
轉發請註明引用和原文博客(http://www.cnblogs.com/wenBlog) 簡介 之前已經寫過兩篇介紹列存儲索引的文章,但是只有非聚集列存儲索引,今天再來簡單介紹一下聚集的列存儲索引,也就是可更新列存儲索引。在SQL Server 2012中首次引入了基於列存儲數據格式的存儲方式。叫做 ...
轉發請註明引用和原文博客(http://www.cnblogs.com/wenBlog)
簡介
之前已經寫過兩篇介紹列存儲索引的文章,但是只有非聚集列存儲索引,今天再來簡單介紹一下聚集的列存儲索引,也就是可更新列存儲索引。在SQL Server 2012中首次引入了基於列存儲數據格式的存儲方式。叫做“列存儲索引”。前一篇我已經比較了行存儲索引與非聚集的列存儲索引(http://www.cnblogs.com/wenBlog/p/5682024.html)。其中對於在小表的指定值或者小範圍的查詢來講,尤其針對事務性的負載行存儲是很合適的。但是對於分析性負載像數據倉庫和BI,在查詢中將會對大量數據進行全掃描,例如事實表,這時候列存儲索引就是更好地選擇。
列存儲索引結構
在列存儲索引中,數據按照獨立列組織到一起形成索引結構。每列都數據都位於被高度壓縮的數據集中,叫做數據段。這個數據段只包含該列的值,對於大型表它分到多個數據段中,每個數據段中只含有100萬行數據,這就叫做行組、數據段由一個或者多個數據頁組成。數據將在記憶體和硬碟上以數據段的形式傳輸。
這種索引提高了數據倉庫的查詢效率。這種通過壓縮獲得數據格式要比B-Tree結構的壓縮率高7倍多。同時由於列存儲索引使用了批處理模式執行,數據處理也是批處理的,較少了CPU的使用。列存儲索引強化了檢索數據的速度,與行存儲不同的是不用查詢所有列。因為這個原因,更少數據被讀取到記憶體中,再到處理器緩存處理。相關的這些因素都會減少硬碟IO,提高整體查詢的性能。
在2014中列存儲索引有以下限制:
最多支持1024列在你的索引中;
列存儲索引不能被定義為唯一性索引;
不能創建視圖;
不能包含稀疏列;
不能使用ALTER INDEX來修改索引,只能drop然後重新創建;
不能使用INCLUDE關鍵字。
不能排序列;
不能使用FILESTREAM屬性。
當然還有一些數據類型不能包含在列存儲索引中(binary , varbinary , ntext , text, , image, varchar(max) , nvarchar(max), uniqueidentifier, rowversion , sql_variant,精度大於18 的decimal,CLR 和xml等)
