
談談互聯網後端基礎設施 談談互聯網後端基礎設施 來自:http://chuansong.me/n/717637351233 對於一個互聯網企業,後端服務是必不可少的一個組成部分。拋開業務應用來說,往下的基礎服務設施做到哪些才能夠保證業務的穩定可靠、易維護、高可用呢?縱觀整個互聯網技術體系再結合公司的 ...
談談互聯網後端基礎設施
來自:http://chuansong.me/n/717637351233
對於一個互聯網企業,後端服務是必不可少的一個組成部分。拋開業務應用來說,往下的基礎服務設施做到哪些才能夠保證業務的穩定可靠、易維護、高可用呢?縱觀整個互聯網技術體系再結合公司的目前狀況,個人認為必不可少或者非常關鍵的後端基礎技術/設施如下圖所示:
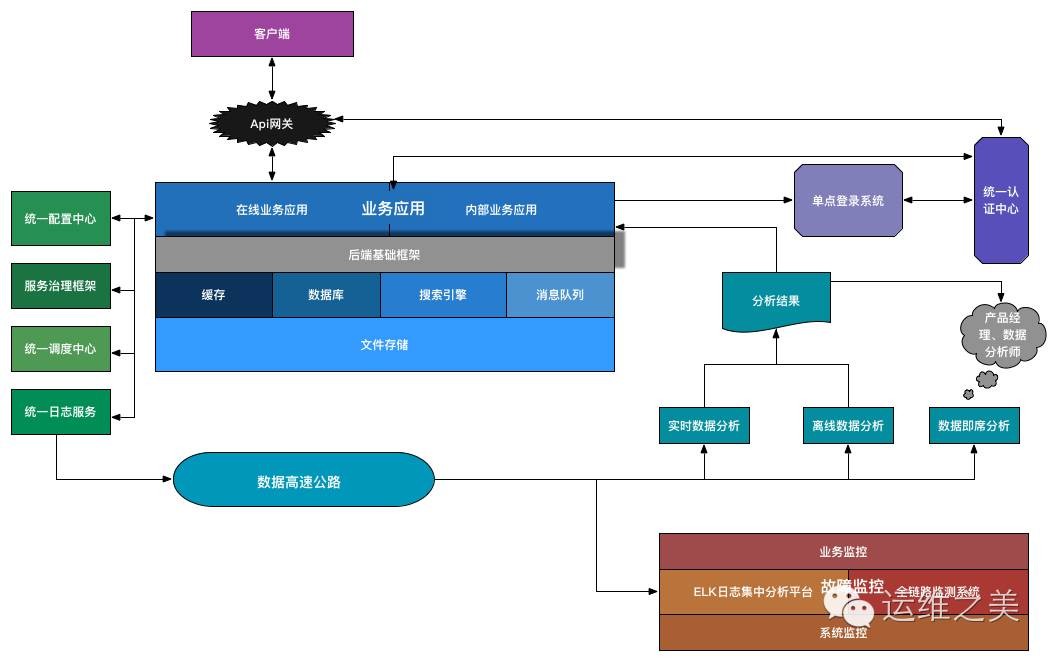
- Api網關
- 業務應用和後端基礎框架
- 緩存、資料庫、搜索引擎、消息隊列
- 文件存儲
- 統一認證中心
- 單點登錄系統
- 統一配置中心
- 服務治理框架
- 統一調度中心
- 統一日誌服務
- 數據基礎設施
- 故障監控
這裡的後端基礎設施主要指的是應用線上上穩定運行需要依賴的關鍵組件/服務等。開發或者搭建好以上的後端基礎設施,一般情況下是能夠支撐很長一段時間內的業務的。此外,對於一個完整的架構來說,還有很多應用感知不到的系統基礎服務,如負載均衡、自動化部署、系統安全等,並沒有包含在本文的描述範圍內。
Api網關
在移動app的開發過程中,通常後端提供的介面需要以下功能的支持:
- 負載均衡
- api訪問許可權控制
- 用戶鑒權
一般的做法,使用nginx做負載均衡,然後在每個業務應用里做api介面的訪問許可權控制和用戶鑒權,更優化一點的方式則是把後兩者做成公共類庫供所有業務調用。但從總體上來看,這三種特性都屬於業務的公共需求,更可取的方式則是集成到一起作為一個服務,既可以動態地修改許可權控制和鑒權機制,也可以減少每個業務集成這些機制的成本。這種服務就是Api網關(http://blog.csdn.net/pzxwhc/article/details/49873623),可以選擇自己實現,也可以使用開源軟體實現,如Kong。如下圖所示:

但是以上方案的一個問題是由於所有api請求都要經過網關,它很容易成為系統的性能瓶頸。因此,可以採取的方案是:去掉api網關,讓業務應用直接對接統一認證中心,在基礎框架層面保證每個api調用都需要先通過統一認證中心的認證,這裡可以採取緩存認證結果的方式避免對統一認證中心產生過大的請求壓力。
業務應用和後端基礎框架
業務應用分為:線上業務應用和內部業務應用。
- 線上業務應用:直接面向互聯網用戶的應用、介面等,典型的特點就是:請求量大、高併發、高可用、對故障的容忍度低。
- 內部業務應用:這個是面向公司內部的應用。比如,內部數據管理平臺、廣告投放平臺等。相比起線上業務應用,其特點: 數據保密性高、壓力小、併發量小、允許故障的發生。
業務應用基於後端的基礎框架開發,針對Java後端來說,應該有的幾個框架如下:
- MVC框架:從十年前流行的Struts1、2到現在最為推崇的SpringMVC、Jersey以及國人開發的JFinal、阿裡的WebX等等,這些框架尤其是後面流行的這些都是各有千秋的。選型的主要因素是看你的團隊是否有一個對某框架能夠做二次開發、定製的人在。很多時候,針對這些通用的框架,你是需要做一些特定的開發才能滿足特定的需求的。比如,很多團隊傳遞參數使用的都是UnderScore的命名法(下劃線連接單詞),但是Java中確是使用LowCamel命名的。對於SpringMVC,可以通過註解的alias來指定,但這樣需要對每一個參數都要指定alias有點效率太低,此外ModelAttribute也不支持別名,更好的方式是在框架層面統一對參數做Camel命名的轉換達到目的。
