
Kafka簡介 轉載請註明出處: "http://www.cnblogs.com/BYRans/" Apache Kafka發源於LinkedIn,於2011年成為Apache的孵化項目,隨後於2012年成為Apache的主要項目之一。Kafka使用Scala和Java進行編寫。Apache Kaf ...
Kafka簡介
轉載請註明出處:http://www.cnblogs.com/BYRans/
Apache Kafka發源於LinkedIn,於2011年成為Apache的孵化項目,隨後於2012年成為Apache的主要項目之一。Kafka使用Scala和Java進行編寫。Apache Kafka是一個快速、可擴展的、高吞吐、可容錯的分散式發佈訂閱消息系統。Kafka具有高吞吐量、內置分區、支持數據副本和容錯的特性,適合在大規模消息處理場景中使用。
接下來先介紹下消息系統的基本理念,然後再介紹Kafka。
消息系統介紹
一個消息系統負責將數據從一個應用傳遞到另外一個應用,應用只需關註於數據,無需關註數據在兩個或多個應用間是如何傳遞的。分散式消息傳遞基於可靠的消息隊列,在客戶端應用和消息系統之間非同步傳遞消息。有兩種主要的消息傳遞模式:點對點傳遞模式、發佈-訂閱模式。大部分的消息系統選用發佈-訂閱模式。
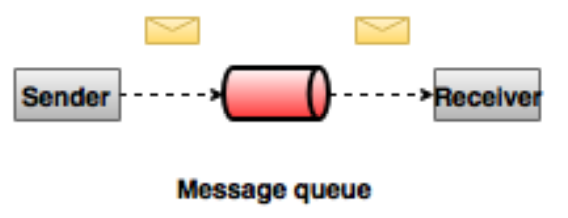
點對點消息系統
在點對點消息系統中,消息持久化到一個隊列中。此時,將有一個或多個消費者消費隊列中的數據。但是一條消息只能被消費一次。當一個消費者消費了隊列中的某條數據之後,該條數據則從消息隊列中刪除。該模式即使有多個消費者同時消費數據,也能保證數據處理的順序。這種架構描述示意圖如下:
發佈-訂閱消息系統
在發佈-訂閱消息系統中,消息被持久化到一個topic中。與點對點消息系統不同的是,消費者可以訂閱一個或多個topic,消費者可以消費該topic中所有的數據,同一條數據可以被多個消費者消費,數據被消費後不會立馬刪除。在發佈-訂閱消息系統中,消息的生產者稱為發佈者,消費者稱為訂閱者。該模式的示例圖如下:

Kafka概述
Apache Kafka是一個分散式的發佈-訂閱消息系統,能夠支撐海量數據的數據傳遞。在離線和實時的消息處理業務系統中,Kafka都有廣泛的應用。Kafka將消息持久化到磁碟中,並對消息創建了備份保證了數據的安全。Kafka在保證了較高的處理速度的同時,又能保證數據處理的低延遲和數據的零丟失。
Kafka的優勢在於:
- 可靠性:Kafka是一個具有分區機制、副本機制和容錯機制的分散式消息系統
- 可擴展性:Kafka消息系統支持集群規模的熱擴展
- 高性能:Kafka在數據發佈和訂閱過程中都能保證數據的高吞吐量。即便在TB級數據存儲的情況下,仍然能保證穩定的性能。
Kafka術語
在深入理解Kafka之前,先介紹一下Kafka中的術語。下圖展示了Kafka的相關術語以及之間的關係:
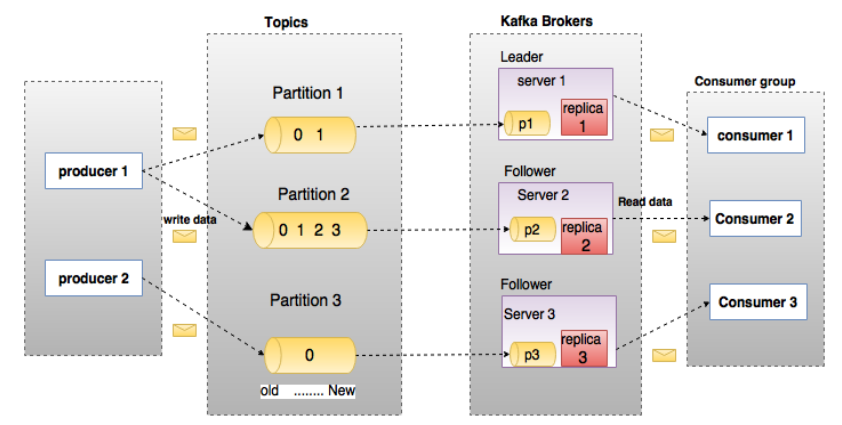
上圖中一個topic配置了3個partition。Partition1有兩個offset:0和1。Partition2有4個offset。Partition3有1個offset。副本的id和副本所在的機器的id恰好相同。
如果一個topic的副本數為3,那麼Kafka將在集群中為每個partition創建3個相同的副本。集群中的每個broker存儲一個或多個partition。多個producer和consumer可同時生產和消費數據。
各個術語的詳細介紹如下:
- Topic:在Kafka中,使用一個類別屬性來劃分數據的所屬類,劃分數據的這個類稱為topic。如果把Kafka看做為一個資料庫,topic可以理解為資料庫中的一張表,topic的名字即為表名。
