
隨著樂視硬體搶購的不斷升級,樂視集團支付面臨的請求壓力百倍乃至千倍的暴增。作為商品購買的最後一環,保證用戶快速穩定地完成支付尤為重要。所以在2015年11月,我們對整個支付系統進行了全面的架構升級,使之具備了每秒穩定處理10萬訂單的能力。為樂視生態各種形式的搶購秒殺活動提供了強有力的支撐。 一. 分 ...
隨著樂視硬體搶購的不斷升級,樂視集團支付面臨的請求壓力百倍乃至千倍的暴增。作為商品購買的最後一環,保證用戶快速穩定地完成支付尤為重要。所以在2015年11月,我們對整個支付系統進行了全面的架構升級,使之具備了每秒穩定處理10萬訂單的能力。為樂視生態各種形式的搶購秒殺活動提供了強有力的支撐。
一. 分庫分表
在Redis,memcached等緩存系統盛行的互聯網時代,構建一個支撐每秒十萬隻讀的系統並不複雜,無非是通過一致性哈希擴展緩存節點,水平擴展web伺服器等。支付系統要處理每秒十萬筆訂單,需要的是每秒數十萬的資料庫更新操作(insert加update),這在任何一個獨立資料庫上都是不可能完成的任務,所以我們首先要做的是對訂單表(簡稱order)進行分庫與分表。
在進行資料庫操作時,一般都會有用戶ID(簡稱uid)欄位,所以我們選擇以uid進行分庫分表。
分庫策略我們選擇了“二叉樹分庫”,所謂“二叉樹分庫”指的是:我們在進行資料庫擴容時,都是以2的倍數進行擴容。比如:1台擴容到2台,2台擴容到4台,4台擴容到8台,以此類推。這種分庫方式的好處是,我們在進行擴容時,只需DBA進行表級的數據同步,而不需要自己寫腳本進行行級數據同步。
光是有分庫是不夠的,經過持續壓力測試我們發現,在同一資料庫中,對多個表進行併發更新的效率要遠遠大於對一個表進行併發更新,所以我們在每個分庫中都將order表拆分成10份:order_0,order_1,....,order_9。
最後我們把order表放在了8個分庫中(編號1到8,分別對應DB1到DB8),每個分庫中10個分表(編號0到9,分別對應order_0到order_9),部署結構如下圖所示:
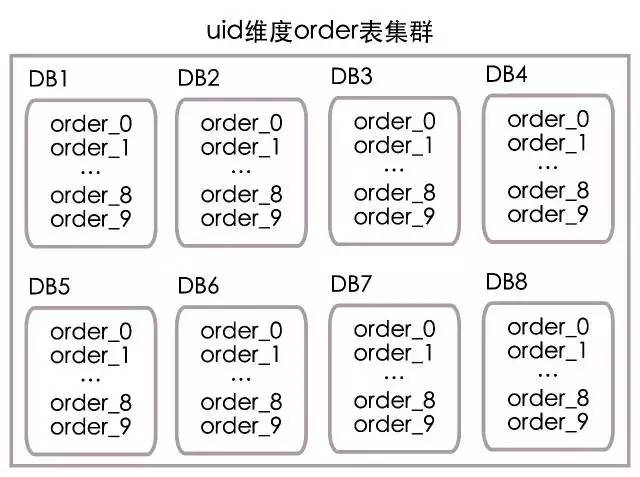
根據uid計算資料庫編號:
資料庫編號 = (uid / 10) % 8 + 1
根據uid計算表編號:
表編號 = uid % 10