- IOC框架:ioc帶來的好處無須多言。目前Java中最為流行的Spring自誕生就天然支持IOC。
- ORM框架:MyBatis是目前最為流行的orm框架。此外,Spring ORM中提供的JdbcTemplate也很不錯。當然,對於分庫分表、主從分離這些需求,一般就需要實現自己的ORM框架來支持了,像阿裡的tddl。此外,為了在服務層面統一解決分庫分表、主從分離、主備切換、緩存、故障恢復等問題,很多公司都是有自己的資料庫中間件的,比如阿裡的Cobar、360的Atlas、網易的DDB、開源的MyCat等。
- 緩存框架:緩存框架主要指的是對redis、memcached這些緩存伺服器的操作統一封裝,一般使用Spring的RedisTemplate即可,也可以使用jedis做自己的封裝,支持客戶端分散式方案、主從等。
- JavaEE應用性能檢測框架:對於線上的JavaEE應用,需要有一個統一的框架集成到每一個業務中檢測每一個請求、方法調用、jdbc連接、redis連接等的耗時、狀態等。jwebap是一個可以使用的性能檢測工具,但由於其已經很多年沒有更新,有可能的話建議基於此項目做二次開發。
一般來說,以上幾個框架即可以完成一個後端應用的雛形。
對於這些框架來說,最為關鍵的是根據團隊技術構成選擇最合適的,有能力開發自己的框架則更好。此外,這裡需要提供一個後端應用的模板或生成工具(如maven的archetype)給團隊成員使用,可以讓大家在開發新的應用的時候,迅速的生成雛形應用,而無需再做一些框架搭建的重覆性勞動。
緩存、資料庫、搜索引擎、消息隊列
緩存、資料庫、搜索引擎、消息隊列這四者都是應用依賴的後端基礎服務,他們的性能直接影響到了應用的整體性能,有時候你代碼寫的再好也許就是因為這些服務導致應用性能無法提升上去。
緩存
如緩存五分鐘法則所講:如果一個數據頻繁被訪問,那麼就應該放記憶體中。這裡的緩存就是一種讀寫效率都非常高的存儲方案,能夠應對高併發的訪問請求,通常情況下也不需要持久化的保證。但相對其他存儲來說,緩存一般是基於記憶體的,成本比較昂貴,因此不能濫用。
緩存可以分為:本地緩存和分散式緩存。
- 本地緩存:主要指的是記憶體中的緩存機制。在Java中,Google Guava中就提供了本地緩存的實現機制。當然使用java的ConncurrentHashMap你也可以實現自己的本地緩存方案。
- 分散式緩存:指的單獨的緩存服務。幾年前比較流行的是memcached,但其只是一個KV的存儲,支持的數據結構太少。現在最為流行的就是Redis,能夠支持豐富的數據結構,基於事件驅動的單線程非阻塞IO也能夠應對高併發的場景。集群方案除了官方的redis cluster, 目前比較流行的還有豌豆莢的codis、twitter的twemproxy。
對於緩存的使用,需要註意以下幾點:
- 緩存的失效機制:當給某一個key設置了有效期,那麼緩存何時對此key進行刪除呢?一般來說會有以下幾種方式:
- 守護進程定時去掃描key,找到已經失效的key,然後刪除
- 讀取key的時候先去判斷key是否失效,如果失效則刪除並返回空。