- Partition:topic中的數據分割為一個或多個partition。每個topic至少有一個partition。每個partition中的數據使用多個segment文件存儲。partition中的數據是有序的,partition間的數據丟失了數據的順序。如果topic有多個partition,消費數據時就不能保證數據的順序。在需要嚴格保證消息的消費順序的場景下,需要將partition數目設為1。
- Partition offset:每條消息都有一個當前Partition下唯一的64位元組的offset,它指明瞭這條消息的起始位置。
- Replicas of partition:副本是一個分區的備份。副本不會被消費者消費,副本只用於防止數據丟失,即消費者不從為follower的partition中消費數據,而是從為leader的partition中讀取數據。
- Broker:
- Kafka 集群包含一個或多個伺服器,伺服器節點稱為broker。
- broker存儲topic的數據。如果某topic有N個partition,集群有N個broker,那麼每個broker存儲該topic的一個partition。
- 如果某topic有N個partition,集群有(N+M)個broker,那麼其中有N個broker存儲該topic的一個partition,剩下的M個broker不存儲該topic的partition數據。
- 如果某topic有N個partition,集群中broker數目少於N個,那麼一個broker存儲該topic的一個或多個partition。在實際生產環境中,儘量避免這種情況的發生,這種情況容易導致Kafka集群數據不均衡。
- Producer:生產者即數據的發佈者,該角色將消息發佈到Kafka的topic中。broker接收到生產者發送的消息後,broker將該消息追加到當前用於追加數據的segment文件中。生產者發送的消息,存儲到一個partition中,生產者也可以指定數據存儲的partition。
- Consumer:消費者可以從broker中讀取數據。消費者可以消費多個topic中的數據。
- Leader:每個partition有多個副本,其中有且僅有一個作為Leader,Leader是當前負責數據的讀寫的partition。
- Follower:Follower跟隨Leader,所有寫請求都通過Leader路由,數據變更會廣播給所有Follower,Follower與Leader保持數據同步。如果Leader失效,則從Follower中選舉出一個新的Leader。當Follower與Leader掛掉、卡住或者同步太慢,leader會把這個follower從“in sync replicas”(ISR)列表中刪除,重新創建一個Follower。
Kafka架構
Kafka的架構示意圖如下:
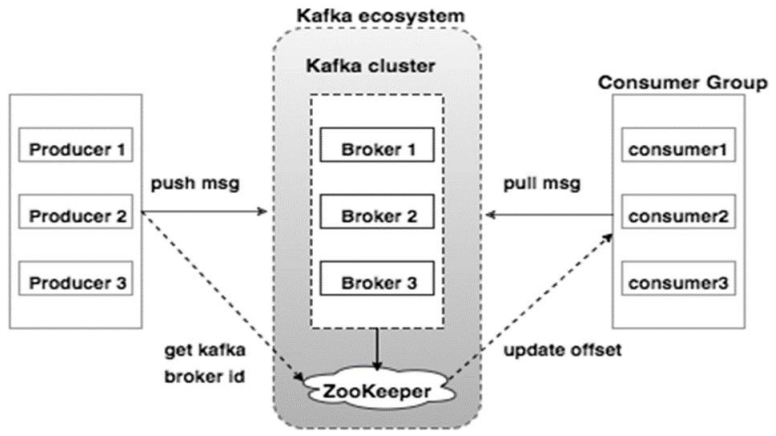
- Broker:Kafka的broker是無狀態的,broker使用Zookeeper維護集群的狀態。Leader的選舉也由Zookeeper負責。
- Zookeeper:Zookeeper負責維護和協調broker。當Kafka系統中新增了broker或者某個broker發生故障失效時,由ZooKeeper通知生產者和消費者。生產者和消費者依據Zookeeper的broker狀態信息與broker協調數據的發佈和訂閱任務。
- Producer:生產者將數據推送到broker上,當集群中出現新的broker時,所有的生產者將會搜尋到這個新的broker,並自動將數據發送到這個broker上。