另一方面,對於索引列900位元組的限制也不適用與列存儲索引。
在SQL Server2012 中,只能創建非聚集列存儲索引,並且不能更新。為了更新你必須刪除索引,然後進行插入、更新或者刪除的操作後在重建索引。
在2014中列存儲索引得到了不小的提升,比如消除了只讀限制。增加了聚集列存儲索引,列存儲索引作為了表的存儲方式,存儲表的數據。
比較聚集和非聚集列存儲索引
區別 |
聚集列存儲索引 |
非聚集列存儲索引 |
| 索引列 | 需要指定列上創建 | 所有列都包含在內 |
| 存儲 | 額外增加百分之10的空間作為索引 | 壓縮十倍的數據量,如果表之前是頁壓縮,則可以壓縮5倍左右 |
| 更新 | 是 | 否 |
| 排序 | 在創建之前進行排序 | 否 |
列存儲索引的結構圖:
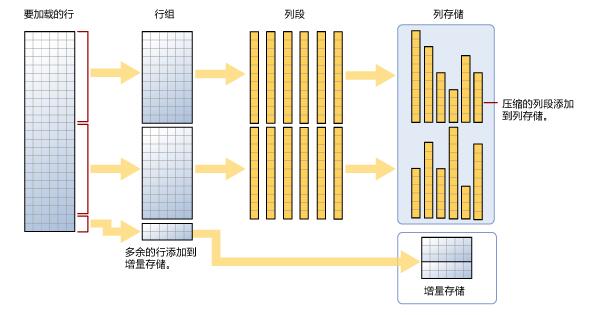
如圖增量存儲部分我們叫做deltastore,用於存儲不夠最小行組大小的數據。流程就是將行數據提取成列數據,然後進行壓縮存儲,多餘的部分放到deltastore中。
聚集索引插入、刪除和更新實現邏輯:
插入新行的時候,值被存儲在deltastore中,直到達到最小rowgroup(行組)大小時,然後壓縮並移動到列存儲數據段中。
刪除數據時,行將被刪除從deltastore存儲中,但是在列存儲索引數據段中只是被標記為刪除,除非重建後才會被真的刪除。
更新的時候,在deltastore存儲中行數據被刪除,然後在列存儲數據段中被標記為刪除,新的列別插入到deltastore中。
最後當重建索引的時。SQLServer將會刪除所有標記為刪除的數據段,數據存儲在deltastore中的將與數據段中的數據合併,然後進行壓縮。
下麵我們來展示下如何從列存儲索引中獲得性能:
我們首先創建一個事實表在資料庫中腳本如下:
1 USE SQLShackDemo 2 3 GO 4 --創建表 5 CREATE TABLE [dbo].[FactFinance]( 6 7 [FinanceKey] [int] NOT NULL, 8 9 [DateKey] [int] NOT NULL, 10 11 [OrganizationKey] [int] NOT NULL, 12 13 [DepartmentGroupKey] [int] NOT NULL, 14 15 [ScenarioKey] [int] NOT NULL, 16 17 [AccountKey] [int] NOT NULL, 18 19 [Amount] [float] NOT NULL, 20 21 [Date] [datetime] NULL 22 23 ) ON [PRIMARY] 24 25 GO 26 27 --創建聚集索引: 28 29 CREATE CLUSTERED INDEX [IX_FactFinance_FinanceKey_DateKey] ON [dbo].