- 緩存的淘汰機制:是當緩存記憶體達到上限時如何刪除緩存中的key。Redis提供了以下數據淘汰策略:
- volatile-lru:從已設置過期時間的數據集中挑選最近最少使用的數據淘汰
- volatile-ttl:從已設置過期時間的數據集中挑選將要過期的數據淘汰
- volatile-random:從已設置過期時間的數據集中任意選擇數據淘汰
- allkeys-lru:從數據集中挑選最近最少使用的數據淘汰
- allkeys-random:從數據集中任意選擇數據淘汰
- no-enviction(驅逐):禁止驅逐數據
對於其具體的實現機制,可以參考《Redis設計與實現》一書
- 緩存的更新機制: 通常來說有四種方式:Cache aside, Read through, Write through, Write behind caching,具體的可見陳皓大神的這篇總結:緩存更新的套路。
- 緩存的服務過載保護:緩存的服務過載指的是由於緩存失效,而引起後端服務的壓力驟增,進一步產生雪崩效應。這個現象和緩存更新是相關的,採取何種策略在緩存失效的時候去更新緩存直接決定了服務過載的保護機制。通常的分為客戶端和服務端的應對方案。前者的方案有:基於超時的簡單模式、基於超時的常規模式、基於刷新的簡單模式、基於刷新的常規模式、基於刷新的續費模式。後者的方案則是很常見的流量控制和服務降級。具體的可以看美團技術團隊總結的這篇文章:Cache應用中的服務過載案例研究。
資料庫
資料庫是後端開發中非常常見的一個服務組件。對於資料庫的選型,要根據業務的特點和數據結構的特點來決定。
從存儲介質上,資料庫可以分為:
- 記憶體資料庫: 數據主要存儲在記憶體中,同時也可以採取措施對數據進行持久化到硬碟中。如Redis、H2DB的記憶體模式。對於這種資料庫,由於記憶體成本昂貴,因此一定要做好存儲的量化分析、容量預估,防止記憶體不足造成服務不可用。
- 硬碟資料庫:數據存儲在硬碟上的這種資料庫是最為常見的。MySQL、Oracle、Postgresql、HBASE、H2DB、SqlLite等等都是硬碟資料庫。此外,SSDB是基於SSD硬碟的KV資料庫,支持的數據介面很豐富,是Redis的另外一個選擇。
從存儲數據類型、數據模式上,資料庫可以分為:
- 關係型資料庫:MySQL、Oracle、Postgresql都是關係型資料庫的,是採用關係模型(關係模型指的就是二維表格模型,而一個關係型資料庫就是由二維表及其之間的聯繫所組成的一個數據組織)來組織數據的資料庫。
- 非關係型資料庫:非關係型資料庫是相對關係型資料庫來講的。以鍵值對存儲,且結構不固定,每一個元組可以有不一樣的欄位,每個元組可以根據需要增加一些自己的鍵值對,這樣就不會局限於固定的結構,可以減少一些時間和空間的開銷。但是,其沒有關係型資料庫那種嚴格的數據模式,並不適合複雜的查詢以及需要強事務管理的業務。非關係型資料庫又可以分為:
- KV資料庫:主要以(key,value)鍵值對存儲數據的資料庫。以Redis、RocksDB(levelDB)、SSDB為代表。
- 文檔資料庫:總體形式上也是鍵值對的形式,但是值裡面又可以有各種數據結構:數組、鍵值對、字元串等等。以mongodb、couchdb為代表。
- 列資料庫:也叫作稀疏大資料庫,一般是用來存儲海量數據的。相對於行資料庫,這種資料庫是以列為單位存儲數據在介質上的。以Hbase、Cassendra為代表。
