
本位出處:http://www.cnblogs.com/wy123/p/6041122.html 經常聽Oracle的同學說起來物化視圖,物化視圖的作用之一就是可以實現查詢重寫,聽起來有一種高大上的感覺, SQL Server也有類似於Oracle物化視圖的功能,只不過叫做索引視圖。 說實話,還是物 ...
本位出處:http://www.cnblogs.com/wy123/p/6041122.html
經常聽Oracle的同學說起來物化視圖,物化視圖的作用之一就是可以實現查詢重寫,聽起來有一種高大上的感覺,
SQL Server也有類似於Oracle物化視圖的功能,只不過叫做索引視圖。
說實話,還是物化視圖聽起來比較合適,與普通視圖比,物化視圖就是直接將數據存儲起來了
SQL Server中的索引視圖也具有查詢重寫的功能,
所謂的查詢重寫,就是如果符合條件的數據在索引視圖上,並且查詢列都包含在在索引視圖上,此時可以直接通過查詢索引視圖來替代基於原始表的查詢
依舊慣例,先上代碼做一個測試環境
--創建兩張表,一張表頭,一張明細,僅僅作為DEMO使用 CREATE TABLE HeadTable ( HeadId INT PRIMARY KEY , HeadInfo VARCHAR(50) , DataStatus TINYINT , CreateDate Datetime ) GO CREATE TABLE DetailTable ( HeadId INT , DetailId INT identity(1,1) PRIMARY KEY , DatailInfo VARCHAR(50) ) GO --寫入數據 DECLARE @i int = 0 WHILE @i<200000 BEGIN INSERT INTO HeadTable values (@i,NEWID(),RAND()*10,GETDATE()-RAND()*100) INSERT INTO DetailTable(HeadId,DatailInfo) VALUES (@i,NEWID()) SET @i=@i+1 END GO
索引視圖創建
那麼如何創建索引視圖呢?語法上跟創建普通視圖差別不大,但是不允許出現select *,表名上要加上Scheme,因為這裡不是專門說索引視圖的,細節就不多說了。
CREATE VIEW V_IndexViewTest WITH SCHEMABINDING AS SELECT H.HeadId,H.CreateDate,H.DataStatus,D.DetailId,D.DatailInfo FROM dbo.HeadTable H INNER JOIN dbo.DetailTable D ON H.HeadId = D.HeadId WHERE H.DataStatus = 0 GO
索引視圖要求創建的第一個列為唯一聚集索引,所以如下,創建一個唯一的聚集索引
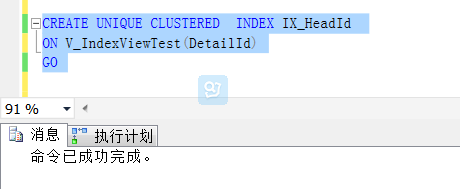
對於其他索引,可以跟在表上創建索引一樣
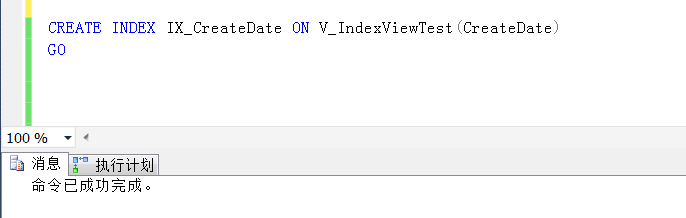
查詢重寫
上面說了,查詢重寫就是將基於原始表的查詢語句,直接在索引視圖上查詢實現,那麼就來看一下查詢重寫是什麼樣子的?