當uid=9527時,根據上面的演算法,其實是把uid分成了兩部分952和7,其中952模8加1等於1為資料庫編號,而7則為表編號。所以uid=9527的訂單信息需要去DB1庫中的order_7表查找。具體演算法流程也可參見下圖:

有了分庫分表的結構與演算法最後就是尋找分庫分表的實現工具,目前市面上約有兩種類型的分庫分表工具:
1.客戶端分庫分表,在客戶端完成分庫分表操作,直連資料庫
2.使用分庫分表中間件,客戶端連分庫分表中間件,由中間件完成分
庫分表操作
這兩種類型的工具市面上都有,這裡不一一列舉,總的來看這兩類工具各有利弊。客戶端分庫分表由於直連資料庫,所以性能比使用分庫分表中間件高15%到20%。而使用分庫分表中間件由於進行了統一的中間件管理,將分庫分表操作和客戶端隔離,模塊劃分更加清晰,便於DBA進行統一管理。
我們選擇的是在客戶端分庫分表,因為我們自己開發並開源了一套數據層訪問框架,它的代號叫“芒果”,芒果框架原生支持分庫分表功能,並且配置起來非常簡單。
芒果主頁:mango.jfaster.org
芒果源碼:github.com/jfaster/mango
二. 訂單ID
訂單系統的ID必須具有全局唯一的特征,最簡單的方式是利用資料庫的序列,每操作一次就能獲得一個全局唯一的自增ID,如果要支持每秒處理10萬訂單,那每秒將至少需要生成10萬個訂單ID,通過資料庫生成自增ID顯然無法完成上述要求。所以我們只能通過記憶體計算獲得全局唯一的訂單ID。
Java領域最著名的唯一ID應該算是UUID了,不過UUID太長而且包含字母,不適合作為訂單ID。通過反覆比較與篩選,我們借鑒了Twitter的Snowflake演算法,實現了全局唯一ID。下麵是訂單ID的簡化結構圖:

上圖分為3個部分:
1
時間戳
這裡時間戳的粒度是毫秒級,生成訂單ID時,使用System.currentTimeMillis()作為時間戳
2
機器號
每個訂單伺服器都將被分配一個唯一的編號,生成訂單ID時,直接使用該唯一編號作為機器號即可。
3
自增序號
當在同一伺服器的同一毫秒中有多個生成訂單ID的請求時,會在當前毫秒下自增此序號,下一個毫秒此序號繼續從0開始。比如在同一伺服器同一毫秒有3個生成訂單ID的請求,這3個訂單ID的自增序號部分將分別是0,1,2。
上面3個部分組合,我們就能快速生成全局唯一的訂單ID。不過光全局唯一還不夠,很多時候我們會只根據訂單ID直接查詢訂單信息,這時由於沒有uid,我們不知道去哪個分庫的分表中查詢,遍歷所有的庫的所有表?這顯然不行。所以我們需要將分庫分表的信息添加到訂單ID上,下麵是帶分庫分表信息的訂單ID簡化結構圖:

我們在生成的全局訂單ID頭部添加了分庫與分表的信息,這樣只根據訂單ID,我們也能快速的查詢到對應的訂單信息。
分庫分表信息具體包含哪些內容?第一部分有討論到,我們將訂單表按uid維度拆分成了8個資料庫,每個資料庫10張表,最簡單的分庫分表信息只需一個長度為2的字元串即可存儲,第1位存資料庫編號,取值範圍1到8,第2位存表編號,取值範圍0到9。
還是按照第一部分根據uid計算資料庫編號和表編號的演算法,當uid=9527時,分庫信息=1,分表信息=7,將他們進行組合,兩位的分庫分表信息即為"17"。具體演算法流程參見下圖:
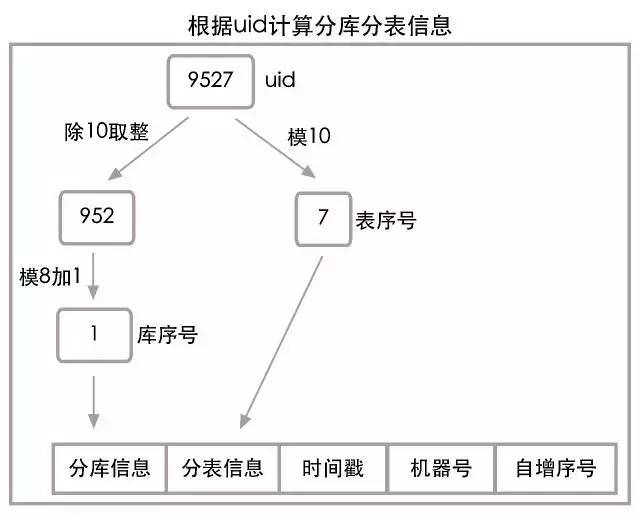
上述使用表編號作為分表信息沒有任何問題,但使用資料庫編號作為分庫信息卻存在隱患,考慮未來的擴容需求,我們需要將8庫擴容到16庫,這時取值範圍1到8的分庫信息將無法支撐1到16的分庫場景,分庫路由將無法正確完成,我們將上訴問題簡稱為分庫信息精度丟失。
為解決分庫信息精度丟失問題,我們需要對分庫信息精度進行冗餘,即我們現在保存的分庫信息要支持以後的擴容。這裡我們假設最終我們會擴容到64台資料庫,所以新的分庫信息演算法為:
分庫信息 = (uid / 10) % 64 + 1
當uid=9527時,根據新的演算法,分庫信息=57,這裡的57並不是真正資料庫的編號,它冗餘了最後擴展到64台資料庫的分庫信息精度。我們當前只有8台資料庫,實際資料庫編號還需根據下麵的公式進行計算:
實際資料庫編號 = (分庫信息 - 1) % 8 + 1
當uid=9527時,分庫信息=57,實際資料庫編號=1,分庫分表信息="577"。
由於我們選擇模64來保存精度冗餘後的分庫信息,保存分庫信息的長度由1變為了2,最後的分庫分表信息的長度為3。具體演算法流程也可參見下圖:
如上圖所示,在計算分庫信息的時候採用了模64的方式冗餘了分庫信息精度,這樣當我們的系統以後需要擴容到16庫,32庫,64庫都不會再有問題。
上面的訂單ID結構已經能很好的滿足我們當前與之後的擴容需求,但考慮到業務的不確定性,我們在訂單ID的最前方加了1位用於標識訂單ID的版本,這個版本號屬於冗餘數據,目前並沒有用到。下麵是最終訂單ID簡化結構圖:

Snowflake演算法:github.com/twitter/snowflake
三. 最終一致性