和資料庫相關的一個很重要的就是資料庫的索引。有一種說法是:“掌握了索引就等於掌握了資料庫”。暫且不去評判此說法是否真的準確,但索引的確關係著資料庫的讀寫性能。需要對資料庫的索引原理做到足夠的瞭解才能更好的使用各種資料庫。通常來說,Mysql、Oracle、Mongodb這些都是使用的B樹作為索引,是考慮到傳統硬碟的特點後兼顧了讀寫性能以及範圍查找需求的選擇,而Hbase用得LSM則是為了提高寫性能對讀性能做了犧牲。
搜索引擎
搜索引擎也是後端應用中一個很關鍵的組件,尤其是對內容類、電商類的應用,通過關鍵詞、關鍵字搜索內容、商品是一個很常見的用戶場景。比較成熟的開源搜索引擎有Solr和Elasticsearch,很多中小型互聯網公司搜索引擎都是基於這兩個開源系統搭建的。它們都是基於Lucence來實現的,不同之處主要在於termIndex的存儲、分散式架構的支持等等。
對於搜索引擎的使用,從系統熟悉、服務搭建、功能定製,需要花費較長時間。在這個過程中,需要註意以下問題:
- 搜索引擎與公司現有數據系統的集成。現有的持久化、供搜索的數據的載體是什麼, 如何讓搜索引擎在全量和增量建索引過程中無縫集成原來的數據載體,才能發揮搜索引擎自身的實時性, 水平擴展性(性能與容量和機器數量成正比)等優勢。
- 和資料庫一樣,對搜索引擎的索引機制也需要做到深入的瞭解。
更為詳細的對於搜索引擎的工程化實踐可以參考有贊工程師的這篇文章:有贊搜索引擎實踐(工程篇)
另外,搜索引擎還可以用在數據的多維分析上,就是GrowingIO、MixPanel中的可以任意維度查詢數據報表的功能。當然,druid也許是一個更好的實現多維分析的方案,官方也有其與es的比較:http://t.cn/RcGFIxn。
消息隊列
軟體的組織結構,從開始的面向組件到SOA、SAAS是一個逐漸演變的過程。而到了今天微服務盛行的時代,你都不好意思說自己的系統只是單一的一個系統而沒有解耦成一個個service。當然,小的系統的確沒有拆分的必要性,但一個複雜的系統拆成一個個service做微服務架構確實是不得不做的事情。
那麼問題就來了,service之間的通信如何來做呢?使用什麼協議?通過什麼方式調用?都是需要考慮的問題。
先拋開協議不談,service之間的調用方式可以分為同步調用以及非同步調用。同步調用的方式無需多說,那麼非同步調用是怎麼進行的呢?一種很常見的方式就是使用消息隊列,調用方把請求放到隊列中即可返回,然後等待服務提供方去隊列中去獲取請求進行處理,然後把結果返回給調用方即可(可以通過回調)。
非同步調用就是消息中間件一個非常常見的應用場景。此外,消息隊列的應用場景還有以下:
- 解耦:一個事務,只關心核心的流程,需要依賴其他系統但不那麼重要的事情,有通知即可,無須等待結果。
- 最終一致性:指的是兩個系統的狀態保持一致,要麼都成功,要麼都失敗,可以有一定的延遲,只要最終達到一致性即可。
- 廣播:這是消息隊列最基本的功能。生產者只需要發佈消息,無須關心有哪些訂閱者來消費消息。
- 錯峰與流控:當上下游系統處理能力不同的時候就需要類似消息隊列的方式做為緩衝區來隔開兩個系統。
目前主流的消息隊列軟體,主要有以下幾種:
- ActiveMQ:Java中最為簡單的消息隊列,是對JMS的實現,沒有規定消息的順序、安全、重發等特性。
- RabbitMQ:是對AMQP協議的實現,對於消息的順序性、安全、重發等都做了很好的支持。比較適合不允許數據丟失、有事務需求的業務場景下的消息傳輸。