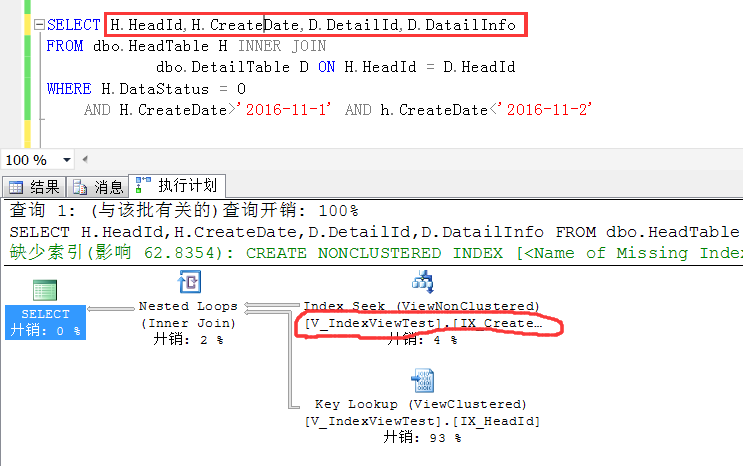
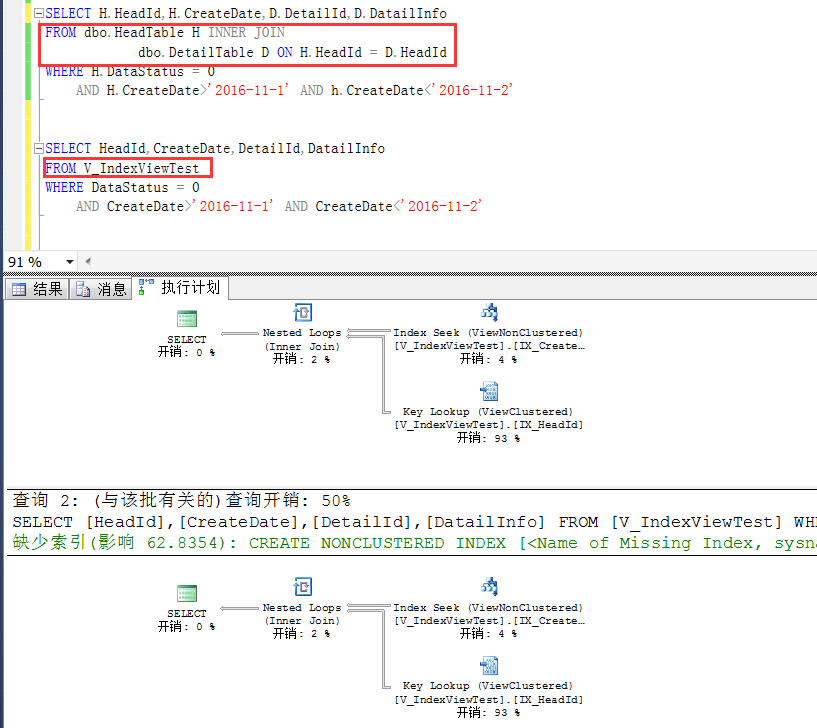
下麵來觀察這麼一個查詢,SQL很明顯地是基於原始表做的查詢,跟普通查詢並無二致,
但是觀察執行計劃就會發現:
這個執行計划走了一個索引查找,首先很清楚,HeadTable上的CreateDate是沒有索引的,這裡走的索引就是V_IndexViewTest上的CreatDate列上的索引
也就是在索引視圖上創建的第二個索引。
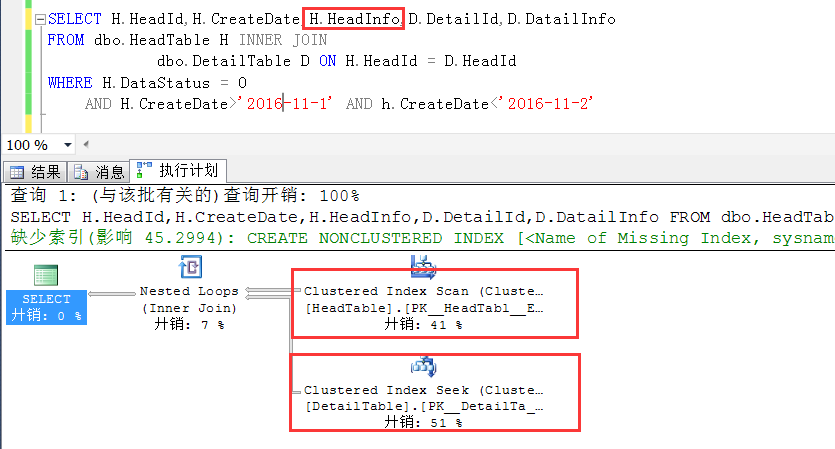
如果,查詢語句這麼寫,如下,在查詢條件中增加了一個索引視圖中沒有的列,此時查詢就不會被重寫,直接走的是基於原始表的查詢,跟普通查詢並無二致。
其實原理不難理解,因為視圖中並不包含HeadInfo這個列,如果在查詢列上加上這個欄位,視圖中是沒有這個欄位的,那隻能基於原始表做查詢了。
為什麼查詢會被重寫
上面我們看到了,對於合適的查詢,查詢是會被重寫的,也就是查詢直接基於索引視圖來實現,那麼為什麼會直接基於視圖來實現呢?