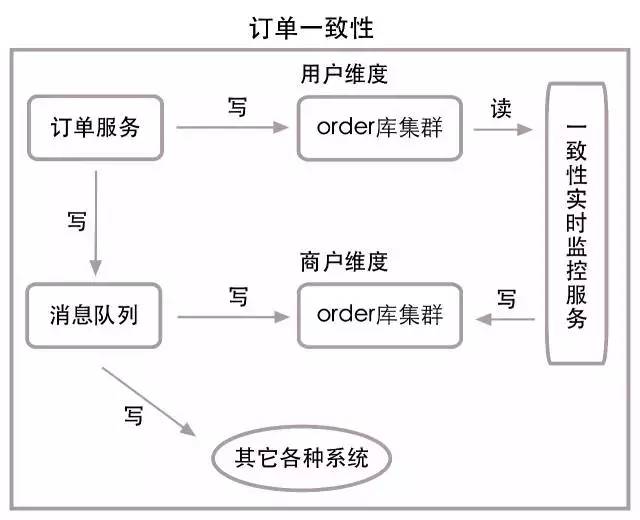
到目前為止,我們通過對order表uid維度的分庫分表,實現了order表的超高併發寫入與更新,並能通過uid和訂單ID查詢訂單信息。但作為一個開放的集團支付系統,我們還需要通過業務線ID(又稱商戶ID,簡稱bid)來查詢訂單信息,所以我們引入了bid維度的order表集群,將uid維度的order表集群冗餘一份到bid維度的order表集群中,要根據bid查詢訂單信息時,只需查bid維度的order表集群即可。
上面的方案雖然簡單,但保持兩個order表集群的數據一致性是一件很麻煩的事情。兩個表集群顯然是在不同的資料庫集群中,如果在寫入與更新中引入強一致性的分散式事務,這無疑會大大降低系統效率,增長服務響應時間,這是我們所不能接受的,所以我們引入了消息隊列進行非同步數據同步,來實現數據的最終一致性。當然消息隊列的各種異常也會造成數據不一致,所以我們又引入了實時監控服務,實時計算兩個集群的數據差異,併進行一致性同步。
下麵是簡化的一致性同步圖:
四. 資料庫高可用
沒有任何機器或服務能保證線上上穩定運行不出故障。比如某一時間,某一資料庫主庫宕機,這時我們將不能對該庫進行讀寫操作,線上服務將受到影響。
所謂資料庫高可用指的是:當資料庫由於各種原因出現問題時,能實時或快速的恢複數據庫服務並修補數據,從整個集群的角度看,就像沒有出任何問題一樣。需要註意的是,這裡的恢複數據庫服務並不一定是指修複原有資料庫,也包括將服務切換到另外備用的資料庫。
資料庫高可用的主要工作是資料庫恢復與數據修補,一般我們以完成這兩項工作的時間長短,作為衡量高可用好壞的標準。這裡有一個惡性迴圈的問題,資料庫恢復的時間越長,不一致數據越多,數據修補的時間就會越長,整體修複的時間就會變得更長。所以資料庫的快速恢覆成了資料庫高可用的重中之重,試想一下如果我們能在資料庫出故障的1秒之內完成資料庫恢復,修複不一致的數據和成本也會大大降低。
下圖是一個最經典的主從結構:
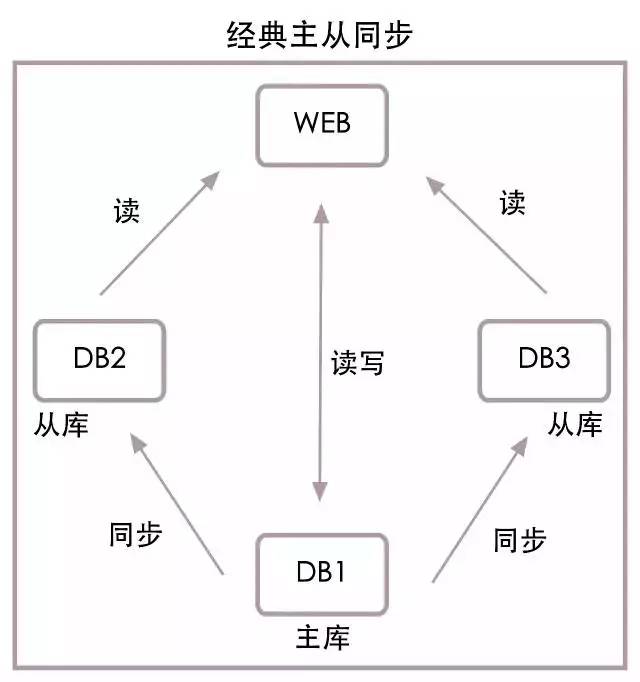
上圖中有1台web伺服器和3台資料庫,其中DB1是主庫,DB2和DB3是從庫。我們在這裡假設web伺服器由項目組維護,而資料庫伺服器由DBA維護。
當從庫DB2出現問題時,DBA會通知項目組,項目組將DB2從web服務的配置列表中刪除,重啟web伺服器,這樣出錯的節點DB2將不再被訪問,整個資料庫服務得到恢復,等DBA修複DB2時,再由項目組將DB2添加到web服務。