- Kafka:是基於Log的消息隊列,底層依賴於文件的順序讀取,是append-only的。適合對數據丟失不敏感、強調性能的一些海量日誌傳輸場景中。是最近幾年大數據領域很火的一個技術。
- ZeroMQ:是一個網路編程的Pattern庫,將常見的網路請求形式(分組管理,鏈接管理,發佈訂閱等)模式化、組件化,簡而言之socket之上、MQ之下。對於MQ來說,網路傳輸只是它的一部分,更多需要處理的是消息存儲、路由、Broker服務發現和查找、事務、消費模式(ack、重投等)、集群服務等。
文件存儲
不管是業務應用、依賴的後端服務還是其他的各種服務,最終還是要依賴於底層文件存儲的。通常來說,文件存儲需要滿足的特性有:可靠性、容災性、穩定性,即要保證存儲的數據不會輕易丟失,即使發生故障也能夠有回滾方案,也要保證高可用率。在底層可以採用傳統的RAID作為解決方案,再上一層,目前hadoop的hdfs則是最為普遍的分散式文件存儲方案,當然還有NFS、Samba這種共用文件系統也提供了簡單的分散式存儲的特性。
此外,如果文件存儲確實成為了應用的瓶頸或者必須提高文件存儲的性能從而提升整個系統的性能時,那麼最為直接和簡單的做法就是拋棄傳統機械硬碟,用SSD硬碟替代。像現在很多公司在解決業務性能問題的時候,最終的關鍵點往往就是SSD。這也是用錢換取時間和人力成本最直接和最有效的方式。在資料庫部分描述的SSDB就是對LevelDB封裝之後,利用SSDB的特性的一種高性能KV資料庫。
至於HDFS,如果要使用上面的數據,是需要通過hadoop的。類似xx on yarn的一些技術就是將非hadoop技術跑在hdfs上的解決方案(當然也是為了使用MR)。
統一認證中心
統一認證中心,主要是對app用戶、內部用戶、app等的認證服務,包括
- 用戶的註冊、登錄驗證、token鑒權
- 內部信息系統用戶的管理和登錄鑒權
- App的管理,包括app的secret生成,app信息的驗證(如驗證介面簽名)等。
之所以需要統一認證中心,就是為了能夠集中對這些所有app都會用到的信息進行管理,也給所有應用提供統一的認證服務。尤其是在有很多業務需要共用用戶數據的時候,構建一個統一認證中心是非常必要的。此外,通過統一認證中心構建移動app的單點登錄也是水到渠成的事情(模仿web的機制,將認證後的信息加密存儲到本地磁碟中供多個app使用)。
單點登錄系統
目前很多大的線上web網站都是有單點登錄系統的,通俗的來說就是只需要一次用戶登錄,就能夠進入多個業務應用(許可權可以不相同),非常方便用戶的操作。而在移動互聯網公司中,內部的各種管理、信息系統同樣也需要單點登錄系統。目前,比較成熟的、用的最多的單點登錄系統應該是耶魯大學開源的CAS, 可以基於https://github.com/apereo/cas/tree/master/cas-server-webapp來定製開發的。此外,國人開源的kisso的這個也不錯。基本上,單點登錄的原理都類似下圖所示:
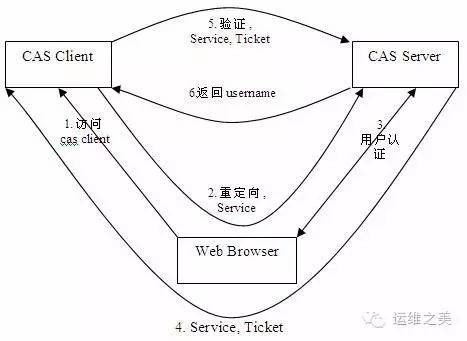
統一配置中心
在Java後端應用中,一種讀寫配置比較通用的方式就是將配置文件寫在propeties、yaml、HCON文件中,修改的時候只需要更新文件重新部署即可,可以做到不牽扯代碼層面改動的目的。統一配置中心,則是基於這種方式之上的統一對所有業務或者基礎後端服務的相關配置文件進行管理的統一服務, 具有以下特性:
- 能夠線上動態修改配置文件並生效
- 配置文件可以區分環境(開發、測試、生產等)