[FactFinance] ( [FinanceKey],[DateKey]) 30 GO 31 32 33 --查詢表: 34 35 SELECT [FinanceKey] 36 37 ,[DateKey] 38 39 ,[OrganizationKey] 40 41 ,[DepartmentGroupKey] 42 43 FROM [FactFinance]

讓我們檢查下聚集索引掃描操作符,Estimated I/O Cost(估計IO花銷) 的值為0.183866,Estimated CPU Cost(估計CPU花銷)為0.0435069,為了比較列索引的值,我們先記住:

現在我們創建列存儲索引在非聚集索引:
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey] ON [FactFinance] ([FinanceKey],[DateKey],[OrganizationKey],[DepartmentGroupKey]) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance]

這個列存儲索引掃描操作符如下所示:
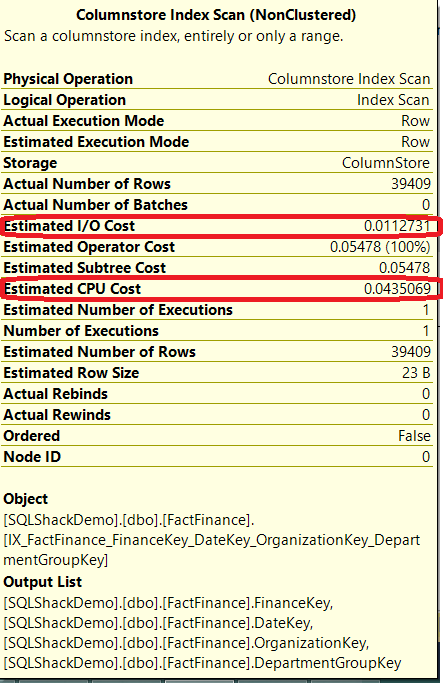
如上所示,Estimated I/O Cost從0.183866下降到0.0112731,這是因為SQL引擎只檢索需要的列,節省了IO和記憶體資源。Estimated CPU的時間沒有變化。
IO強化與之前相比是明顯的,我們也可以比較兩個查詢,啟用I/O statistics,檢查IO的hits 表現如下:
SET STATISTICS IO ON GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index (IX_FactFinance_FinanceKey_DateKey)) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index(IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey))
正如所示,比較執行計劃,使用列存儲索引的要比行索引的好四倍,那麼期望一下處理大數據時的10倍性能:
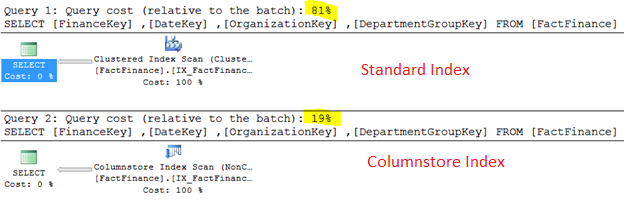
當比較邏輯讀時你也能發現相似的結果。明顯這個邏輯讀也是四倍+關係。

那麼我們可以根據下圖概括一下傳統的行索引與列存儲所以的一般性區別:

列存儲索引的創建
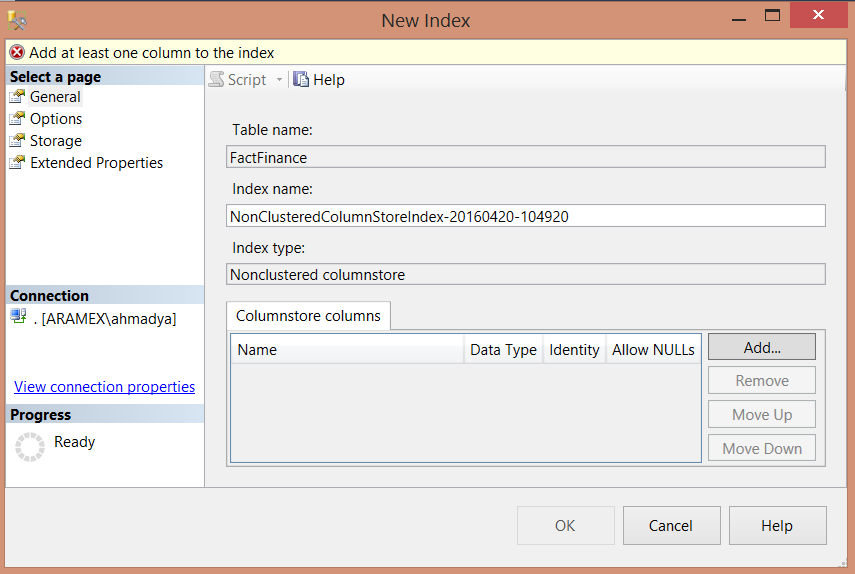
也能夠使用SSMS創建索引: Indexes -> New Index ->Non-Clustered Columnstore Index 如下:
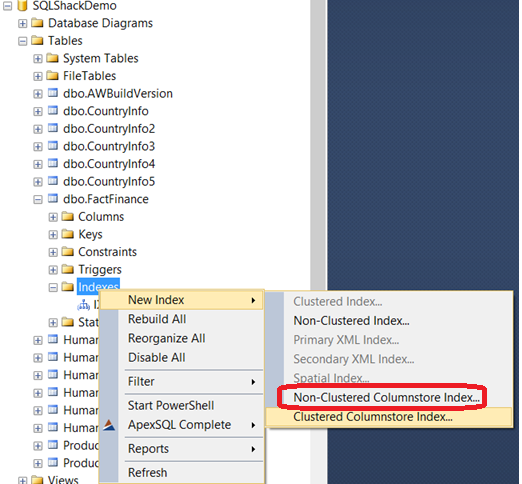
與非聚集索引創建類似,選擇列,然後這些列沒有排序也不能使用Include選項:
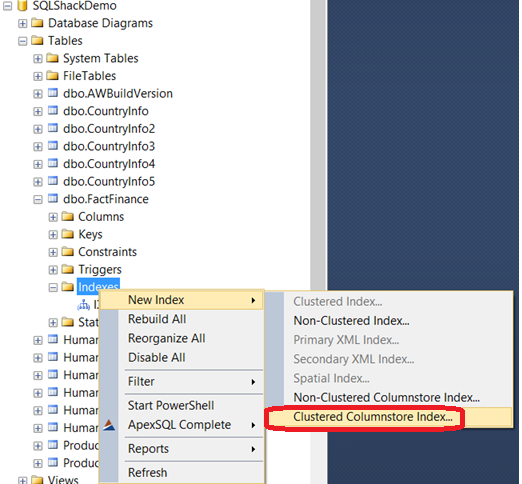
下圖中我在SQL Server2014 企業版中,創建聚集索引:
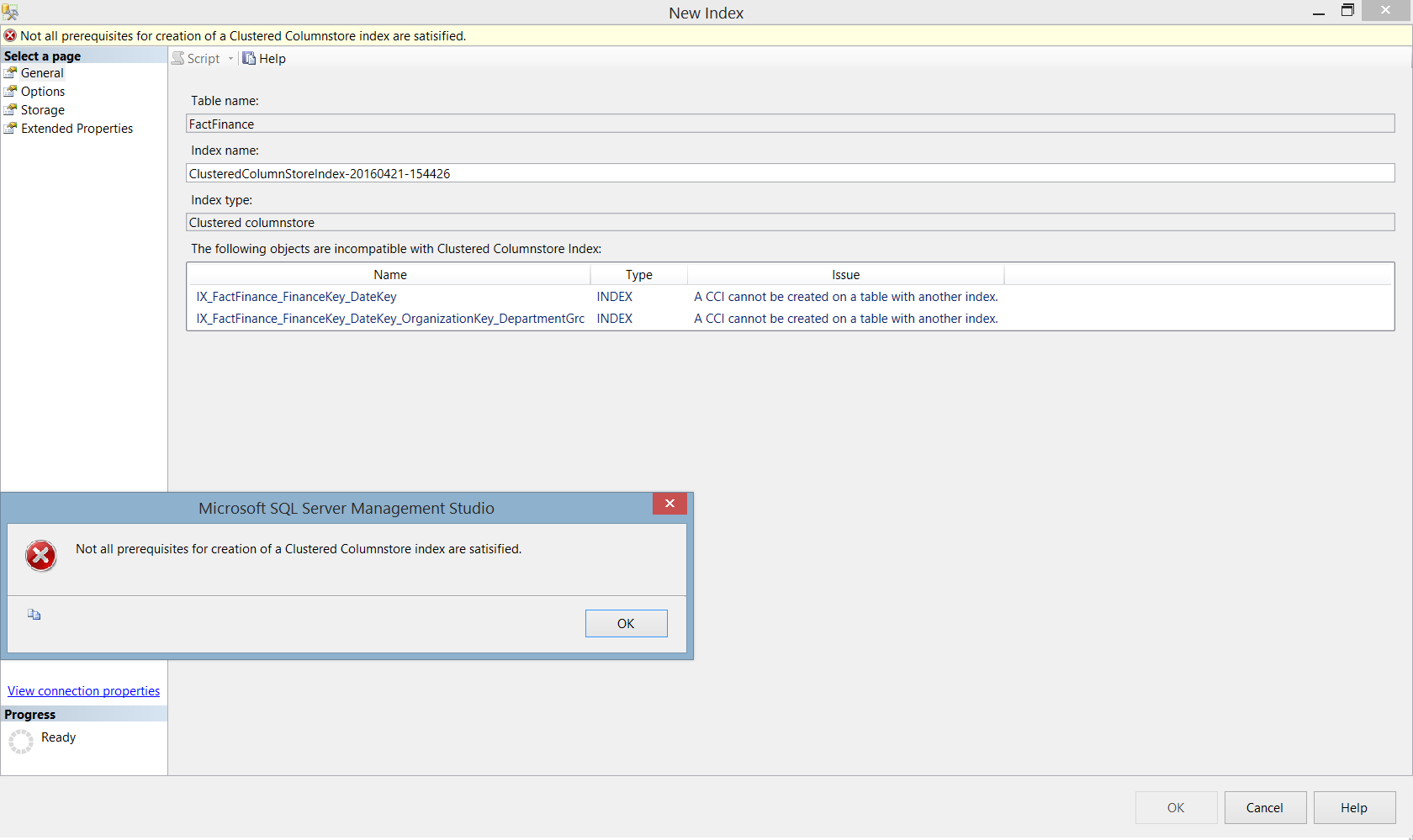
需要註意的是如果在表上已經有其他索引,嘗試創建聚集列存儲索引就會出現錯誤,正如我們之前說的,同一個表中不能或者其他索引:
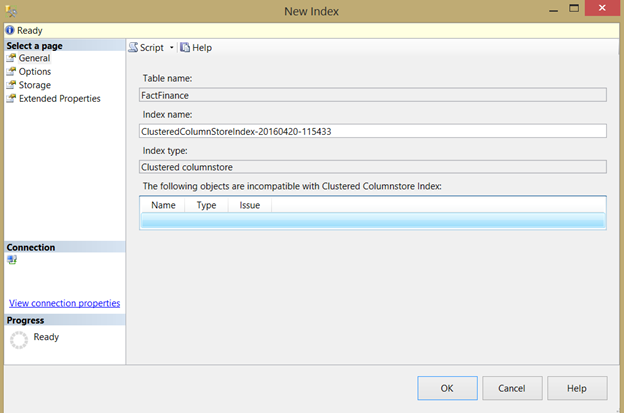
不用選擇列,所有數據都包含在內了:
幾個好的應用場景:
如果你有大型的事實表並且存在查詢問題的,或者SSAS存在其他性能問題的,列存儲是一個不錯的方案。一下兩種情況是經過測試的比較好的應用場景:
- 對於高頻率響應的報表/儀錶板,尤其分析當性能表現不佳的時候,會有很不錯的性能。
- 對於ETL的過程來講,源數據的列存儲索引將會極大提高性能,如果數據足夠大甚至可以考慮臨時創建列存儲索引。然後執行ETL。
總結:
列存儲索引是一個使用SQL Server性能優化的方案,通過減少IO消耗,尤其對數據倉庫和BI查詢都是由明顯性能提升。它通過排序數據作為列存儲,然後壓縮,並使用批處理來處理數據。當然,必須要確保使用列存儲索引的使用帶來了好處,而不會引起其他性能問題才能使用。比如需要註意使用的硬體環境和數據,如果沒有join、過濾、或者聚合導出巨大的數據量沒有足夠的記憶體則將被暫時放入硬碟進行switch off,從而引起查詢性能下降。儘量在使用之前在測試環境中測試是否適合使用,同時還要關註其他環節是否受影響。
補充,在2016中增加的幾個我認為不錯新的feature:
基於聚集列存儲索引的 B 樹索引;
基於記憶體優化表的列存儲索引;
CREATE TABLE 和 ALTER TABLE 中的列存儲索引的壓縮延遲選項;
單線程查詢的批處理執行。