當主庫DB1出現問題時,DBA會將DB2切換為主庫,並通知項目組,項目組使用DB2替換原有的主庫DB1,重啟web伺服器,這樣web服務將使用新的主庫DB2,而DB1將不再被訪問,整個資料庫服務得到恢復,等DBA修複DB1時,再將DB1作為DB2的從庫即可。
上面的經典結構有很大的弊病:不管主庫或從庫出現問題,都需要DBA和項目組協同完成資料庫服務恢復,這很難做到自動化,而且恢復工程也過於緩慢。
我們認為,資料庫運維應該和項目組分開,當資料庫出現問題時,應由DBA實現統一恢復,不需要項目組操作服務,這樣便於做到自動化,縮短服務恢復時間。
先來看從庫高可用結構圖:
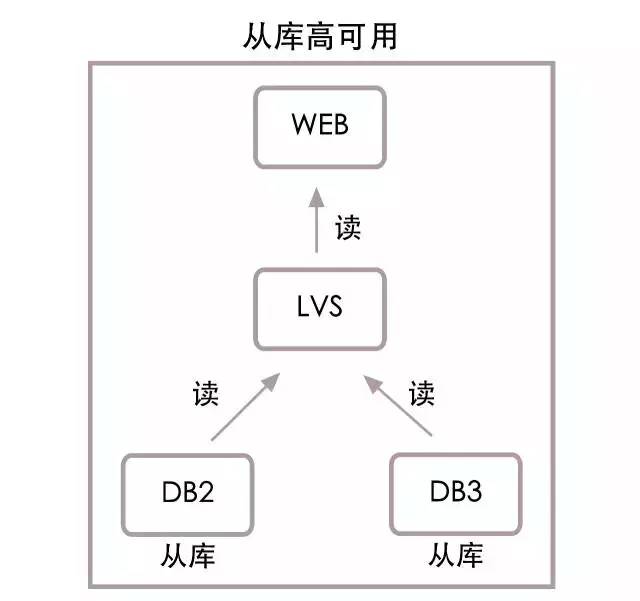
如上圖所示,web伺服器將不再直接連接從庫DB2和DB3,而是連接LVS負載均衡,由LVS連接從庫。這樣做的好處是LVS能自動感知從庫是否可用,從庫DB2宕機後,LVS將不會把讀數據請求再發向DB2。同時DBA需要增減從庫節點時,只需獨立操作LVS即可,不再需要項目組更新配置文件,重啟伺服器來配合。
再來看主庫高可用結構圖:
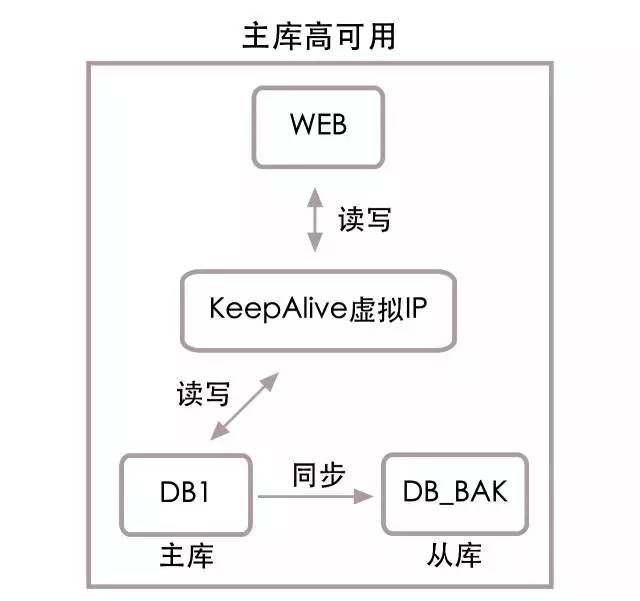
如上圖所示,web伺服器將不再直接連接主庫DB1,而是連接KeepAlive虛擬出的一個虛擬ip,再將此虛擬ip映射到主庫DB1上,同時添加DB_bak從庫,實時同步DB1中的數據。正常情況下web還是在DB1中讀寫數據,當DB1宕機後,腳本會自動將DB_bak設置成主庫,並將虛擬ip映射到DB_bak上,web服務將使用健康的DB_bak作為主庫進行讀寫訪問。這樣只需幾秒的時間,就能完成主資料庫服務恢復。
組合上面的結構,得到主從高可用結構圖:
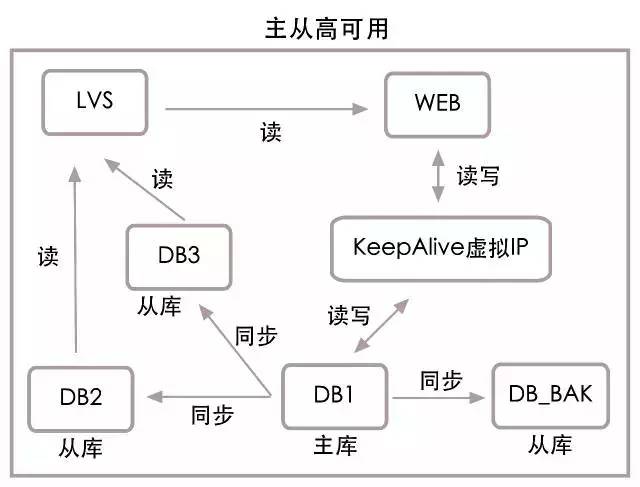
資料庫高可用還包含數據修補,由於我們在操作核心數據時,都是先記錄日誌再執行更新,加上實現了近乎實時的快速恢複數據庫服務,所以修補的數據量都不大,一個簡單的恢復腳本就能快速完成數據修複。
五. 數據分級
支付系統除了最核心的支付訂單表與支付流水錶外,還有一些配置信息表和一些用戶相關信息表。如果所有的讀操作都在資料庫上完成,系統性能將大打折扣,所以我們引入了數據分級機制。
我們簡單的將支付系統的數據劃分成了3級:
第1級:訂單數據和支付流水數據;這兩塊數據對實時性和精確性要求很高,所以不添加任何緩存,讀寫操作將直接操作資料庫。
第2級:用戶相關數據;這些數據和用戶相關,具有讀多寫少的特征,所以我們使用redis進行緩存。
第3級:支付配置信息;這些數據和用戶無關,具有數據量小,頻繁讀,幾乎不修改的特征,所以我們使用本地記憶體進行緩存。
使用本地記憶體緩存有一個數據同步問題,因為配置信息緩存在記憶體中,而本地記憶體無法感知到配置信息在資料庫的修改,這樣會造成資料庫中數據和本地記憶體中數據不一致的問題。
為瞭解決此問題,我們開發了一個高可用的消息推送平臺,當配置信息被修改時,我們可以使用推送平臺,給支付系統所有的伺服器推送配置文件更新消息,伺服器收到消息會自動更新配置信息,並給出成功反饋。
六. 粗細管道
黑客攻擊,前端重試等一些原因會造成請求量的暴漲,如果我們的服務被激增的請求給一波打死,想要重新恢復,就是一件非常痛苦和繁瑣的過程。
舉個簡單的例子,我們目前訂單的處理能力是平均10萬下單每秒,峰值14萬下單每秒,如果同一秒鐘有100萬個下單請求進入支付系統,毫無疑問我們的整個支付系統就會崩潰,後續源源不斷的請求會讓我們的服務集群根本啟動不起來,唯一的辦法只能是切斷所有流量,重啟整個集群,再慢慢導入流量。
我們在對外的web伺服器上加一層“粗細管道”,就能很好的解決上面的問題。
下麵是粗細管道簡單的結構圖:
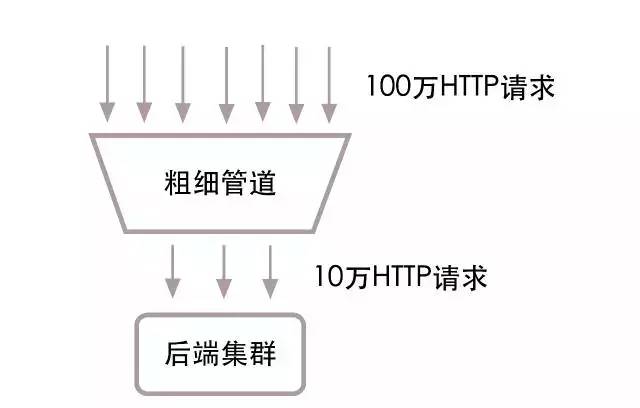
請看上面的結構圖,http請求在進入web集群前,會先經過一層粗細管道。入口端是粗口,我們設置最大能支持100萬請求每秒,多餘的請求會被直接拋棄掉。出口端是細口,我們設置給web集群10萬請求每秒。剩餘的90萬請求會在粗細管道中排隊,等待web集群處理完老的請求後,才會有新的請求從管道中出來,給web集群處理。這樣web集群處理的請求數每秒永遠不會超過10萬,在這個負載下,集群中的各個服務都會高校運轉,整個集群也不會因為暴增的請求而停止服務。
如何實現粗細管道?nginx商業版中已經有了支持,相關資料請搜索nginx max_conns,需要註意的是max_conns是活躍連接數,具體設置除了需要確定最大TPS外,還需確定平均響應時間。
nginx相關:
http://nginx.org/en/docs/http/ngx_http_upstream_module.html