- 使用方便: 在java中可以通過註解、xml配置的方式引入相關配置
disconf是可以在生產環境使用的一個方案,也可能根據自己的需求開發自己的配置中心(可以選擇zookeeper作為配置存儲)。
服務治理框架
對於外部API調用或者客戶端對後端api的訪問,可以使用http協議或者說restful(當然也可以直接通過最原始的socket來調用)。但對於內部服務間的調用,一般都是通過RPC機制來調用的。目前主流的RPC協議有:
- RMI
- Hessian
- Thrift
- Dubbo
這些RPC協議各有優劣點,需要針對業務需求做出相應的最好的選擇。
這樣,當你的系統服務在逐漸增多,RPC調用鏈越來越複雜,很多情況下,需要不停的更新文檔來維護這些調用關係。一個對這些服務進行管理的框架可以大大節省因此帶來的繁瑣的人力工作。
傳統的ESB(企業服務匯流排)本質就是一個服務治理方案,但esb作為一種proxy的角色存在於client和server之間,所有請求都需要經過esb,使得esb很容易成為性能瓶頸。因此,基於傳統的esb,更好的一種設計如下圖所示:
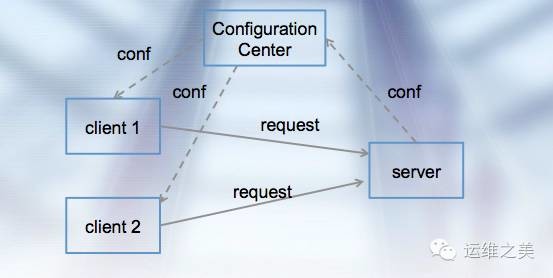
如圖,以配置中心為樞紐,調用關係只存在於client和提供服務的server之間,就避免了傳統esb的性能瓶頸問題。對於這種設計,esb應該支持的特性如下:
- 服務提供方的註冊、管理
- 服務消費者的註冊、管理
- 服務的版本管理、負載均衡、流量控制、服務降級等
- 服務的容錯、熔斷等
阿裡開源的dubbo則對以上做了很好的實現,也是目前很多公司都在使用的方案。但由於某些原因,dubbo現已不再維護,推薦大家使用噹噹後來維護的dubbox。
統一調度中心
在很多業務中,定時調度是一個非常普遍的場景,比如定時去抓取數據、定時刷新訂單的狀態等。通常的做法就是針對各自的業務依賴Linux的cron機制或者java中的quartz。統一調度中心則是對所有的調度任務進行管理,這樣能夠統一對調度集群進行調優、擴展、任務管理等。azkaban和oozie是hadoop的流式工作管理引擎,也可以作為統一調度中心來使用。當然,你也可以使用cron或者quartz來實現自己的統一調度中心。
- 根據cron表達式調度任務
- 動態修改、停止、刪除任務
- 支持任務工作流:比如一個任務完成之後再執行下一個任務
- 任務支持腳本、代碼、url等多種形式
- 任務執行的日誌記錄、故障報警
對於Java的quartz這裡需要說明一下:這個quartz需要和spring quartz區分,後者是spring對quartz框架的簡單實現也是目前使用的最多的一種調度方式。但是,其並沒有做高可用集群的支持。而quartz雖然有集群的支持,但是配置起來非常複雜。現在很多方案都是使用zookeeper來實現spring quartz集群的。這裡有一個國人開源的uncode-shcedule對此實現的還不錯,可以根據自己的業務需求做二次開發。
統一日誌服務
日誌是開發過程必不可少的東西。有時候,列印日誌的時機、技巧是很能體現出工程師編碼水平的。畢竟,日誌是線上服務能夠定位、排查異常最為直接的信息。
通常的,將日誌分散在各個業務中非常不方便對問題的管理和排查。統一日誌服務則使用單獨的日誌伺服器記錄日誌,各個業務通過統一的日誌框架將日誌輸出到日誌伺服器上。