- Consumer:因為Kafka的broker是無狀態的,所以consumer必須使用partition offset來記錄消費了多少數據。如果一個consumer指定了一個topic的offset,意味著該consumer已經消費了該offset之前的所有數據。consumer可以通過指定offset,從topic的指定位置開始消費數據。consumer的offset存儲在Zookeeper中。
Kafka工作流程
Kafka將某topic的數據存儲到一個或多個partition中。一個partition內數據是有序的,每條數據都有一個唯一的index,這個index叫做offset。新來的數據追加到partition的尾部。每條數據可以在不同的broker上做備份,從而保證了Kafka使用的可靠性。
生產者將消息發送到topic中,消費者可以選擇多種消費方式消費Kafka中的數據。下麵介紹兩種消費方式的流程。
一個消費者訂閱數據:
- 生產者將數據發送到指定topic中
- Kafka將數據以partition的方式存儲到broker上。Kafka支持數據均衡,例如生產者生成了兩條消息,topic有兩個partition,那麼Kafka將在兩個partition上分別存儲一條消息
- 消費者訂閱指定topic的數據
- 當消費者訂閱topic中消息時,Kafka將當前的offset發給消費者,同時將offset存儲到Zookeeper中
- 消費者以特定的間隔(如100ms)向Kafka請求數據
- 當Kafka接收到生產者發送的數據時,Kafka將這些數據推送給消費者
- 消費者受到Kafka推送的數據,併進行處理
- 當消費者處理完該條消息後,消費者向Kafka broker發送一個該消息已被消費的反饋
- 當Kafka接到消費者的反饋後,Kafka更新offset包括Zookeeper中的offset。
- 以上過程一直重覆,直到消費者停止請求數據
- 消費者可以重置offset,從而可以靈活消費存儲在Kafka上的數據
消費者組數據消費流程
Kafka支持消費者組內的多個消費者同時消費一個topic,一個消費者組由具有同一個Group ID的多個消費者組成。具體流程如下:
- 生產者發送數據到指定的topic
- Kafka將數據存儲到broker上的partition中
- 假設現在有一個消費者訂閱了一個topic,topic名字為“test”,消費者的Group ID為“Group1”
- 此時Kafka的處理方式與只有一個消費者的情況一樣
- 當Kafka接收到一個同樣Group ID為“Group1”、消費的topic同樣為“test"的消費者的請求時,Kafka把數據操作模式切換為分享模式,此時數據將在兩個消費者上共用。
- 當消費者的數目超過topic的partition數目時,後來的消費者將消費不到Kafka中的數據。因為在Kafka給每一個消費者消費者至少分配一個partition,一旦partition都被指派給消費者了,新來的消費者將不會再分配partition。即一個partition只能分配給一個消費者,一個消費者可以消費多個partition。
Kafka自帶工具
Kafka tool包在org.apache.Kafka.tools.*下,分為系統工具和複製工具兩類,重點介紹幾個系統工具:
- Kafka Migration Tool:該工具用於將broker的版本從一個版本更新或還原為另一版本。
- Mirror Maker:該工具用於將源Kafka集群的數據鏡像到目的集群。
- Consumer Offset Checker:該工具用於顯示指定topic和消費者組的信息,信息包括:消費者組名、topic名、partition、offset、logSize、owner等。


