEST_FOR_DEADLOCK_SEARCH', N'XE_TIMER_EVENT', N'XE_DISPATCHER_JOIN', N'LOGMGR_QUEUE', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'BROKER_TASK_STOP', N'CLR_MANUAL_EVENT', N'CLR_AUTO_EVENT', N'DISPATCHER_QUEUE_SEMAPHORE', N'TRACEWRITE', N'XE_DISPATCHER_WAIT', N'BROKER_TO_FLUSH', N'BROKER_EVENTHANDLER', N'FT_IFTSHC_MUTEX', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', N'DIRTY_PAGE_POLL', N'SP_SERVER_DIAGNOSTICS_SLEEP' ) ) SELECT [W1].[wait_type] AS [WaitType] , CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S] , CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S] , CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S] , [W1].[WaitCount] AS [WaitCount] , CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage] , CAST (( [W1].[WaitS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgWait_S] , CAST (( [W1].[ResourceS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgRes_S] , CAST (( [W1].[SignalS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgSig_S] FROM [Waits] AS [W1] INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum] GROUP BY [W1].[RowNum] , [W1].[wait_type] , [W1].[WaitS] , [W1].[ResourceS] , [W1].[SignalS] , [W1].[WaitCount] , [W1].[Percentage] HAVING SUM([W2].[Percentage]) - [W1].[Percentage] <95; -- percentage threshold GOView Code
3.提取信息

查詢結果得出排名:
1:CXPACKET
2:LATCH_X
3:IO_COMPITION
4:SOS_SCHEDULER_YIELD
5: ASYNC_NETWORK_IO
6. PAGELATCH_XX
7/8.PAGEIOLATCH_XX
跟主要資源相關的等待方陣如下:
CPU相關:CXPACKET 和SOS_SCHEDULER_YIELD
IO相關: PAGEIOLATCH_XX\IO_COMPLETION
Memory相關: PAGELATCH_XX、LATCH_X
進一步分析前幾名等待類型
當前排前三位:CXPACKET、LATCH_EX、IO_COMPLETION等待,開始一個個分析其產生等待背後原因
小貼士:關於等待類型的知識學習,可參考Paul Randal的系列文章。
CXPACKET等待分析
CXPACKET等待排第1位, SOS_SCHEDULER_YIELD排在4位,伴有第7、8位的PAGEIOLATCH_XX等待。發生了並行操作worker被阻塞
說明:
1. 存在大範圍的表Scan
2. 某些並行線程執行時間過長,這個要將PAGEIOLATCH_XX和非頁閂鎖Latch_XX的ACCESS_METHODS_DATASET_PARENT Latch結合起來看,後面會給到相關信息
3. 執行計劃不合理的可能
分析:
1. 首先看一下花在執行等待和資源等待的時間
2. PAGEIOLATCH_XX是否存在,PAGEIOLATCH_SH等待,這意味著大範圍SCAN
3. 是否同時有ACCESS_METHODS_DATASET_PARENT Latch或ACCESS_METHODS_SCAN_RANGE_GENERATOR LATCH等待