可以通過實現log4j後者logback的appender來實現統一日誌框架,然後通過RPC調用將日誌列印到日誌伺服器上。
數據基礎設施
數據是最近幾年非常火的一個領域。從《精益數據分析》到《增長黑客》,都是在強調數據的非凡作用。很多公司也都在通過數據推動產品設計、市場運營、研發等。詳細的可見之前的一篇《數據雜談》,對數據相關的東西做過一些總結。這裡需要說明的一點是,只有當你的數據規模真的到了單機無法處理的規模才應該上大數據相關技術,千萬不要為了大數據而大數據。很多情況下使用單機程式+mysql就能解決的問題非得上hadoop即浪費時間又浪費人力。
這裡需要補充一點的是,對於很多公司,尤其是離線業務並沒有那麼密集的公司,在很多情況下大數據集群的資源是被浪費的。因此誕生了xx on yarn一系列技術讓非hadoop系的技術可以利用大數據集群的資源,能夠大大提高資源的利用率,如Docker on yarn(Hulu的VoidBox)。
數據高速公路
接著上面講的統一日誌服務,其輸出的日誌最終是變成數據到數據高速公路上供後續的數據處理程式消費的。這中間的過程包括日誌的收集、傳輸。
- 收集:統一日誌服務將日誌列印在日誌服務上之後,需要日誌收集機制將其集中起來。目前,常見的日誌收集方案有:scribe、Chukwa、Kakfa和Flume。對比如下圖所示:
- 傳輸:通過消息隊列將數據傳輸到數據處理服務中。對於日誌來說,通常選擇kafka這種消息隊列即可。
此外,這裡還有一個關鍵的技術就是資料庫和數據倉庫間的數據同步問題,即將需要分析的數據從資料庫中同步到諸如hive這種數據倉庫時使用的方案。比較簡單的、用的也比較多的可以使用sqoop進行基於時間戳的數據同步,此外,阿裡開源的canal實現了基於binlog增量同步,更加適合通用的同步場景,但是基於canal你還是需要做不少的業務開發工作的。推薦另一款國人開源的MySQL-Binlog,原理和canal類似,預設提供了任務的後臺管理功能,只需要實現接收到binlog後的處理邏輯即可。
離線數據分析
離線數據分析是可以有延遲的,一般針對是非實時需求的數據分析工作,產生的也是T-1的報表。目前最常用的離線數據分析技術除了hadoop還有spark。相比hadoop,spark性能上有很大優勢,當然對硬體資源要求也高。
對於hadoop,傳統的MR編寫很複雜,也不利於維護,可以選擇使用hive來用sql替代編寫mr,但是前提務必要對hive的原理做到瞭解。可以參見美團的這篇博文來學習:Hive SQL的編譯過程。而對於spark,也有類似hive的spark sql。
此外,對於離線數據分析,還有一個很關鍵的就是數據傾斜問題。所謂數據傾斜指的是region數據分佈不均,造成有的結點負載很低,而有些卻負載很高,從而影響整體的性能。因此,處理好數據傾斜問題對於數據處理是很關鍵的。對於hive的數據傾斜,可見:hive大數據傾斜總結。對於spark的傾斜問題,可見:Spark性能優化指南——高級篇。
實時數據分析
相對於離線數據分析,實時數據分析也叫線上數據分析,針對的是對數據有實時要求的業務場景,如廣告結算、訂單結算等。目前,比較成熟的實時技術有storm和spark streaming。相比起storm,spark streaming其實本質上還是基於批量計算的。如果是對延遲很敏感的場景,還是應該使用storm。
對於實時數據分析,需要註意的就是實時數據處理結果寫入存儲的時候,要考慮併發的問題,雖然對於storm的bolt程式來說不會有併發的問題,但是寫入的存儲介質是會面臨多任務同時讀寫的。通常採用的方案就是採用時間視窗的方式對數據做緩衝後批量寫入。