還是處於性能上的考慮,因為索引視圖在創建唯一的聚集索引之後,視圖就“固化了”原始表的結果集,
此時的視圖與普通視圖最大的區別就是,視圖中直接存儲了數據本身,而非一個查詢,
此時的視圖中的數據集,相當於基於原表的一個“子集”,因為是子集,這個結果集必然小於原始表,
那麼同樣的查詢欄位和查詢條件,不但可以減少表與表之間的鏈接操作,且結果集更小,從這個視圖上查詢,
同等條件下可以更快地返回結果,所以查詢重寫也就不難理解了。
此時只要查詢欄位和查詢條件一樣,基於原始表的查詢和直接查詢索引視圖是一樣的,如下截圖
索引視圖什麼時候更新
上面說了查詢重寫,如果條件允許,基於原始表的查詢會直接從索引視圖上來實現。
可能有人會不放心,畢竟數據都是基於物理表做增刪改的,而索引視圖中的數據又是物理存在的,那就就會有一個擔心,基於視圖的查詢會不會不准確?
畢竟是我好好的一個查詢,你預設給我定位到索引視圖上,查詢結果會跟原始表查詢一致嗎?
那麼就要求證一下,索引視圖中的數據是如何更新的。
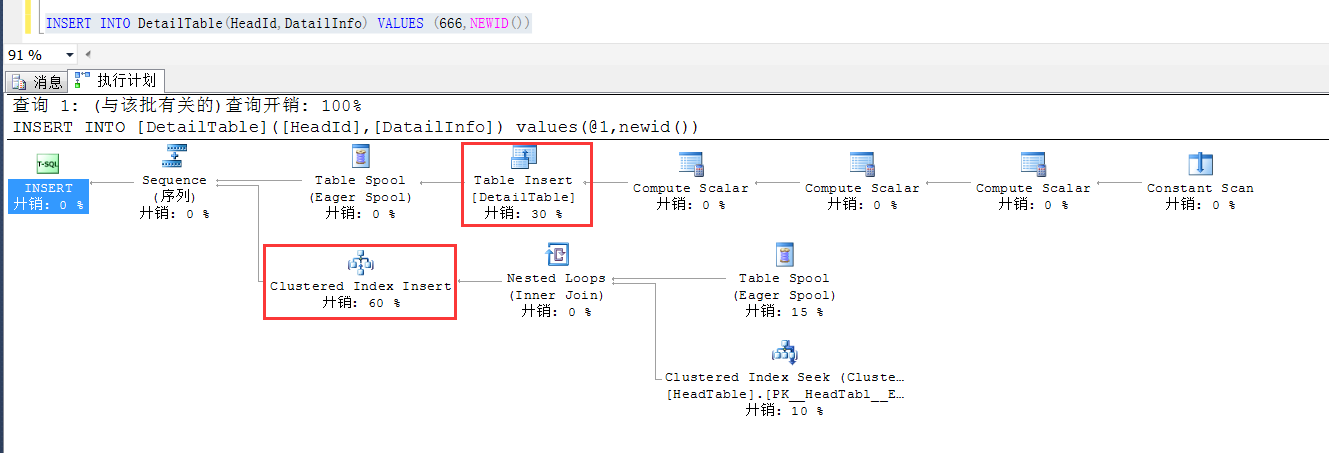
我們做這麼一個測試,在基表,也就是DetailTable中查詢一條數據,看看到底在執行計劃中發生了什麼
可以明顯地看到,不僅僅是王DetailTable中寫入了一條數據,同時,基於索引視圖的查詢也往索引視圖中寫入了一條數據,
因此可以放心地使用索引視圖而不必擔心索引視圖中的數據和基表的數據不一致的問題。
但是要註意的就是,此時的寫,是寫入基表的同事,也寫入了索引視圖,對寫入的影響是肯定有一些的,如果對寫入效率要求非常高,就要謹慎一點了。
其實索引視圖也是一種冗餘寫來實現查詢效率的提高的。
改變基於視圖的查詢
上面說了,某些基於視圖的查詢,是直接定位到視圖,從視圖中查詢結果返回的,如下圖
但是如果真的不想從視圖中查詢,我就是想對比一下原始表和基於視圖查詢的(效率上的)區別,該怎麼辦?