4. 執行計劃是否合理
信提取息:
獲取CPU的執行等待和資源等待的時間所占比重
執行下麵語句:
--CPU Wait Queue (threshold:<=6) select scheduler_id,idle_switches_count,context_switches_count,current_tasks_count, active_workers_count from sys.dm_os_schedulers where scheduler_id<255
SELECT sum(signal_wait_time_ms) as total_signal_wait_time_ms, sum(wait_time_ms-signal_wait_time_ms) as resource_wait_time_percent, sum(signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 as signal_wait_percent, sum(wait_time_ms-signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 as resource_wait_percent FROM SYS.dm_os_wait_stats
![]()
結論:從下表收集到信息CPU主要花在資源等待上,而執行時候等待占比率小,所以不能武斷認為CPU資源不夠。
造成原因:
缺少聚集索引、不准確的執行計劃、並行線程執行時間過長、是否存在隱式轉換、TempDB資源爭用
解決方案:
主要從如何減少CPU花在資源等待的時間
1. 設置查詢的MAXDOP,根據CPU核數設置合適的值(解決多CPU並行處理出現水桶短板現象)
2. 檢查”cost threshold parallelism”的值,設置為更合理的值
3. 減少全表掃描:建立合適的聚集索引、非聚集索引,減少全表掃描
4. 不精確的執行計劃:選用更優化執行計劃
5. 統計信息:確保統計信息是最新的
6. 建議添加多個Temp DB 數據文件,減少Latch爭用,最佳實踐:>8核數,建議添加4個或8個等大小的數據文件
LATCH_EX等待分析
LATCH_EX等待排第2位。
說明:
有大量的非頁閂鎖等待,首先確認是哪一個閂鎖等待時間過長,是否同時發生CXPACKET等待類型。
分析:
查詢所有閂鎖等待信息,發現ACCESS_METHODS_DATASET_PARENT等待最長,查詢相關資料顯示因從磁碟->IO讀取大量的數據到緩存,結合與之前Perfmon結果做綜合分析判斷,判斷存在大量掃描。
運行腳本
SELECT * FROM sys.dm_os_latch_stats
信提取息:
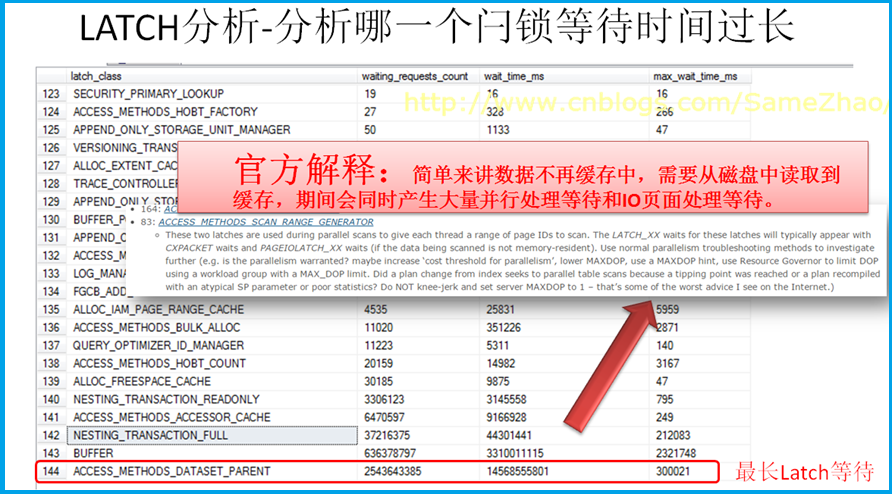
造成原因:
有大量的並行處理等待、IO頁面處理等待,這進一步推定存在大範圍的掃描表操作。
與開發人員確認存儲過程中使用大量的臨時表,並監測到業務中處理用頻繁使用臨時表、標量值函數,不斷創建用戶對象等,TEMPDB 處理記憶體相關PFS\GAM\SGAM時,有很多內部資源申請徵用的Latch等待現象。
解決方案:
1. 優化TempDB
2. 創建非聚集索引來減少掃描
3. 更新統計信息
4. 在上面方法仍然無法解決,可將受影響的數據轉移到更快的IO子系統,考慮增加記憶體
IO_COMPLETION等待分析
現象:
IO_COMPLETION等待排第3位
說明:
IO延遲問題,數據從磁碟到記憶體等待時間長
分析:
從資料庫的文件讀寫效率分析哪個比較慢,再與“CXPACKET等待分析”的結果合起來分析。
Temp IO讀/寫資源效率
1. TempDB的數據文件的平均IO在80左右,這個超出一般值,TempDB存在嚴重的延遲。
2. TempDB所在磁碟的Read latency為65,也比一般值偏高。
運行腳本:
1 --資料庫文件讀寫IO性能 2 SELECT DB_NAME(fs.database_id) AS [Database Name], CAST(fs.io_stall_read_ms/(1.0 + fs.num_of_reads) AS NUMERIC(10,1)) AS [avg_read_stall_ms], 3 CAST(fs.io_stall_write_ms/(1.0 + fs.num_of_writes) AS NUMERIC(10,1)) AS [avg_write_stall_ms], 4 CAST((fs.io_stall_read_ms + fs.io_stall_write_ms)/(1.0 + fs.num_of_reads + fs.num_of_writes) AS NUMERIC(10,1)) AS [avg_io_stall_ms], 5 CONVERT(DECIMAL(18,2), mf.size/128.0) AS [File Size (MB)], mf.physical_name, mf.type_desc, fs.io_stall_read_ms, fs.num_of_reads, 6 fs.io_stall_write_ms, fs.num_of_writes, fs.io_stall_read_ms + fs.io_stall_write_ms AS [io_stalls], fs.num_of_reads + fs.num_of_writes AS [total_io] 7 FROM sys.dm_io_virtual_file_stats(null,null) AS fs 8 INNER JOIN sys.master_files AS mf WITH (NOLOCK) 9 ON fs.database_id = mf.database_id 10 AND fs.[file_id] = mf.[file_id] 11 ORDER BY avg_io_stall_ms DESC OPTION (RECOMPILE); 12 13 --驅動磁碟-IO文件情況 14 SELECT [Drive], 15 CASE 16 WHEN num_of_reads = 0 THEN 0 17 ELSE (io_stall_read_ms/num_of_reads) 18 END AS [Read Latency], 19 CASE 20 WHEN io_stall_write_ms = 0 THEN 0 21 ELSE (io_stall_write_ms/num_of_writes) 22 END AS [Write Latency], 23 CASE 24 WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 25 ELSE (io_stall/(num_of_reads + num_of_writes)) 26 END AS [Overall Latency], 27 CASE 28 WHEN num_of_reads = 0 THEN 0 29 ELSE (num_of_bytes_read/num_of_reads) 30 END AS [Avg Bytes/Read], 31 CASE 32 WHEN io_stall_write_ms = 0 THEN 0 33 ELSE (num_of_bytes_written/num_of_writes) 34 END AS [Avg Bytes/Write], 35 CASE 36 WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 37 ELSE ((num_of_bytes_read + num_of_bytes_written)/(num_of_reads + num_of_writes)) 38 END AS [Avg Bytes/Transfer] 39 FROM (SELECT LEFT(mf.physical_name, 2) AS Drive, SUM(num_of_reads) AS num_of_reads, 40 SUM(io_stall_read_ms) AS io_stall_read_ms, SUM(num_of_writes) AS num_of_writes, 41 SUM(io_stall_write_ms) AS io_stall_write_ms, SUM(num_of_bytes_read) AS num_of_bytes_read, 42 SUM(num_of_bytes_written) AS num_of_bytes_written, SUM(io_stall) AS io_stall 43 FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS vfs 44 INNER JOIN sys.master_files AS mf WITH (NOLOCK) 45 ON vfs.database_id = mf.database_id AND vfs.file_id = mf.file_id 46 GROUP BY LEFT(mf.physical_name, 2)) AS tab 47 ORDER BY [Overall Latency] OPTION (RECOMPILE);View Code
信提取息:
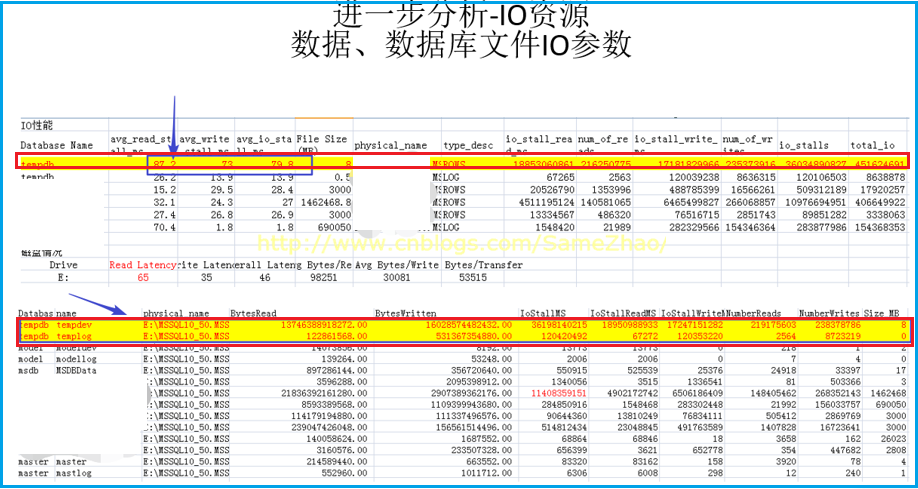
各數據文件IO/CPU/Buffer訪問情況,Temp DB的IO Rank達到53%以上