此外,實時數據處理一般情況下都是基於增量處理的,相對於離線來說並非可靠的,一旦出現故障(如集群崩潰)或者數據處理失敗,是很難對數據恢復或者修複異常數據的。因此結合離線+實時是目前最普遍採用的數據處理方案。Lambda架構就是一個結合離線和實時數據處理的架構方案。
數據即席分析
離線和實時數據分析產生的一些報表是給數據分析師、產品經理參考使用的,但是很多情況下,線上的程式並不能滿足這些需求方的需求。這時候就需要需求方自己對數據倉庫進行查詢統計。針對這些需求方,SQL上手容易、易描述等特點決定了其可能是一個最為合適的方式。因此提供一個SQL的即席查詢工具能夠大大提高數據分析師、產品經理的工作效率。Presto、Impala、Hive都是這種工具。如果想進一步提供給需求方更加直觀的ui操作界面,可以搭建內部的Hue。
故障監控
對於面向用戶的線上服務,發生故障是一件很嚴重的事情。因此,做好線上服務的故障檢測告警是一件非常重要的事情。可以將故障監控分為以下兩個層面的監控:
- 系統監控:主要指的對主機的帶寬、cpu、記憶體、硬碟、io等硬體資源的監控。這可以使用開源的nagios、cacti等開源軟體進行監控。目前,市面上也有很多第三方服務能夠提供對於主機資源的監控,如監控寶等。對於分散式服務集群(如hadoop、storm、kafka、flume等集群)的監控則可以使用ganglia。此外,小米開源的OpenFalcon也很不錯,涵蓋了系統監控、JVM監控等,也支持自定義的監控機制。
- 業務監控:是在主機資源層面以上的監控,比如app的pv、uv數據異常、交易失敗等。需要業務中加入相關的監控代碼,比如在異常拋出的地方,加一段日誌記錄。
監控還有一個關鍵的步驟就是告警。告警的方式有很多種:郵件、im、簡訊等。考慮到故障的重要性不同、告警的合理性、便於定位問題等因素,有以下建議:
- 告警日誌要記錄發生故障的機器id,尤其是在集群服務中,如果沒有記錄機器id,那麼對於後續的問題定位會很困難。
- 要對告警做聚合,不要每一個故障都單獨進行告警,這樣會對工程師造成極大的困擾。
- 要對告警做等級劃分,不能對所有告警都做同樣的優先順序處理。
- 使用微信做為告警軟體,能夠在節省簡訊成本的情況下,保證告警的到達率。
故障告警之後,那麼最最關鍵的就是應對了。對於創業公司來說,24小時待命是必備的素質,當遇到告警的時候,需要儘快對故障做出反應,找到問題所在,並能在可控時間內解決問題。對於故障問題的排查,基本上都是依賴於日誌的。只要日誌打的合理,一般情況下是能夠很快定位到問題所在的,但是如果是分散式服務,並且日誌數據量特別大的情況下,如何定位日誌就成為了難題。這裡有幾個方案:
- 建立ELK(Elastic+Logstash+Kibana)日誌集中分析平臺,便於快速搜索、定位日誌。對於ELK的介紹,可以見:使用Elasticsearch + Logstash + Kibana搭建日誌集中分析平臺實踐
- 建立分散式請求追蹤系統(也可以叫全鏈路監測系統),對於分散式系統尤其是微服務架構,能夠極大的方便在海量調用中快速定位並收集單個異常請求信息,也能快速定位一條請求鏈路的性能瓶頸。Google的Dapper、唯品會的Mercury、阿裡的鷹眼、新浪的WatchMan都是類似的思路。此外,騰訊的染色日誌機制本質上也是在鏈路追蹤之上根據響應信息做了染色機制。