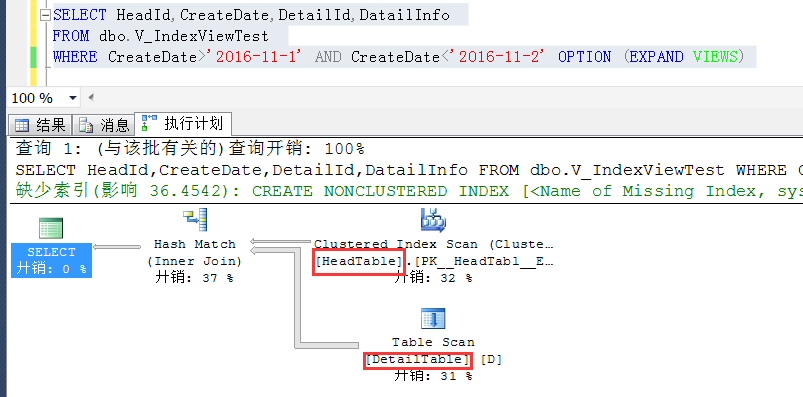
這個也好辦,可以通過查詢提示,將查詢來基於原始表實現,也就是展開這個索引視圖了
OPTION (EXPAND VIEWS)這個查詢提示就是將視圖展開,從原始表進行查詢,預設情況下是不展開的
如截圖,可以強制展開索引視圖,從原始表查詢
那麼效率對比呢?如下截圖,粗看起來,這個效率差別還是挺大的,可見,SQL Server預設選擇下,載效率上還是有一定的考慮的
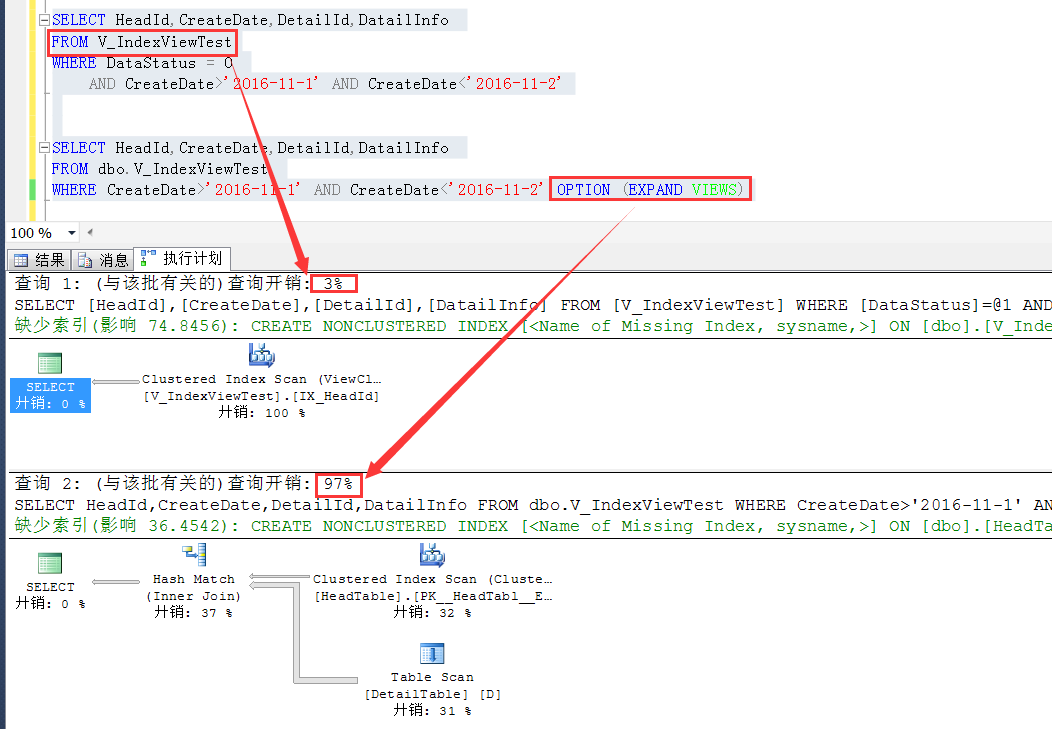
這裡從索引視圖查詢,一是減少了表之間的join,而是索引視圖的結果集更小,從中篩選符合條件的數據效率就會更好一些。
所以,預設情況下是會從視圖查詢來對SQL進行查詢重寫的。
總結:
本位粗淺地分析了SQL Server 中的索引視圖以及索引視圖帶來的查詢重寫功能,通過索引視圖固化基表的結果集,
可以在一定程度上提高查詢效率,尤其是在超級大的多表join的時候,直接將原始結果存為一個索引視圖,
通過對索引視圖查詢來減少表之間的join和IO來提高效率,不失為一種優化選擇。
需要註意的是,SQL Server的索引視圖限制非常多,具體可以參考鏈接叢書或者MSND,並不是所有的情況都可以使用索引視圖來實現。
本人技術水平還很菜,說的不對還請支出,謝謝。


